[논문 리뷰] SEAKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation
Abstract
Adaptive Retrieval-Augmented Generation (RAG)는 LLMs의 환각 문제를 완화하는 핵심 전략입니다.
RAG는 외부 지식이 필요한지 동적으로 결정하고, 필요한 경우 검색을 수행합니다.
본 논문은 Self-aware Knowledge Retrieval (SEAKR)를 제안합니다.
SEAKR는 높은 자기 불확실성을 보일 때 검색을 활성화하는 기법입니다.
SEAKR는 LLM의 자기 인식 불확실성에 기반하여 검색된 지식 snippet을 재순위화하여 불확실성을 최대한 줄이는 snippet을 보존합니다.
복잡한 작업을 해결하기 위해 여러 번의 검색이 필요한 경우, SEAKR는 자가 인식 불확실성을 이용하여 다른 추론 전략 중에서 선택합니다.
어렵거나 쉬운 모든 질문에 대해 SEAKR은 기존의 Adaptive RAG 방법보다 우수한 성능을 보였습니다.
Introduction
RAG란 LLM의 외부 지식을 검색하여 통합하는 방식입니다.
이는 LLM이 사실과 다른 답변을 하는 환각 문제를 해결하는데 유망한 전략입니다.
기존의 RAG 방법은 모든 입력 쿼리에 대해 지식을 검색하지만 이는 LLM이 자체 지식을 통해 정확한 답을 추출할 수 있는 경우 매우 비효율적입니다.
이러한 문제를 해결하기 위해 Adaptive RAG가 제안되고 이는 외부 지식을 필요로 하는지 동적으로 결정하고 검색 단계를 호출하게 됩니다.
최근 연구에 따르면 LLM은 생성된 내용에 대한 불확실성을 내부 상태에서 인식할 수 있고, 본 논문은 LLM의 내부 상태에서 추출된 자기 인식 불확실성을 이용하여 검색 시점을 결정하고 검색된 지식을 효과적으로 통합하는 SEAKR를 제안합니다.
two major factors
- When to retrieve knowledge
1.1 검색 시점 결정: LLM의 출력을 기반으로 검색 시점을 결정하는 기존 방법과 다르게 LLM의 내부 상태에서 자기 인식 불확실성을 추출하여 검색 시점을 정확하게 결정합니다.
1.2 불확실성 추출: LLM의 FFN에서 마지막 생성된 토큰에 해당하는 각 레이어의 내부 상태에서 불확실성을 추출합니다.
1.3 불확실성 점수 계산: 동일한 프롬프트에 대해 여러 세대에 걸쳐 일관성 측정을 수행하여 LLM의 자기 인식 불확실성 점수를 계산하고 이를 검색 결정 및 지식 통합에 사용합니다. - How to integrate retrieved knowledge
2.1 자기 인식 재순위화: SEAKR는 여러 검색된 snippet을 읽고 불확실성을 가장 많이 줄이는 지식을 선택하여 context에 통합합니다.
2.2 자기 인식 추론: 복잡한 질문에 대한 답변을 위해 여러 지식을 수집하는 반복적인 지식 검색을 지원합니다. 다양한 추론 전략을 사용하여 지식을 통합하고 가장 낮은 불확실성을 나타내는 전략을 선택합니다.
Related Work
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG)는 지식 검색을 위한 검색 엔진과 답변 생성위한 LLM으로 구성됩니다.
사용자가 질문을 던지면 RAG는 검색 엔진을 사용하여 관련 지식 스니펫을 검색하고 기계독해를 통해 답변을 생성합니다.
Adaptive RAG는 검색된 지식이 필요한지 여부를 동적으로 결정하여 부정확하게 검색된 정보의 부정적 영향을 줄입니다.
LLM이 낮은 확률의 토큰을 출력할 때 검색 엔진을 확성화합니다.
Adaptive RAG는 기존 RAG의 시스템을 많이 보완하였지만 두 가지 문제에 직면합니다.
- 단순히 LLM의 출력으로 검색 결정을 내리는 것은 매우 피상적(겉만 보고 판단)인 결정입니다. LLM은 환각의 문제도 있으며 지식을 정확하게 대변하고 있다고 보기 어렵기 때문입니다.
- 여러 검색된 지식을 재정렬하고 추론 경로를 최적화하는 것으로 대변할 수 있다는 점도 문제점입니다.
Self-awareness in Internal States of LLMs
트랜스포머 디코더 스택으로 구성된 LLM의 hidden state는 LLM의 내부 상태에 대한 중요한 정보를 포함하고 있음을 여러 논문이 보여주었습니다.
hidden state의 자기 인식을 통해 adaptive RAG를 개선할 가능성을 제시합니다.
