Pandas pivot table
- index, columns, values, aggfunc
Sales data 피벗 테이블
index 설정
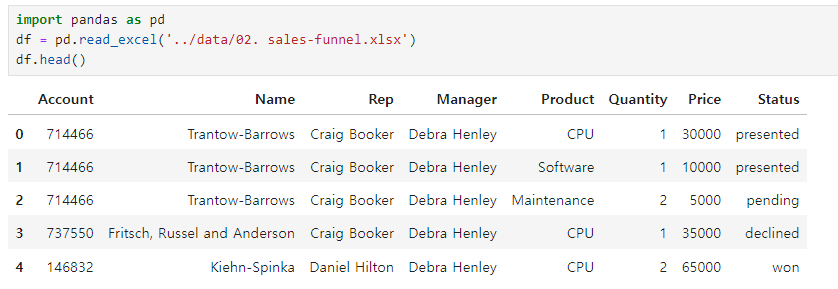
- index를 Name으로 설정
pd.pivot_table(df, index="Name", aggfunc="sum")
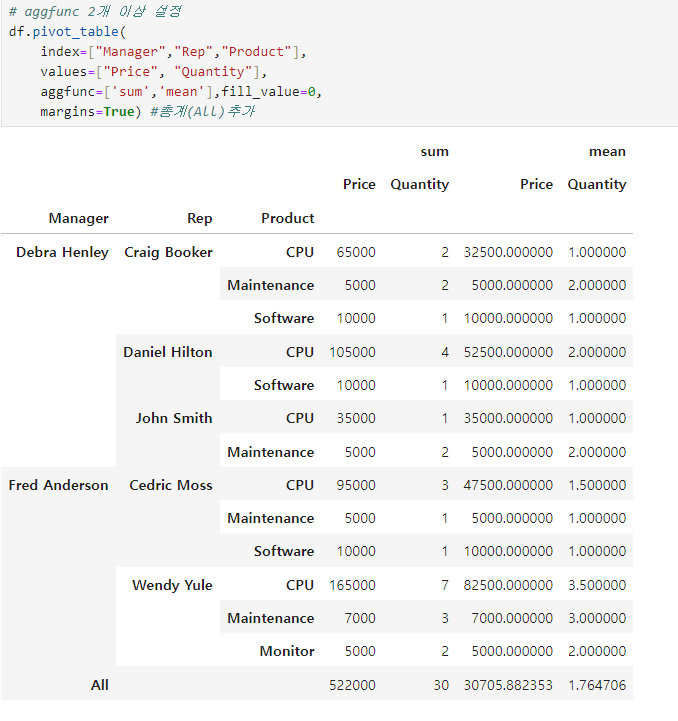
- index를 Name과 Rep으로 설정
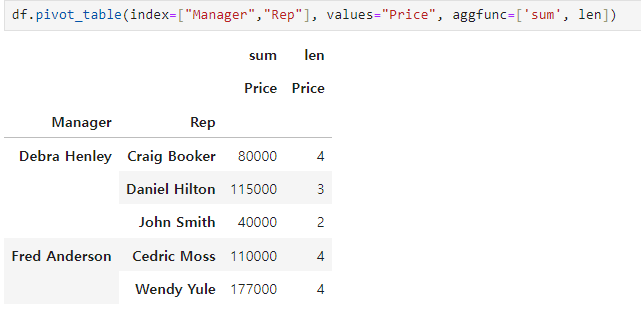
- value를 Price로
