느낀점
- 실제 LLM application에서 BERT를 활용해야 할 일이 많아 효과가 기대됨
- 다국어가 아닌 영어로만 학습하여 한국어로 학습한 모델 출시가 기대됨
- 패딩이 효율성과 성능을 감소 시키는 것으로 체감적으로 이해하고 있었는데 제거 후 성능을 유지하면 효율성을 증가시키는 방법이 인상적
- 디코더 기반 모델들이 주축을 이루고 있어 이러한 인코더 모델들에 대한 연구도 활발히 진행되었으면 좋겠음
Abstract
인코더 전용 트랜스포머 모델인 BERT는 검색 및 분류 작업에서 더 큰 디코더 모델(LLM)에 비해 성능과 크기의 균형이 뛰어나 여러 파이프라인에서 핵심적인 역할을 해왔습니다.
하지만 Pareto improvements는 제한적이였습니다.
본 논문에서 인코더 전용 모델에 현대적인 최적화 기법을 도입해 이전 인코더 모델 대비 큰 Pareto improvements 이루어낸 ModernBERT를 소개합니다.
ModernBERT는 2조 개의 토큰으로 학습, base sequence length가 8192입니다.
다양한 분류 작업과 여러 도메인에서 single vector 및 multi vector retrieval을 아우르는 폭넓은 평가에서 우수한 성능을 보여줍니다.
ModernBERT는 가장 높은 속도와 메모리 효율이 좋은 인코더로 일반적인 GPU에서의 추론을 염두에 두고 설계되었습니다.
Intoduction
BERT의 출시 이후 인코더 기반 모델은 NLP의 application에서 많이 사용되게 되었습니다.
GPT, Llama, Qwen과 같은 LLM의 인기가 증가했음에도 인코더 모델은 여전히 non-generative downstream applications에서 널리 사용되고 있습니다.
인코더의 인기는 주로 적은 추론 요구사항 덕분에 대규모 문서 데이터 처리를 효율적으로 수행하거나 분별 작업을 신속히 수행할 수 있기 때문입니다.
품질과 크기의 절충안을 제공하는 인코더 모델은 대량의 데이터를 다룰 때 인코더-디코더 및 디코더 모델에 비해 경쟁력 있습니다.
인코더 모델은 정보 검색에서 인기가 있습니다.
예를 들어, semantic search에서 인코더를 활용하는 것에 진전을 보이고 있습니다.
인코더 기반 semantic search은 Retrieval-Augmented Generation(RAG) 파이프라인의 핵심 구성 요소이며 여기서 인코더 모델은 사용자 질의와 관련된 컨텍스트를 검색하여 LLM에 제공합니다.
인코더 모델은 분류나 개체명 인식(NER)과 같은 다양한 판별 작업에서도 자주 사용됩니다.
BERT를 사용하는 파이프라인에는 여전히 구형 모델 특히 오리지널 BERT를 백본으로 사용하는 경우가 많습니다.
512 토큰으로 제한된 시퀀스 길이, 최적화되지 않은 모델 설계, vocabulary sizes 문제, 비효율적인 아키텍처 등의 여러 문제에 직면하고 있습니다.
마지막으로, 학습 데이터는 적어 좁은 도메인에 국한되거나 최신 사건에 대한 지식이 부족한 경우가 많습니다.
최근의 노력은 인코더 전용 모델의 단점을 부분적으로만 해결했으며, 범위가 제한적이었습니다. MosaicBERT, CrammingBERT, AcademicBERT은 BERT의 성능을 더 나은 학습 효율성과 일치시키는 데 초점을 맞췄습니다.
NomicBERT와 GTE-en-MLM은 검색 응용 프로그램에 중점을 둔 더 긴 컨텍스트 인코더 모델을 도입했지만, 효율성이나 분류 성능에 최적화하지 않았고 구형 학습 데이터 조합을 재사용하여 프로그래밍 관련 작업에서 한계가 명확했습니다.
본 논문에서는 ModernBERT라는 인코더 전용 Transformer 모델을 소개합니다.
이 모델은 더 긴 시퀀스 길이에서도 다운스트림 성능과 효율성을 높이기 위해 개선된 아키텍처를 설계했습니다.
ModernBERT는 코드 데이터를 포함한 2조 개의 토큰으로 학습하여 인코더 전용 모델을 현대적이고 더 큰 데이터 스케일로 확장했습니다.
ModernBERT-base와 ModernBERT-large 2가지를 출시했으며 다양한 다운스트림 작업에서 기존 인코더 모델을 능가하는 성능을 달성했습니다.
기존 모델보다 거의 두 배 빠르게 8192개의 토큰을 처리하는 높은 추론 효율성으로 이루어졌습니다.
Method
Architectural Improvements
표준 Transformer 구조와 최근 광범위하게 테스트된 개선 사항을 통합합니다.
