느낌점
- 드디어 다국어 지원(한국어 포함)된 모델 등장
- 잠깐 사용해 봤을 때는 코드 스위칭이나, 대답을 잘 하는 거 같았음
- 새로운 점이 딱히 없다? Qwen backbone에 레이어 추가하여 학습
- 결국 데이터셋 정제, 증강은 llm judge..
- 한국어 데이터셋 정부 지원 아래에 만들면 참 좋겠다는 생각...
Abstract
LLM은 자연어 처리 분야에 혁신을 가져왔지만 오픈 소스 다국어 LLM은 여전히 부족하고 기존 모델들은 언어 지원되는 범위가 제한적인 경우가 많습니다.
이러한 모델들은 주로 자원이 풍부한 언어(영어)를 우선적으로 다루고 많이 사용되는 언어지만 자원이 부족한 언어들은 종종 간과되는 경향이 있습니다.
이러한 불균형을 해소하기 위해 저희는 Babel이라는 오픈 소스 다국어 LLM을 소개합니다.
Babel은 사용자 수 기준 상위 25개 언어를 포함하며 이는 전 세계 인구의 90% 이상을 지원하고,다른 오픈 소스 다국어 LLM에서 소외되었던 많은 언어들을 포함합니다.
기존의 사전 학습 방식과는 달리 Babel은 레이어 확장 기술을 통해 매개변수 수를 늘려 Babel의 성능 한계를 높입니다.
효율적인 추론과 미세 조정을 위해 설계된 Babel-9B와 오픈 소스 다국어 LLM의 새로운 기준을 제시하는 Babel-9B, 83B 이렇게 두 가지 버전의 모델을 소개합니다.
다국어 task에 대한 광범위한 평가 결과 Babel은 비슷한 규모의 오픈 소스 LLM과 비교했을 때 뛰어난 성능을 보여주었습니다.
게다가, 오픈 소스 SFT 데이터셋을 활용하여 Babel은 놀라운 성능을 달성했습니다.
특히 Babel-9B-Chat은 100억 매개변수 규모 LLM 중에서 선두를 달리고 있으며, Babel-83B-Chat은 다국어 task에서 새로운 기준을 제시하며 상용 모델과 견줄 만한 수준에 도달했습니다.
Introduction
LLM은 NLP에 혁신을 가져왔으며 인간 생활의 다양한 측면을 개선하는 강력한 도구로 부상했습니다.
그러나 다국어를 지원하는 LLM은 상대적으로 드물며 특히 오픈 소스 영역에서는 다국어 모델이 공급이 더 넓은 언어 지원에 대한 증가하는 수요에 미치지 못합니다.
기존의 오픈 소스 다국어 LLM 중에서도 지원하는 언어 범위가 제한적인 경우가 많습니다.
Bloom, GLM-4, Qwen2.5와 같은 모델은 일반적으로 프랑스어, 아랍어 및 독일어와 같이 대량의 고품질 데이터셋을 쉽게 사용할 수 있는 선진국 언어와 같이 광범위한 학습 리소스가 있는 언어를 지원에 우선시하는 경향이 있습니다.
반대로 힌디어, 벵골어 및 우르두어와 같이 덜 개발된 지역에서 사용되는 언어는 수백만 명의 화자를 보유하고 프랑스어 또는 독일어 화자 수보다 많은 경우에도 매우 적은 관심을 받습니다.
LLM을 더 넓은 전 세계에게 더 쉽게 접근할 수 있도록 하기 위해 전 세계 화자의 90% 이상을 지원하는 것을 목표로 하는 새로운 오픈 소스 다국어 대규모 언어 모델인 Babel을 소개합니다.
영어, 중국어, 힌디어, 스페인어, 아랍어, 프랑스어, 벵골어, 포르투갈어, 러시아어, 우르두어, 인도네시아어, 독일어, 일본어, 스와힐리어, 필리핀어, 타밀어, 베트남어, 터키어, 이탈리아어, 자바어, 한국어, 하우사어, 페르시아어, 태국어 및 버마어를 포함하여 화자 수 기준 상위 25개 언어에 중점을 둡니다.