- columns를 Price와 Quantity로 설정,
- 빈 값을 0으로 채움
df.pivot_table(index=["Manager","Rep"], values="Price", columns="Product", aggfunc='sum', fill_value=0)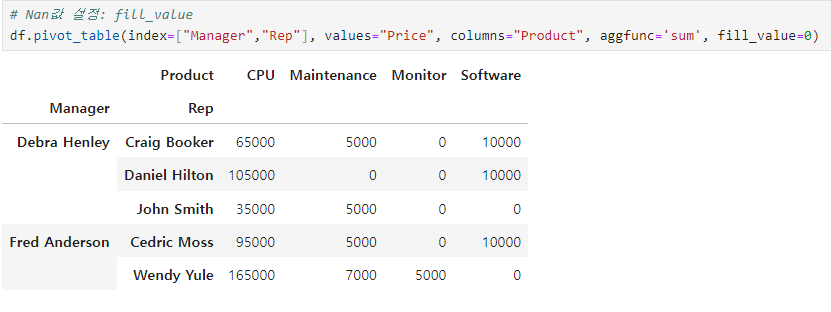
- aggfunc sum and mean, 총계(All)추가
Seaborn
기본 설정
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams['axes.unicode_minus']=False
rc("font",family="Malgun Gothic")
get_ipython().run_line_magic("matplotlib","inline")예제1: seaborn 기초
np.linspace(0, 14, 100) # 0~14에서 100개의 데이터x = np.linspace(0, 14, 100)
y1 = np.sin(x)
y2 = 2 * np.sin(x + 0.5)
y3 = 3 * np.sin(x + 1.0)
y4 = 4 * np.sin(x + 1.5)
plt.figure(figsize=(10, 6))
plt.plot(x, y1, x, y2, x, y3, x, y4)