효율성을 강조한 구조적 및 구현적 개선(2.1.2절)과 GPU에 최적화된 모델 설계(2.1.3절)를 도입했습니다. 모든 구조적 결정은 부록 D에서 자세히 설명한 ablation 연구를 기반으로 했습니다.
Modern Transformer
Bias Terms: 마지막 디코더 linear layers을 제외한 모든 linear layers에서 bias terms을 비활성화했습니다.
Layer Norms의 모든 bias terms도 비활성화했습니다.
이러한 변경으로 linear layers에 더 많은 매개변수를 사용할 수 있게 되었습니다.
Positional Embeddings: absolute positional embeddings 대신 rotary positional embeddings(RoPE)을 사용했습니다.
RoPE는 짧고 긴 컨텍스트 모두에서 입증된 성능과 대부분의 프레임워크에서의 효율적 구현, 컨텍스트 확장 용이성 때문에 선택되었습니다.
정규화: pre-normalization block을 사용하고 안정적인 학습을 돕는 것으로 알려진 표준 Layer Normalization을 적용했습니다.
CrammingBERT처럼 임베딩 계층 뒤에 LayerNorm을 추가하며 반복을 방지하기 위해 첫 번째 어텐션 layer에서의 LayerNorm은 제거했습니다.
활성화 함수: GeGLU(Shazeer, 2020) 활성화 함수를 사용했습니다. 이는 원래 BERT의 GeLU 활성화 함수 기반의 Gated-Linear Units(GLU)을 활성화 함수로 사용합니다.
GLU 변형 사용 시 일관된 성능 개선이 최근 연구들에서 확인되었습니다.
Efficiency Improvements
Alternating Attention
최근 long-context 연구를 따라 ModernBERT의 attention layer는 시퀀스 내 모든 토큰이 다른 모든 토큰에 attention하는 global attention과, 작은 슬라이딩 윈도우 내에서만 토큰이 서로 attention하는 local attention을 교대로 적용합니다.
ModernBERT에서는 매 3번째 layer마다 RoPE theta 값이 160,000인 global attention을 사용하며 나머지 layer에서는 RoPE theta 값이 10,000인 128 토큰 크기의 local sliding window를 사용하는 local attention을 사용합니다.
Unpadding
ModernBERT는 Unpadding 기법을 훈련과 추론 모두에 적용합니다.
일반적으로 인코더 기반 언어 모델은 배치 내의 시퀀스 길이를 균일하게 맞추기 위해 패딩 토큰을 사용하지만, 이는 의미적으로 빈 토큰에 대해 불필요한 연산을 수행하게 만듭니다.
언패딩은 이러한 비효율성을 제거하기 위해 패딩 토큰을 제거하고 미니배치의 모든 시퀀스를 하나의 시퀀스로 병합하여 단일 배치로 처리합니다.
기존의 언패딩 구현은 각 계층별로 시퀀스를 언패딩 및 리패딩하는 방식으로 연산과 메모리 대역폭을 낭비했습니다.
Flash Attention의 가변 길이 attention과 RoPE 구현을 사용해 ModernBERT는 하나의 언패딩된 시퀀스에 대해 jagged attention mask와 RoPE 적용을 지원합니다.
입력 데이터는 토큰 임베딩 계층 이전에 언패딩되며, 모델 출력은 선택적으로 리패딩됩니다. 이를 통해 다른 언패딩 방법에 비해 10~20%의 성능 향상을 얻었습니다.
Flash Attention
Flash Attention은 메모리 및 연산 효율성이 뛰어난 attention kernel로 transformer 기반 모델의 핵심 구성 요소입니다.
Nvidia H100 GPU용 Flash Attention 3는 sliding window attention을 지원하지 않았습니다.
ModernBERT는 global attention latyer에는 Flash Attention 3를 local attention layer에는 Flash Attention 2를 혼합적으로 사용합니다.
torch.compile
PyTorch의 빌트인 컴파일 기능을 활용하여 모든 호환 가능한 모듈을 컴파일하여 훈련 효율성을 향상시켰습니다.
오버헤드로 처리량을 약 10% 향상시켰습니다.
Training
Data
Mixture
ModernBERT 모델들은 주로 영어 데이터를 포함하여 웹 문서, 코드, 과학 문헌 등 다양한 데이터 소스에서 가져온 2조 가량의 토큰을 사용하여 학습되었습니다.
Tokenizer
대부분의 인코더가 기존 BERT 토크나이저를 재사용하는 것과 달리 본 논문의 BERT는 현대적인 BPE 토크나이저를 사용하기로 했습니다.
OLMo 토크나이저의 수정된 버전을 사용하며 해당 버전은 코드 관련 작업에서 더 나은 토큰 효율성과 성능을 제공합니다.
