Evolutionary Optimization of Model Merging Recipes paper link
github link
모델 병합 모델
주요 특징
- 파라미터 공간과 데이터 공간 정보를 이용하여 모델을 병합하여 더 좋은 성능의 모델로 만들 수 있습니다.
- Cross-Domain의 모델을 병합하여 다른 두 개의 도메인을 커버하고 더 나은 성능의 모델로 구성합니다.
- 작은 모델끼리 병합으로 큰 모델의 성능을 능가합니다.
주관적인 강점
- 단순히 모델 적층에 순서를 변경해 병합하는 기존의 방식보다 더 나은 방식을 제안합니다.
- 주관적인 모델 선택 없이 진화 알고리즘을 이용하여 최적의 조합으로 좋은 모델을 발견하는 방법입니다.
- Cross-Domain 병합이 가능한 것을 증명하였고, 다른 두 도메인에서 높은 성능을 기록할 수 있습니다.
- 추가적인 학습 없이 모델을 병합할 수 있습니다.
주관적인 약점
- 일본에 창업한 기업이라 일본어 타겟으로 만든 느낌이 매우 강합니다. 일본어 LLM 성능이 좋지 못하여 병합하여 잘 되는 것인지, 처음부터 좋지 못한 LLM 모델만 있는 것인지 확인해야 합니다.
- 모델 파라미터 수가 다른 두 모델을 병합하는 것은 불가능한 것으로 보입니다.
- 단순 병합 모델과 비교하여 얼마나 성능이 증가하는지 얼마나 효율적인지를 보여주는 실험이 빈약합니다.
Abstract
본 논문은 진화라는 컨셉 적용하여 모델의 생성을 자동화하는 새로운 방식을 제안합니다.
모델 병합은 효율성 때문에 LLM(Large Language Model) 개발에 적용되어 왔지만, 인간의 직관과 도메인 지식에 의존하고 있고 성능 개선에 제한이 있습니다.
방대한 추가 데이터나 계산 없이도 다양한 오픈 소스 모델들의 조합을 자동으로 탐색하여 한계를 개선하고자 합니다.
parameter space와 data flow space에 모두 동작하여 개별 모델의 최적화 한계를 뛰어넘을 수 있습니다.
수학적 추론 능력이 필요한 크로스 도메인에 병합까지 가능하며, 모델 병합으로 더 많은 매개변수를 가진 일본어 LLM 벤치마크에서 최고 수준 성능을 달성합니다.
더 나아가 일본어 VLM(Vision Language Model)에서도 더 나은 성능을 보여줍니다.
※ 논문을 작성한 회사가 일본에 창업하여 일본어 LLM을 타겟으로 하고 있습니다.
Introduction
모델 병합(model merging)은 모델 성능 개선에 새로운 패러다임의 전환을 보여주는 혁신적인 방법입니다.
여러 LLM을 단일 LLM으로 결합함으로써 추가 학습이 필요 없어 매우 효율적인 접근 방식입니다.
Open LLM Leaderboard은 대부분 병합된 모델이 상위권을 랭크하고 있습니다.
하지만 모델을 병합하여 성능을 올리는 방식은 모델을 만드는 제작자의 직관과 본능에 매우 의존적입니다.
또한 벤치마크에 대한 지식과 도메인 지식을 갖추고 있어야 좋은 모델 병합을 할 수 있습니다.
본 연구에서는 진화라는 매커니즘에서 영감을 받아 다양한 모델을 자동으로 병합하고 새로운 능력을 갖춘 새로운 모델을 만드는 새로운 방법을 제안합니다.
진화 알고리즘은 parameter space와 data flow space에서 모두 탐색할 수 있으며, 두 차원을 통합하는 프레임워크를 제안합니다.
5가지 주요한 기여를 제공합니다.
- Automated Model Composition: Evolutionary Model Merge를 도입하여 다양한 오픈 소스 모델의 최적 조합을 자동으로 발견하는 방법을 도입니다. 추가적인 학습과 데이터가 필요 없이도 좋은 모델을 구성합니다.