plt.show()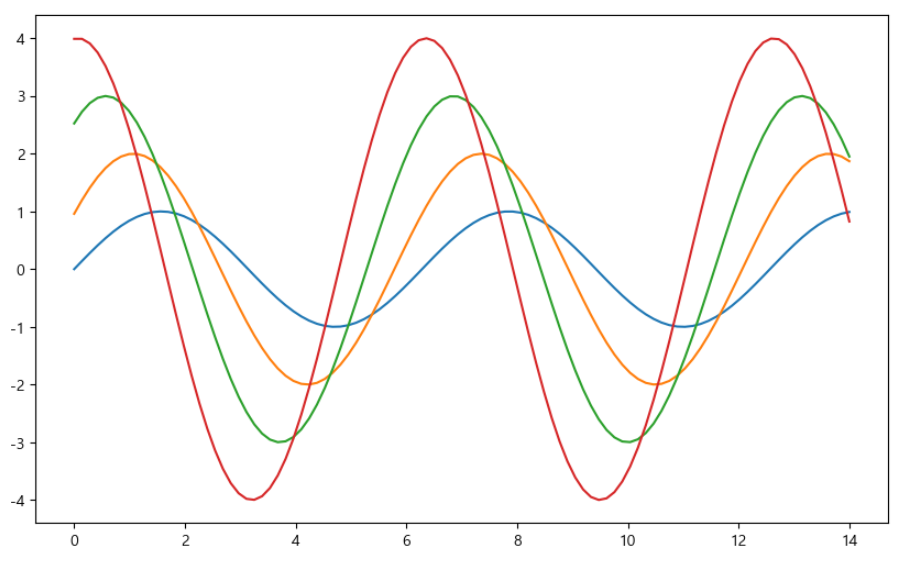
sns.set_style("white") #whitegrid, dark, darkgrid
예제2: seaborn tips data
- boxplot
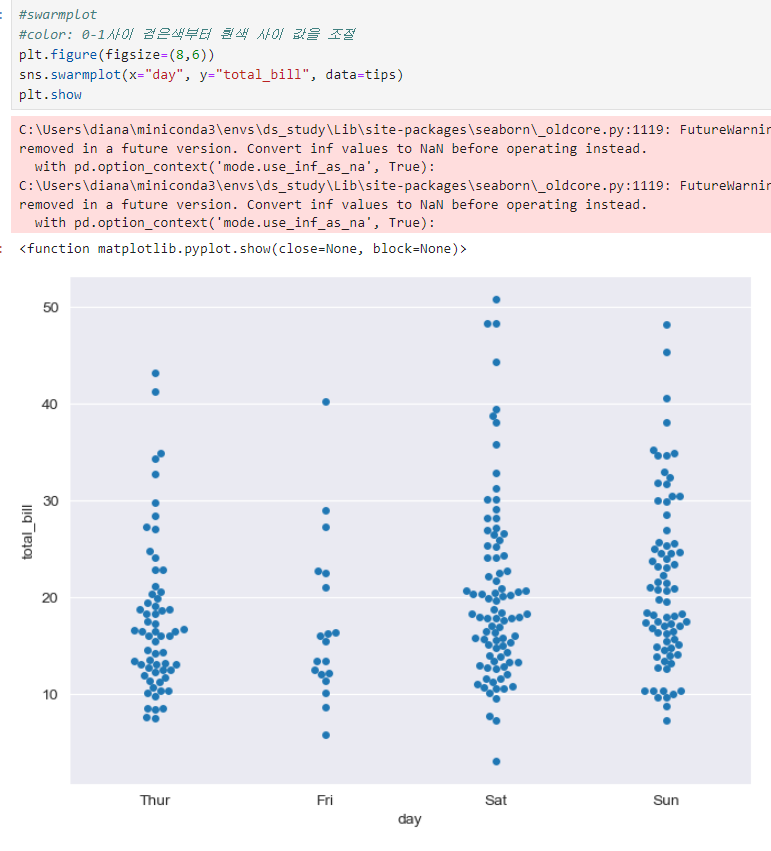
- swarmplot
- lmplot
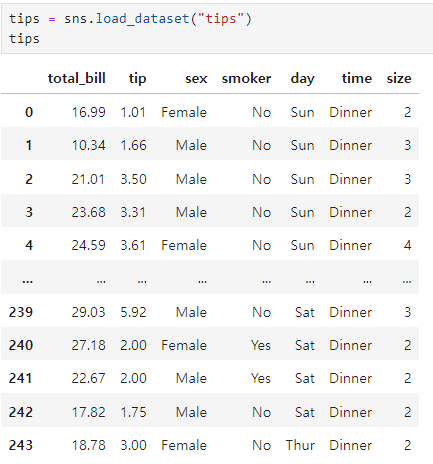
tips데이터(boxplot, swarmplot)
- 총 비용
- 팁
- 성별
- 흡연유무
- 요일
- 시간대
- 인원수
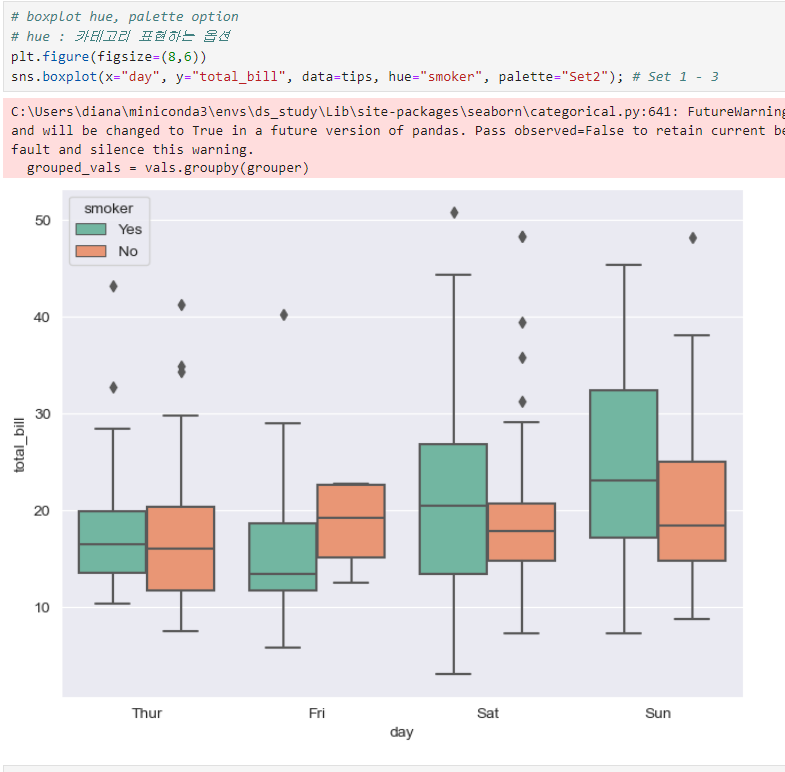