특히, 이러한 언어의 절반 이상은 널리 사용됨에도 불구하고 기존의 오픈 소스 다국어 LLM에서 무시되었습니다.
이러한 언어 중 다수에 대한 고품질 학습 데이터의 가용성이 제한적이므로 가능한 최고 수준의 데이터 품질을 보장하기 위해 데이터 정리 파이프라인을 최적화하는 데 상당한 중점을 둡니다.
이를 위해 다양한 소스에서 데이터를 수집하고 LLM 기반 품질 분류기를 사용하여 학습을 위한 깨끗하고 고품질의 콘텐츠를 선별합니다.
Conventional continue pretraining과는 달리 모델 확장을 통해 Babel의 매개변수 공간을 늘려 성능 한계를 향상시킵니다.
Layer extension을 사용하는데 이는 원래 아키텍처와 동일한 새로운 레이어를 추가하는 구조화된 접근 방식입니다.
접근성과 최첨단 성능의 균형을 맞추기 위해 Babel-9B와 Babel-83B의 두 가지 모델을 제시합니다.
Babel-9B는 효율적인 다국어 LLM 추론 및 미세 조정을 위해 설계되어 연구 및 로컬 배포에 이상적이고 Babel-83B는 높은 성능의 오픈 소스 다국어 LLM으로서 새로운 벤치마크를 확립합니다.
다국어 데이터셋에 대한 포괄적인 평가는 비슷한 크기의 오픈 소스 LLM과 비교했을 때 Babel의 뛰어난 성능을 강조합니다.
또한 WildChat 및 Everything Instruct Multilingual을 포함한 오픈 소스 지도 학습 미세 조정(SFT) 데이터셋을 활용하여 추가 학습 데이터를 생성하지 않고도 1백만 개의 대화로 구성된 SFT 학습 풀을 구성합니다.
이 풀은 Babel-9B-Base 및 Babel-83B-Base를 학습하는 데 사용됩니다.
공개적으로 사용 가능한 미세 조정 데이터만으로도 Babel 챗 모델이 강력한 task 해결 능력을 보여주는 것을 확인했습니다.
특히 Babel-9B-Chat은 10B 크기 LLM 중에서 최첨단 성능을 달성하고 Babel-83B-Chat은 오픈 LLM에 대한 새로운 벤치마크를 설정하며 특정 task에서는 GPT-4o와 같은 최첨단 상용 모델과 비슷하게 수행합니다.
Supported Languages

최근 LLM은 GLM-4, Qwen2.5와 같이 영어가 아닌 언어를 점점 더 많이 지원하고 있습니다.
그러나 이러한 모델은 주로 프랑스어와 독일어와 같이 수많은 연구 기관에서 고품질 데이터를 큐레이팅하고 처리하는 선진국에서 주로 사용되는 광범위한 학습 코퍼스를 가진 언어에 초점을 맞추고 있습니다.
대조적으로 힌디어(모국어 화자 3억 4,500만 명), 벵골어(모국어 화자 2억 3,700만 명) 및 우르두어(모국어 화자 7,000만 명)와 같이 덜 개발된 국가에서 사용되는 언어는 비교적 관심을 덜 받습니다.
참고로 스페인어는 모국어 화자 4억 8,600만 명이 사용하고, 프랑스어는 7,400만 명, 독일어는 7,600만 명이 사용합니다.
LLM을 더 넓은 사용자들이 접근할 수 있도록 하기 위해 화자 수를 기준으로 언어를 선택했습니다.
구체적으로 표 1에 자세한 통계가 제공된 총 25개 언어를 포함했습니다.
Babel은 전 세계적으로 약 70억 명의 화자에게 서비스를 제공하여 전 세계 인구의 90% 이상을 커버합니다.