ModernBERT 토크나이저는 원래 BERT 모델과 동일한 special 토큰(e.g., [CLS], [SEP]) 및 템플릿을 사용하여 호환성을 보장합니다.
GPU 활용을 최적화하기 위해 vocab size는 50,368로 설정되었으며 이는 64의 배수이며 다운스트림 응용 프로그램을 지원하기 위해 83개의 미사용 토큰을 포함합니다.
Sequence Packing
패딩을 제거해서 생기는 미니배치 크기의 큰 변화를 방지하기 위해 시퀀스 패킹을 사용했습니다.
Greedy 알고리즘을 사용한 시퀀스 패킹은 99% 이상의 효율성을 달성하여 배치 크기의 균일성을 보장했습니다.
Training Settings
MLM
MosaicBERT에서 사용한 Masked Language Modeling(MLM) 설정을 따릅니다.
Next-Sentence Prediction(NSP) 목표는 성능 향상이 없는 데도 불구하고 눈에 띄는 오버헤드를 유발하기 때문에 제거했습니다.
또한, 기존 15%의 마스킹 비율이 최적이 아니라는 것이 밝혀짐에 따라 30%의 마스킹 비율을 사용합니다.
Optimizer
StableAdamW 사용하며 이는 Adafactor style의 update clipping을 추가하여 AdamW를 개선한 것입니다.
StableAdamW의 LR clipping은 다운스트림 작업에서 표준 그래디언트 clipping보다 우수한 성능을 보였으며 훈련 안정성을 높였습니다.
Learning Rate Schedule(LR)
사전 학습 동안 Warmup-Stable-Decay(WSD)로도 알려진 modified trapezoidal Learning Rate(LR) 스케줄을 사용합니다.
짧은 LR 워밍업 후 스케줄은 대부분의 학습 동안 LR을 일정하게 유지하며 이후 짧은 short LR decay가 뒤따릅니다.
이 스케줄은 코사인 스케줄링의 성능과 일치하는 것으로 나타났으며 체크포인트에서의 재훈련 시 cold restart issues를 방지할 수 있는 장점이 있습니다.
대부분의 trapezoidal Schedule과 달리 1−sqrt LR decay를 사용하며 이는 선형 및 코사인 decay보다 뛰어난 성능을 보였습니다.
ModernBERT-base는 3억 토큰 워밍업 후 학습률 8e-4로 1.7조 토큰을 학습했습니다.
ModernBERT-large는 20억 토큰 워밍업 후 학습률 5e-4로 9000억 토큰을 학습했습니다.
이후 학습률 5e-4에서 몇백억 토큰 동안 loss가 정체되어 학습률 5e-5로 되돌려 학습을 재개했습니다.
Batch Size Schedule
Batch size scheduling은 smaller gradient accumulated batches로 시작하여 시간이 지남에 따라 전체 배치 크기로 증가합니다.
ModernBERT-base는 768에서 4608로, ModernBERT-large는 448에서 4928로 배치 크기를 증가시켰으며 각 배치 크기가 동일한 업데이트 스텝 수를 갖도록 uneven token schedule을 사용했습니다.
Weight Initialization and Tiling
ModernBERT-base는 Megatron 초기화를 따르는 임의의 가중치로 초기화했습니다.
ModernBERT-large는 Phi 모델 계열을 따르며, ModernBERT-base의 가중치에서 초기화했습니다.
Context Length Extension
ModernBERT는 1024 시퀀스 길이와 RoPE theta 10,000에서 1.7조 토큰을 학습한 후, 글로벌 어텐션 레이어의 RoPE theta를 160,000으로 증가시켜 컨텍스트 길이를 8192 토큰으로 확장하고 추가로 3000억 토큰을 학습했습니다.
원본 사전 학습 데이터셋의 8192 토큰 혼합물을 사용하여 학습률 3e-4로 2500억 토큰을 학습했습니다.
고품질 소스를 업샘플링한 후 1−sqrt LR 스케줄로 500억 토큰 동안 decay 단계를 진행했습니다.
이 컨텍스트 확장 과정은 다운스트림 작업에서 가장 균형 잡힌 모델을 만들어냈습니다.
단일 전략만 사용한 실험은 검색 또는 분류 작업에서 성능 손실을 초래했습니다.