요일별 총 비용의 중간값, 최고, 최저값 보여줌
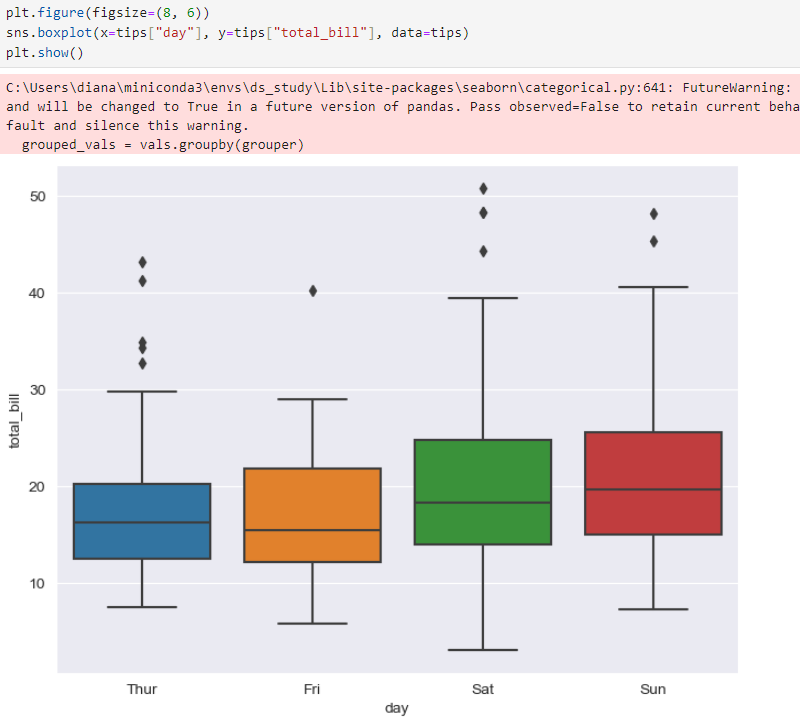
group_vals=vals.grouby(grouper)
FuturWarning이라고 오류창이 뜨는데 구글링해봐도 답을 얻지 못했다,,,궁금하다
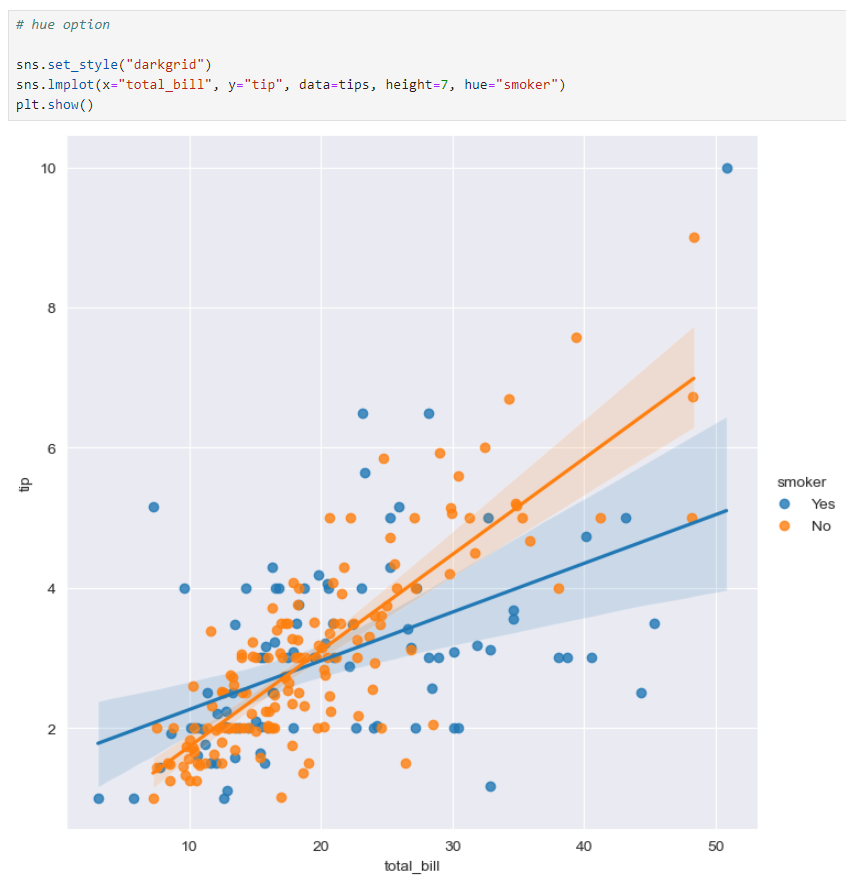
hue : 카테고리 표현하는 옵션
smoker/ non-smoker 구분하여 데이터 표현
swarmplot
요일별, 금액대별 분포를 보여줌
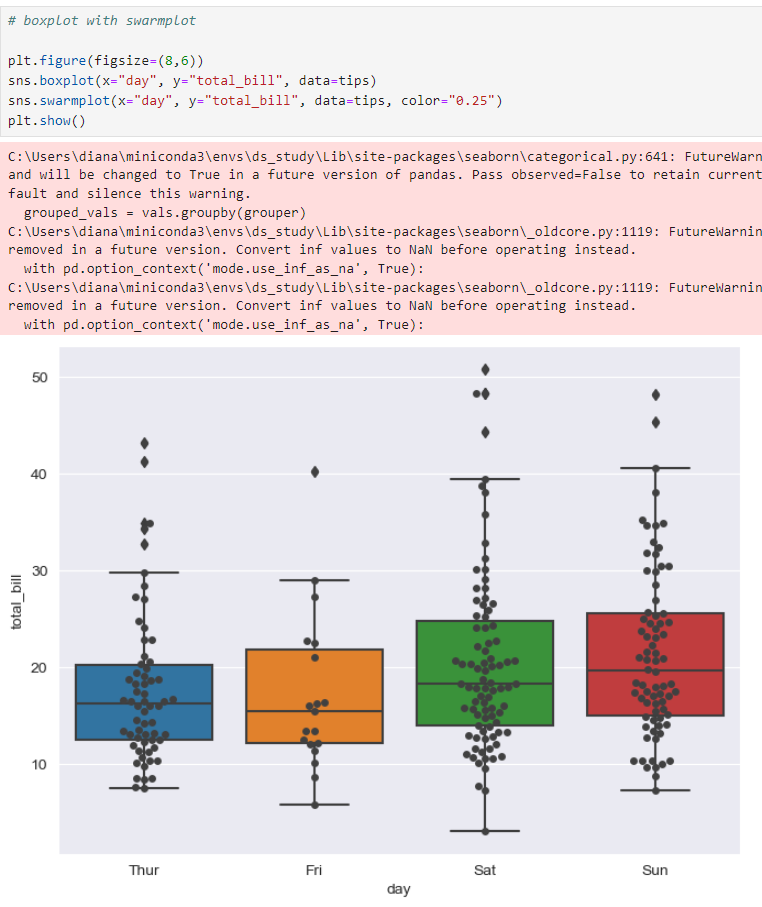