- Cross-Domain Merging: 다른 목적을 가진 모델을 병합하여 더 나은 모델을 구성합니다. (언어 모델 + 수학 모델, 언어 모델 + 비전 모델)
- State-of-the-Art Performance: 수학적 추론 능력과 VLM에 대하여 벤치마크에서 최고 성능을 기록합니다.
- High Efficiency and Surprising Generalizability: 7B 모델만을 이용해도 70B 모델의 성능을 뛰어넘을 수 있습니다.
- Culturally-Aware VLM: 일본어 문화 컨텐츠의 인식 능력이 다른 모델에 비교하여도 높은 성능을 보여줍니다.
Background and Related Work
Overview of Model Merging
모델 병합은 사전 학습된 여러 모델의 장점을 활용하는 새로운 접근 방식을 제공합니다.
특정 다운스트림 작업에 대하여 단일 통합 모델로 결합할 수 있습니다.
다운스트림 작업에 자주 사용되는 전이 학습(transfer learning)과는 대조적입니다.
전이 학습은 빠르게 다운스트림 작업에 맞게 학습되고 적용할 수 있지만 다양한 작업에 사용할 수 없습니다.
하지만 모델 병합은 여러 모델의 지식을 병합하여 더욱 포괄적인 모델을 만들 수 있습니다.
여러 모델을 병합하는 간단한 방법 중 가중치를 평균하여 사용되는 방법이 존재합니다(Model soups).
하지만 local minima로 이어지는 문제점이 존재합니다.
선형 가중치 평균화 방식(Linear weight averaging)도 제안되었습니다.
해당 방식은 Stable Diffusion 모델의 매개변수를 병합할 수 있고 이는 다양한 모델 병합의 결과로 이어졌습니다.
Merging Language Models
가중치를 보간하여 병합하는 방식은 이미지 생성 모델에는 잘 작동하지만, 언어 모델의 병합에는 여전히 문제가 존재합니다.
해결하기 위해 제안된 몇 가지 방식입니다.
- Task Arithmetic: (사전 학습 모델 가중치) - (미세 조정 모델 가중치) = (작업 벡터), 작업 벡터를 이용하여 병합된 모델의 동작을 조정합니다.
- TIES-Merging: TRIM + ELECT SIGN + MERGE 방식으로 기존의 파라미터를 일괄적 병합하여 각 모델의 지양성을 저해하는 방식을 줄이기 위해 고안한 방식입니다.
- DARE: task에 맞게 fintuning된 모델과 원본 모델이 있을 때 학습 과정에서 두 모델의 parameter 간의 차이인 delta parameters는 사실 대부분 제거해도 성능의 큰 영향이 없다. 그래서 원본 모델에 fintuning으로 얻어진 모델의 parameter 간의 차이를 그냥 더하는게 아니라, 랜덤하게 p 확률로 제거를 하고 1-p 확률로 남은 변동치들에 1/1-p를 곱해준 뒤 원본 모델에 더 해주는 방식입니다.
- Mergekit: 여러 모델의 레이어를 순차적으로 쌓아 새로운 모델을 만드는 Frankenmerging 방식입니다. 완전히 다른 모델을 병합하여 새로운 아키텍처를 생성할 수 있는 장점이 있습니다. 해당 방식은 많은 시행착오가 필요하고 대부분 사람은 비슷한 레시피를 사용하여 모델을 병합하고 있습니다. 이를 진화 메커니즘을 이용하여 개선하고자 합니다.
Connection to Evolutionary Neural Architecture Search
모델 병합은 상당한 잠재력을 가지고 있지만 인간의 직관과 도메인 지식에 크게 의존합니다.
개선하기 위해서는 보다 체계적인 접근 방식이 필요해지고 본 논문은 자연 선택에서 영감을 받은 진화 알고리즘이 효과적인 병합 솔루션을 열 수 있다고 제안합니다.
Neural Architecture Search (NAS) 방식은 새로운 아키텍처를 발견할 수 있지만 각 후보 모델 아키텍처를 새로 훈련해야 했기 때문에 효율성 측면에서 매우 떨어집니다.