Data Preparation
Data Collection
이전 연구의 토대를 바탕으로 데이터 소스의 범위를 다양화했습니다.
특히 Wikipedia(Foundation) 및 교과서와 같은 필수 지식, CC-News(Crawl)의 저널리즘 콘텐츠, CulturaX와 같은 웹 기반 코퍼스 및 MADLAD-400 데이터셋을 통합했습니다.
LLMs-based Data Cleaning and Processing
언어 중 다수에 대한 고품질 학습 데이터의 가용성이 제한적이므로 가능한 최고 수준의 데이터 품질을 보장하기 위해 데이터 정리 파이프라인을 최적화하는 데 상당한 중점을 둡니다. 자세한 절차는 다음과 같습니다.
(1) Normalization.
100자 미만의 문서 또는 30% 이상의 숫자를 포함하는 문서와 같이 품질이 낮은 데이터를 필터링하기 위해 미리 정의된 규칙을 적용합니다.
(2) LLMs-based quality classifier.
모델 기반 라벨링과 전문가 언어 개선을 결합하여 학습 데이터셋을 구축하는 방법을 활용하여 Qwen-2.5-0.5B-Instruct 모델을 기반으로 분류기를 학습합니다.
특히 GPT-4o가 다양한 차원에서 잠재적인 학습 데이터를 평가하고 점수를 매기도록 유도하는 "LLM-as-a-judge" 접근 방식을 채택합니다.
이러한 초기 점수는 평가자 학습을 위해 고품질 데이터만 선택되도록 언어 전문가가 신중하게 검토합니다.
(3) Deduplicate.
hashing, pairing duplicates, constructing graphs 및 제거를 위한 중복 기록을 통해 중복 문서를 식별하고 제거합니다.
Model Description
Model Extension
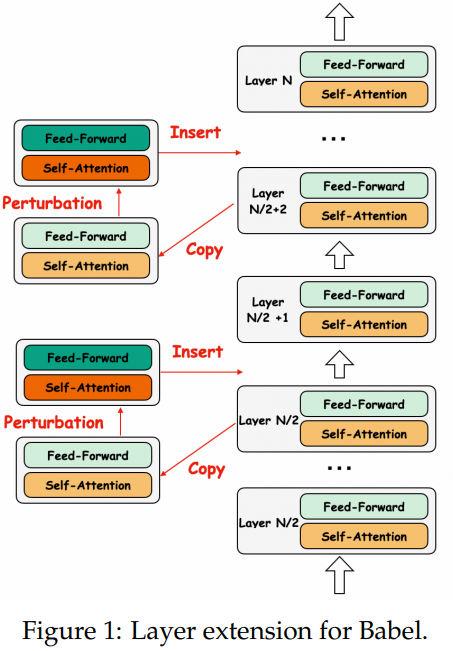
모델의 성능 상한선을 높이기 위해 모델 확장을 통해 매개변수 수를 늘립니다.
그림 1에서 볼 수 있듯이 원래 구조와 동일한 새로운 레이어를 직접 추가하는 구조화된 방법인 레이어 확장을 사용합니다.
이 접근 방식은 어텐션 헤드, 히든 임베딩 또는 임베딩 레이어 등과 같은 모델의 핵심 구성 요소에 영향을 미치지 않습니다.
또한 중간 및 뒷쪽 레이어가 편집에 덜 민감하다는 실험에서 영감을 받아 모델의 후반부에 레이어를 확장하기로 선택했습니다.
레이어를 추가하는 다양한 위치와 새로 추가된 매개변수의 초기화 방법을 포함하여 다양한 레이어 확장 설정을 실험합니다.
원래 레이어 사이에 레이어를 삽입하거나 원래 모델 뒤에 레이어를 추가하는 실험을 진행합니다.
매개변수 초기화의 경우 원래 매개변수를 복제하거나 모두 0으로 초기화하거나 원래 매개변수에 노이즈를 추가하는 것을 고려합니다.