boxplot, swarmplot
두 그래프 모두 표현
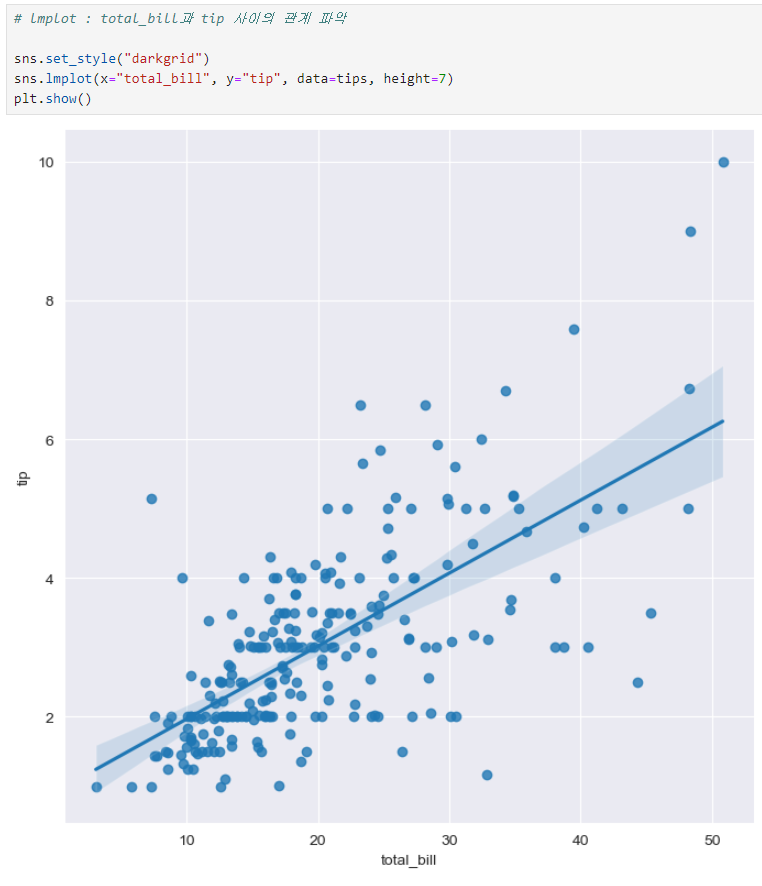
tips데이터(lmplot)
lmplot : total_bill과 tip 사이의 관계 파악
hue option 적용
예제3 : flights data(heatmap)
- 연도
- 월
- 승객수
index, columns, values 지정
month를 인덱스로 지정하여 피벗 테이블 만든 후, colormap으로 인원분포 표현
flights= flights.pivot(index="month", columns="year", values="passengers")