하지만 논문에서 제안한 방식은 기존 transformer block의 기존 기능을 활용하는 구조를 발견하는 방식이여 효율성이 매우 높습니다.
Method
프레임워크의 목표는 병합된 모델을 자동 생성하고, 병합된 모델이 개별 모델의 성능을 능가하도록 보장하는 것입니다.
진화 알고리즘을 적용하기 위해 병합 프로세스를 두 개의 독립된 직교 공간으로 분리하여 개별 영향을 분석합니다.
해당 분석을 이용하여 구성한 공간을 원할하게 통합하는 프레임워크를 제안합니다.
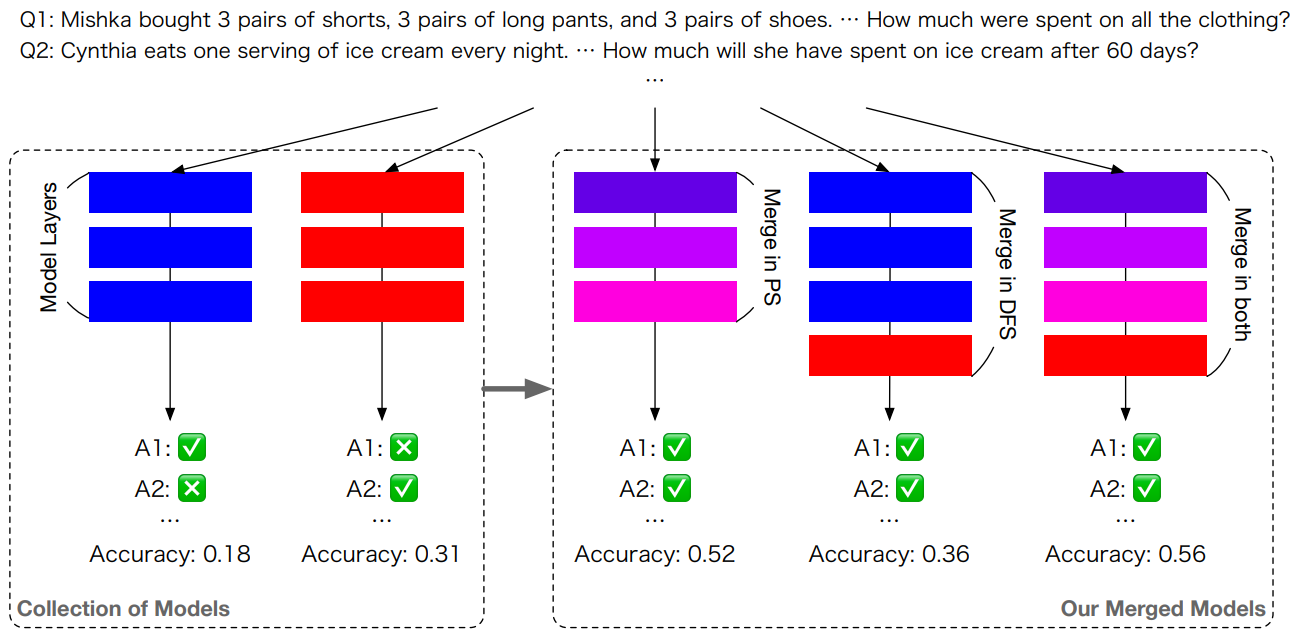
3가지 중요 포인트가 존재합니다.
- 파라미터 공간(Parameter Space, PS)에서 각 레이어의 혼합 파라미터에 대한 가중치를 진화시키는 점.
- 데이터 흐름(Data Flow Space, DFS)에서 레이어의 순열을 진화시키는 점.
- PS와 DFS 모두에서 병합을 위해 두 방법을 결합하는 통합 전략.
PS에서의 병합은 단순히 레이어 파라미터를 복사하고 이어 붙이는 것이 아니라 가중치를 혼합합니다. (보라색 레이어)
Merging in the Parameter Space
PS에서 모델 병합은 여러 foundational model의 가중치를 동일한 신경망 구조를 가진 단일 모델로 통합하되, 개별 모델보다 뛰어난 성능을 내는 것을 목표로 합니다.