디코딩이 연속적으로 진행될 때 이산적인 토큰으로 분해하기 때문에 정보 소실이 불가피하고,
이에 따라 출력 수준의 자기 인식 탐지에 비해 hidden state 탐지가 adaptive RAG에 더 적합합니다.
Self-Aware Knowledge Retrieval
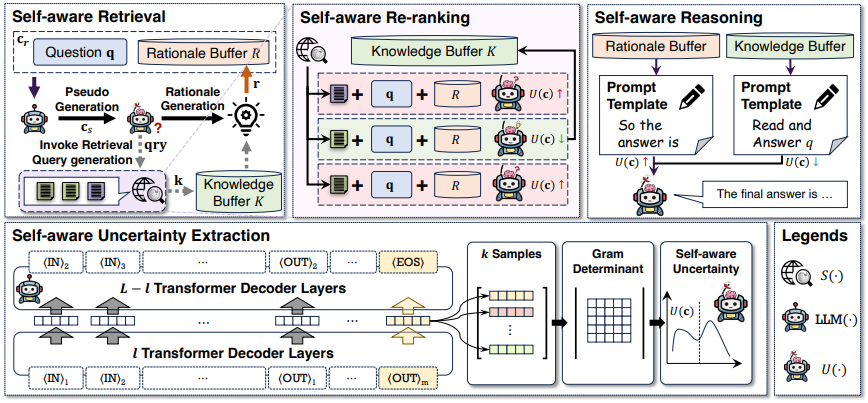
위의 이미지에서 확인할 수 있는 것처럼 SEAKR는 3가지 주요 구성 요소로 이루어져 있습니다.
- 검색 쿼리와 관련성에 따라 순위가 매겨진 지식 snippet을 반환하는 검색 엔진.
- 컨텍스트 c를 입력으로 받아 컨텍스트의 계속되는 출력을 생성하는 LLM.
- LLM이 입력 컨텍스트 c에 대해 생성할 때의 불확실성을 정량화하는 self-aware uncertainty estimator(U(·),자기 인식 불확실성 추정기).
Self-aware Retrieval
Self-aware Retrieval는 U(·)에 의존하여 검색된 지식을 근거 생성을 위해 사용할지 결정합니다.
Input Context:
LLM이 검색 없이 한 단계의 논리를 생성하도록 유도하고 U(·)를 사용하여 LLM이 불확실한지 여부를 검사하여 적절히 검색을 호출합니다.
U(cr) > δ를 초과하면 검색이 트리거가 동작합니다. (경험적 임계값)
Query Generation:
검색 엔진을 위한 쿼리를 생성하기 위해 LLM은 pseudo generation을 실행합니다(rs = LLM(cr)).
낮은 확률로 인해 높은 불확실성을 나타내는 r의 토큰을 식별하고 이러한 토큰을 의사 생성된 논리에서 제거하여 검색 쿼리를 형성합니다.
검색된 지식은 rs에서 불확실한 토큰을 채우기 위해 직접적으로 정보를 제공할 것으로 기대할 수 있습니다.
Rationale Generation:
SEAKR는 질문 q에 대한 답변을 진행하기 위해 논리를 생성합니다.
검색이 호출되면 지식 스니펫 k가 현재 입력 컨텍스트 cr에 추가됩니다.
그렇지 않으면 입력 컨텍스트는 변경되지 않습니다.
생성된 논리 r = LLM(c)는 논리 버퍼에 추가됩니다.
Self-aware Re-ranking
기존 RAG는 제시된 쿼리와의 연관성에 따라 검색된 지식의 순위를 매깁니다.
기존 방법과 달리, SEAKR는 LLM의 자기 인식 불확실성을 줄이는 데 있어 검색된 지식의 유용성을 우선시합니다.
검색 엔진이 상위 N개의 다양한 지식 스니펫을 호출함에 따라, SEAKR는 N개의 입력 컨텍스트를 생성하고 LLM에서 해당하는 자기 인식 불확실성을 평가합니다.
U(·)에 의해 평가된 불확실성이 가장 낮은 지식 조각이 선택됩니다.
Self-aware Reasoning
SEAKR 시스템 내의 검색 프로세스는 두 가지 조건에서 중지됩니다.
- LLM이 "So the final answer is"라는 Prompt로 생성을 종료할 때
- 검색 활동이 최대 한도에 도달할 때
SEAKR는 두 가지 다른 추론 전략을 사용합니다.
- 생성된 논리를 사용한 추론: LLM이 최종 답변을 직접 생성하도록 유도하고 마지막으로 생성된 논리 뒤에 "So the final answer is"라는 prompt를 배치
- 검색된 지식을 사용한 추론: 모든 재순위된 검색 지식을 질문 앞에 추가하여 참조 컨텍스트로 사용합니다.
Self-aware Uncertainty Estimator
입력 컨텍스트 c = ⟨IN⟩1 · · · ⟨IN⟩n에는 n개의 토큰이 있으며, LLM은 입력 컨텍스트에 조건화된 확률 분포로 작동합니다.