실험 결과
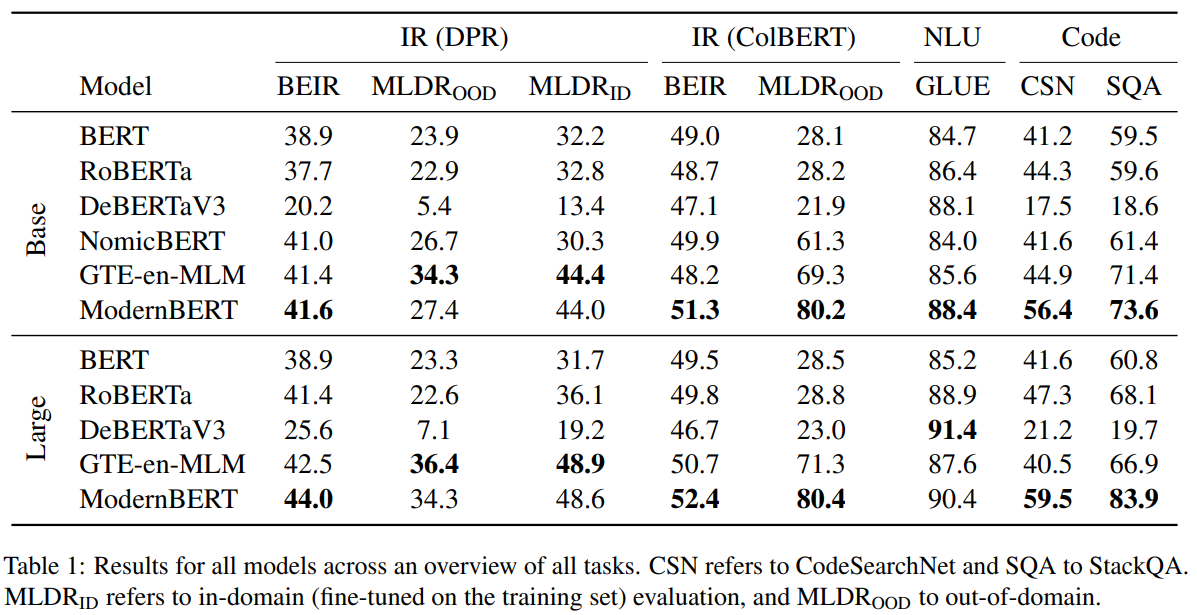
검색, 자연어 이해, 코드 탐색과 같은 분야에서 높은 성능을 보입니다.
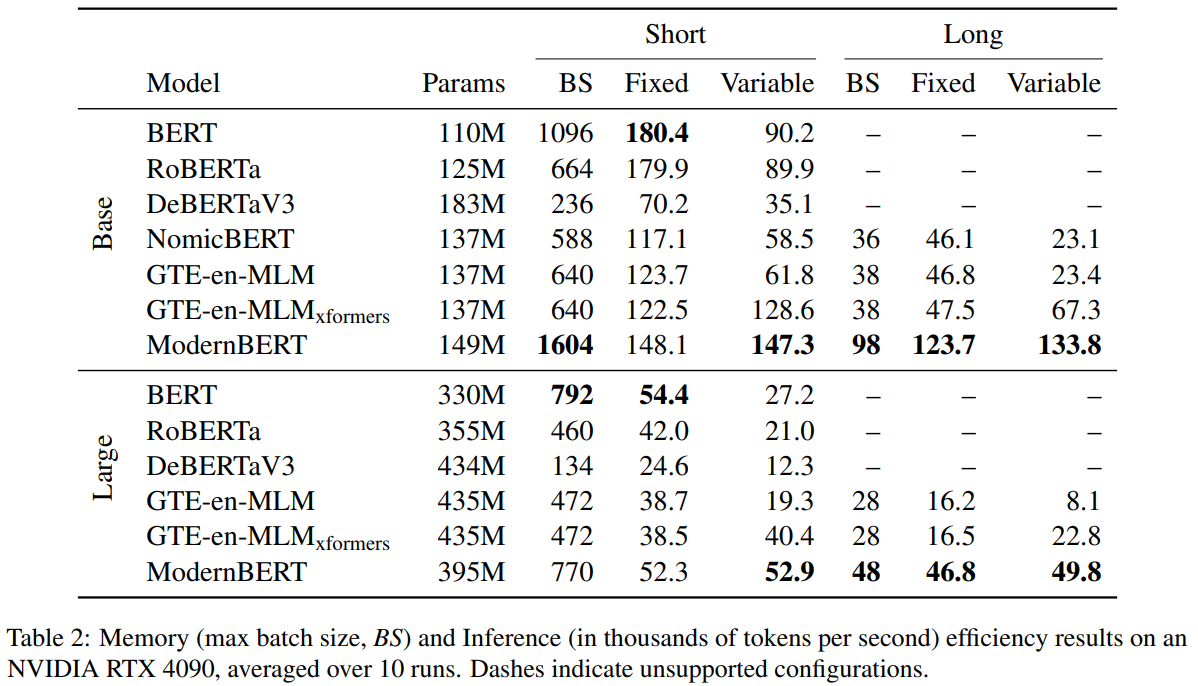
효율성 역시 다른 BERT들 보다 높아진 것을 확인할 수 있습니다.