이를 위해 task vector 분석을 활용하여 각 모델이 최적화되었거나 뛰어난 성능을 보이는 특정 task를 기반으로 모델의 강점을 파악합니다.
TIES-Merging을 DARE 방식을 결합하여 레이어 단위의 세밀한 병합이 가능하도록 개선합니다.
각 레이어에서 병합 매개변수를 설정하고 공분산 행렬 적응(CMA-ES)과 같은 진화 알고리즘을 사용하여 특정 테스크에 대해 최적화합니다.
테스크 지표는 정량 평가 지표를 사용합니다. (accuracy for MGSM, ROUGE score for VQA)
해당 방식은 레이어 수준에서 병합이 가능하며, 병합 구성을 테스크 성능 지표를 기준으로 최적화함으로써 각각의 모델의 강점을 최대한 활용하는 것이 핵심입니다.
Merging in the Data Flow Space
PS에서의 병합과 달리, DFS에서의 모델 병합은 각 레이어의 원래 가중치를 그대로 유지합니다.
DFS에서는 토큰이 신경망을 통과할 때의 추론 경로를 최적화하는데, 예를 들어 A 모델의 i번째 레이어 이후에는 토큰이 B 모델의 j번째 레이어로 전달되는 형식입니다.
N개의 모델, T의 예산으로 최적화 경로를 찾습니다.
Li,j에서 i번째 모델의 j번째 레이어를 의미하고 t ∈ [1, T], t는 추론 경로의 단계를 나타냅니다.
총 M개의 레이어가 존재한다고 가정하면 탐색 공간의 크기는 (M + 1)T로 매우 크게 됩니다.
예를 들어 32개의 레이어를 가지고 있는 모델 2개가 있고 60번의 추론 단계가 존재한다면 탐색 공간이 기하급수적으로 증가하여 사실상 불가능합니다.
이러한 문제를 해결하기 위해 T = M * r을 가지는 I를 도입합니다.
해당 설정을 이용하여 모든 레이어를 순차적으로 배열하고 r번 반고하여 각 레이어를 포함하거나 제외할지 결정합니다. 해당 방식을 이용하면 탐색 공간이 2T으로 줄일 수 있습니다. 여전히 큰 공간이지만 진화 알고리즘으로 처리 가능한 범위입니다.
*증명 T가 3일 때 배열 I는 추가하지 않는(0)의 상태와 추가하는(1)의 상태로 존해할 때
(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0), (1, 0, 1), (1, 1, 0), (1, 1, 1)
총 23의 경우의 수가 존재합니다.
추가적으로 레이어를 위와 같이 변경하면 다른 입력 분포를 만날 경우 성능이 떨어질 수 있습니다.
이러한 문제를 해결하기 위해 입력을 스케일링하는 방법을 도입합니다.
W ∈ RM×M에 해당하는 행렬을 사용하여 각 레이어의 스케일링 최적화합니다.
Merging in Both Spaces
PS와 DFS는 방식은 서로 다른 접근법이지만, 두 방법을 결합하면 병합된 모델의 성능을 더욱 향상할 수 있습니다.
첫 번째로 PS를 이용하여 하나의 병합 모델을 만든 후, 이 병합 모델을 다시 모델 컬렉션에 넣고 DFS 병합을 적용하여 새로운 병합 모델을 만드는 식입니다.
Experiments
기존 커뮤니티에 알려진 병합된 모델들은 대부분 LLM Leaderboard에서 정의된 좁은 작업 범위를 최적화하는 것이 목표입니다.
하지만 본 논문에서는 진화적 탐색을 이용하여 서로 다른 도메인(수학, 비영어, 컴퓨터 비전) 모델들을 병합하는 새로운 방법을 찾아내는 것을 목표로 합니다.
서로 다른 도메인의 모델을 효과적으로 병합하면 더 넓은 도메인을 커버할 수 있는 모델을 만들 수 있게 됩니다.
예를 들어 일본어 LLM과 수학적 추론에 능한 영어 LLM을 병합하여 일본어 수학 LLM을 만들고, 일본어 LLM과 문화적 특수성을 잘 처리하는 영어 VLM을 병합하여 일본어 VLM을 만드는 실험을 통해 해당 접근법을 입증합니다.