생성을 위한 디코더는 m개의 토큰과 ⟨EOS⟩ 토큰으로 끝나는 출력을 생성합니다, (LLM(c) = ⟨OUT⟩1 · · · ⟨OUT⟩m⟨EOS⟩).
⟨EOS⟩ 토큰의 히든 공간에서 불확실성을 측정합니다.
H(l)⟨EOS⟩는 모든 이전 토큰에 주의를 기울이기 때문에 출력과 입력에 대한 정보를 압축합니다.
그런 다음, H(l)⟨EOS⟩를 랜덤 변수로 취급하고, 동일한 입력 컨텍스트에 대해 LLM에서 k개의 다른 생성을 샘플링하며, 해당 H(l)⟨EOS⟩를 사용하여 Gram 행렬을 계산합니다
각 표현 쌍 간의 상관관계를 측정합니다.
마지막으로, LLM의 불확실성은 정규화된 Gram 행렬의 행렬식으로 평가됩니다.
위와 같은 이유로 평가가 가능한 이유는 2가지가 있습니다
- LLM은 매우 훈련이 잘 되어 있는 모델이기 때문에 잘못된 내용을 생성할 때 덜 일관적으로 행동합니다.
- Gram 행렬식은 동일한 의미를 다른 방식으로 표현할 수 있는 자연어의 영향을 받지 않고, 내부 상태 수준에서 일관성을 검사할 수 있습니다.
Experiments
비 적응형 RAG
Chain-of-Thought (CoT) (Wei et al., 2022)
IRCoT (Trivedi et al., 2022)
적응형 RAG
Self-RAG (Asai et al., 2023)
FLARE (Jiang et al., 2023)
DRAGIN (Su et al., 2024)
SEAKR를 구현하기 위해 LLaMA-2-chat-70B를 backbone LLM으로 사용합니다.
Experiments Results
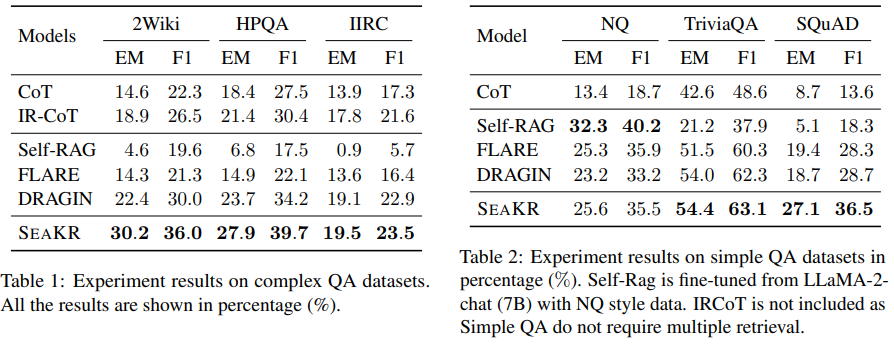
F1 measure와 exact match (EM) score를 사용하여 평가를 진행한다.
복잡한 QA, 간단한 QA에서 높은 성능을 보여주였습니다 .

질문 (HPQA): "Alejandro Jodorowsky와 Philip Saville 중 누가 더 오래 살았는가?
정답: Alejandro Jodorowsky
Knowledge Buffer: Philip Saville에 대한 기본 정보가 제공됩니다. 그는 1930년 10월 28일에 태어나 2016년 12월 22일에 사망했습니다.
Rationale Buffer: 추가적으로 Philip Saville의 생년월일과 사망일이 다시 언급됩니다.
Pseudo-Generation: Alejandro Jodorowsky의 생년월일을 1929년 7월 7일로 추정합니다.
Self-aware Uncertainty: U(c) = -4.4로 자가 인식 불확실성 값을 나타냅니다.
Retrieved Knowledge Ranked by Search Engine
첫 번째 결과는 인터뷰 내용으로, Alejandro Jodorowsky가 2009년에 영화 "King Shot"을 위한 자금을 찾지 못했다는 내용을 포함하고 있습니다. (-4.37)
두 번째 결과는 Alejandro Jodorowsky의 출생일이 1929년 2월 17일로 나와 있습니다. (-4.91).
세 번째 결과도 같은 출생일(1929년 2월 17일)을 포함하고 있습니다.(-4.88)
자기 불확실성 점수는 낮을 수록 불확실성이 낮아집니다.(믿을 만한 정보)
즉 pseudo-generation으로 얻은 -4.4는 논문에서 정한 -6 역치보다 높은 정보로 검색을 수행하게되고
검색을 수행했을 때 불확실성이 낮은 -4.91에 해당되는 것을 논리로 선정하여 대답하게 됩니다.