flights.head()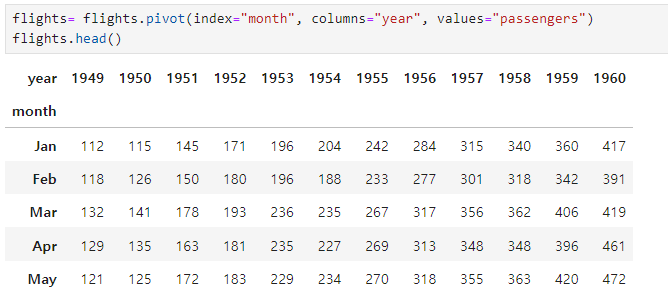
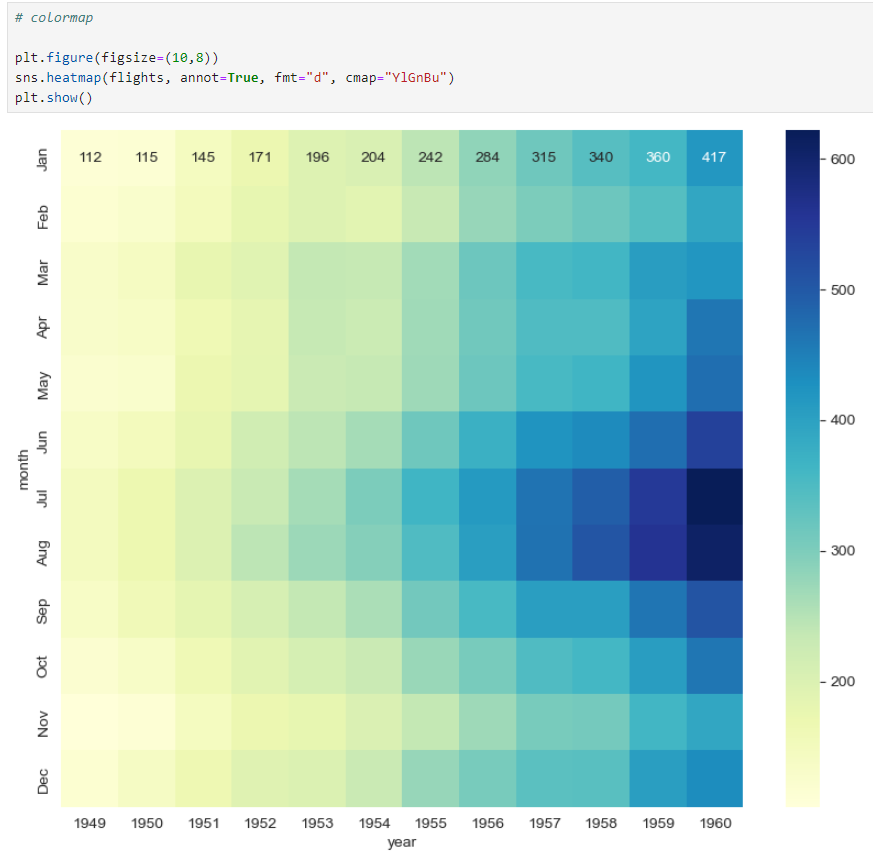
예제4: iris data(pairplot,lmplot)
- pairplot
sns.set_style("ticks")
sns.pairplot(iris)
plt.show()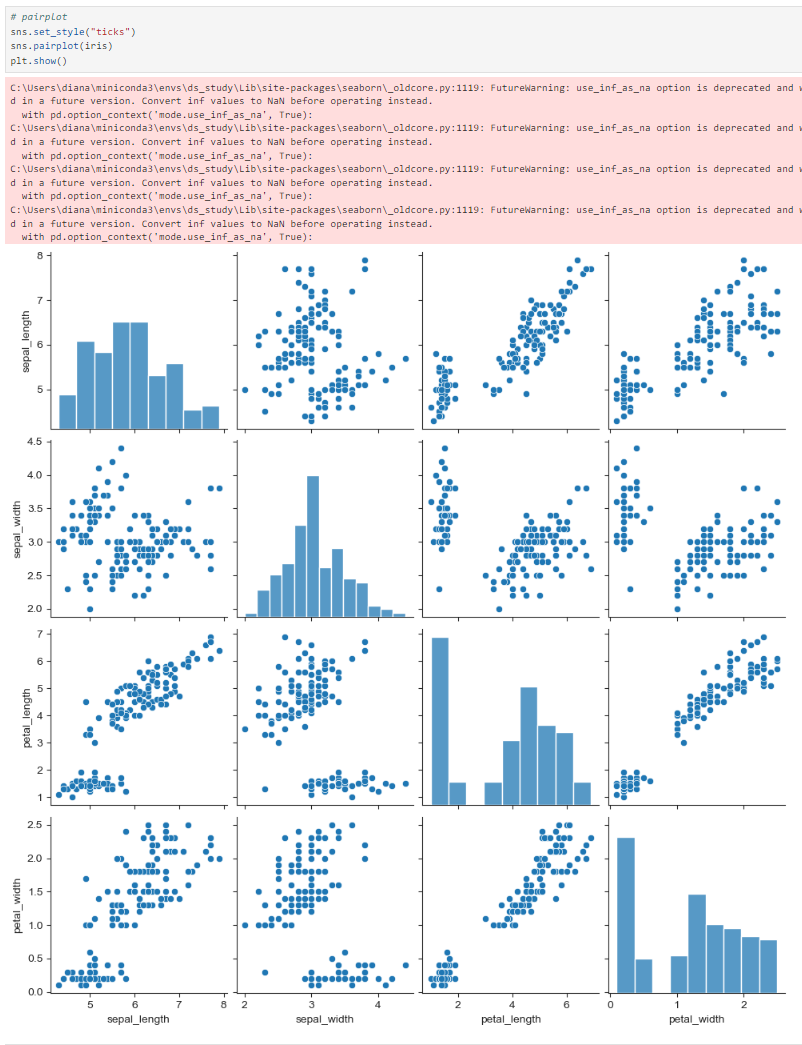
이 또한 오류의 원인을 못찾았다.
mode.use_inf_as_na
빈 값에 대한 어떠한 설정일 것 같은데,,,,궁금하다(2)