Results
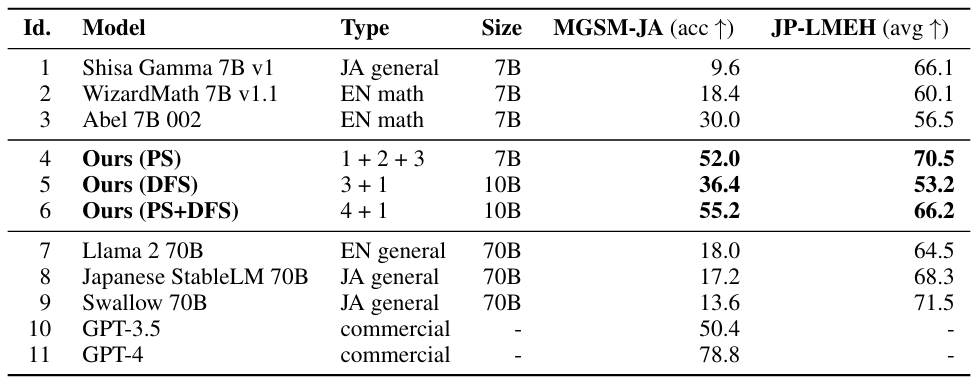
위의 table은 일본어 수학 및 일본어 LLM 벤치마크 작업에 대한 LLM 성능을 요약합니다. 일본어 모델(Id. 1)은 수학 능력 부족하지만 일본어(JP-LMEH)에 대한 이해력이 높습니다. 반대로 수학 모델(Id. 2, 3)은 반대의 결과를 보입니다.
병합 모델(Id. 4, 5, 6)은 수학 능력과 일본어 이해력이 크게 개선된 것을 알 수 있습니다.
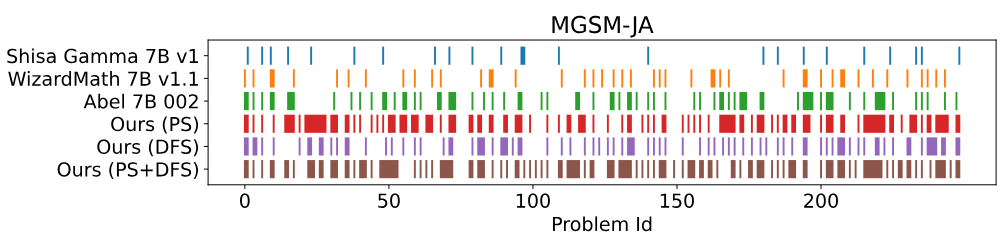
위의 이미지는 수학 문제에 대한 답안지를 개략적으로 보여줍니다.
1~15번의 답안이 기존 모델과 유사한 패턴을 유지하는 것을 확인할 수 있으며, 원본 모델이 해결하지 못한 문제 20~30번을 성공적으로 해결하면서 새로운 능력을 나타냅니다.

위의 이미지를 통해 VLM도 진화 병합 방법을 이용하면 성능이 개선되는 것을 확인할 수 있습니다.
Discussion and Future Work
현재의 방법은 진화적 탐색에 필요한 소스 모델을 직접 선택해야 합니다.
진화라는 컨셉을 활용하여 후보 모델을 검색하는 것도 가능할 것입니다.
Automerge라는 병합 관련된 논문이 비슷한 시기에 발표되었다.
해당 방식은 상위 Leaderboard 20개 중 2개의 모델을 무작위로 선택하고, SLERP 또는 DARE-TIES를 적용하여 새로운 모델을 생성합니다.
해당 방식은 벤치마크의 상위 모델을 이용하여 병합하기 때문에 과적합된 모델을 만들 가능성이 높고, 더 나은 모델을 만드는 것보다 병합에 대한 원칙적인 접근 방식을 도출하는 데 의미가 있습니다.
Limitations
도메인 별로 차이가 있는 모델로 모든 도메인을 커버할 수 있지만, 반면에 논리의 일관성 측면에서는 부족한 경우가 존재합니다.