모델의 초기 성능을 기반으로 최적의 레이어 확장 방법을 선택하고, 추가 학습에 미치는 영향도 고려하면서 성능에 미치는 영향을 최소화하는 방법을 우선시합니다.
Analysis

Qwen2.5-72B-Base를 백본 모델로 사용하여 초기화 방법에 대한 제거 분석을 수행하고 MMMLU에서 성능을 평가합니다.
구체적으로 (1) 레이어 삽입 위치 (기존 레이어 사이 또는 원래 모델의 마지막 레이어에 직접 추가)와 (2) 초기화 방법 (원래 매개변수 복사 또는 노이즈 도입)의 두 가지 주요 측면을 조사합니다.
표 2는 다양한 레이어 확장 방법에 대한 초기화 결과를 보여줍니다.
연구 결과에 따르면 모델에 새로운 레이어를 직접 추가하면 성능이 크게 저하되어 갑작스러운 구조적 수정이 학습된 표현을 방해할 수 있음을 시사합니다. 기존 아키텍처 내에 새로운 레이어를 삽입하면 성능 저하가 미미하게 발생하여 점진적인 확장이 모델 안정성에 미치는 영향이 적음을 나타냅니다.
또한 노이즈를 도입하지 않고 레이어를 복제하는 것이 원래 특징 표현의 무결성을 유지하므로 가장 높은 성능을 달성한다는 것을 확인했습니다.
반면에 평균이 높은 가우스 노이즈를 추가하면 초기화된 매개변수의 과도한 교란으로 인해 성능에 상당한 영향을 미칩니다.
모든 값을 0으로 초기화하면 잔차 연결로 인해 원래 성능이 유지됩니다.
그러나 학습 후 성능이 저하됩니다.
초기화 중에 노이즈를 추가하면 학습 결과를 개선할 가능성이 있으므로 안정성과 적응성 사이의 균형을 유지하면서 평균이 0.0001인 가우스 노이즈를 적용하는 초기화 방법을 선택합니다.
Model Training
Model Architecture

Qwen2.5B-7B 및 Qwen2.5-72B를 활용하여 표 3에 설명된 모델 확장 방법을 사용하여 Babel-9B 및 Babel-83B를 초기화합니다.
그림 1에서 볼 수 있듯이 모델의 후반부에 레이어를 삽입하여 격층마다 하나씩 추가합니다.
Pre-training Strategy
Stage 1-Recovery.
매개변수를 수정하면서 잘 훈련된 매개변수 연결을 방해하면 Babel의 초기 성능은 원래 모델에 비해 저하됩니다.
결과적으로 사전 훈련의 첫 번째 단계에서는 모든 언어를 포괄하는 크고 다양한 일반 훈련 코퍼스가 복구에 매우 중요합니다.
따라서 일부 언어의 코퍼스 가용성이 제한되어 완벽한 형평성을 달성하기 어려울 수 있지만, 각 언어에 대한 코퍼스를 사전 훈련 데이터에서 가능한 한 동일하게 샘플링합니다.
또한 성능 복구를 가속화하기 위해 1단계 사전 훈련 중에 영어 및 중국어 훈련 코퍼스를 결합합니다.
영어의 경우 RedPajama, Proof-Pile-2와 같이 널리 채택되고 잘 선별된 사전 훈련 데이터셋을 활용하고, 중국어의 경우 YAYI 2를 사용합니다.
Stage 2-Continuous Training.
복구 후 다음 단계는 특히 이전 모델에서 간과된 언어에 대한 다국어 기능을 향상시키는 것입니다.
이를 위해 사전 훈련 코퍼스에서 저자원 언어의 비율을 늘리고 모델을 계속 훈련합니다.
또한 튜토리얼이 LLM이 새로운 지식을 습득하는 데 더 효과적이므로 훈련 코퍼스에서 교과서의 비율을 늘립니다.