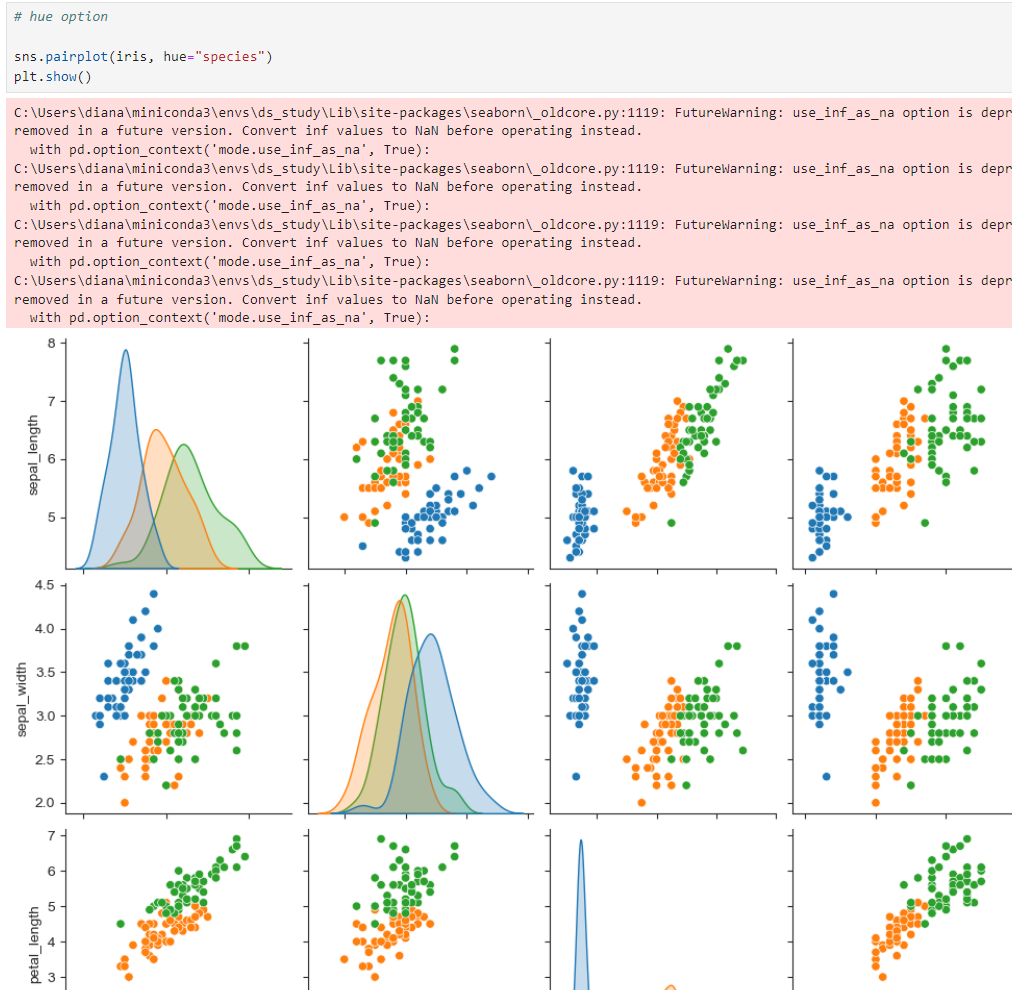
hue option 설정
- species unique()활용하여 카테고리 값 구함
- hue option 적용

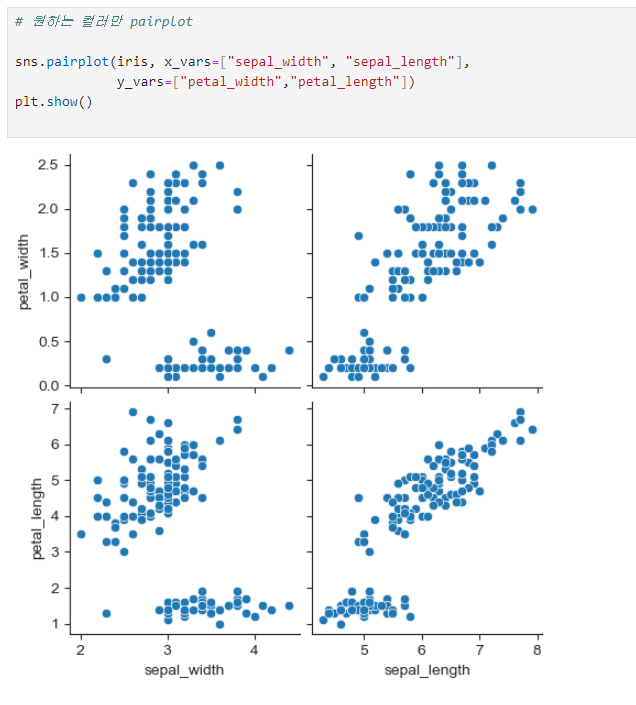
원하는 컬럼만 pairplot
x축, y축 x_vars, y_vars로 지정
예제5: anscombe data(lmplot)
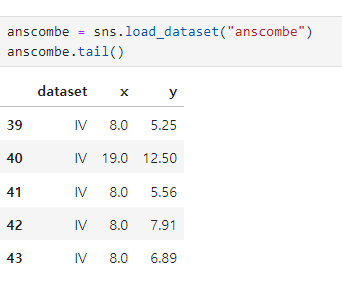
anscombe의 데이터 셋
anscombe["dataset"].unique()ci = 신뢰구간, scatter_kws : 점 사이즈
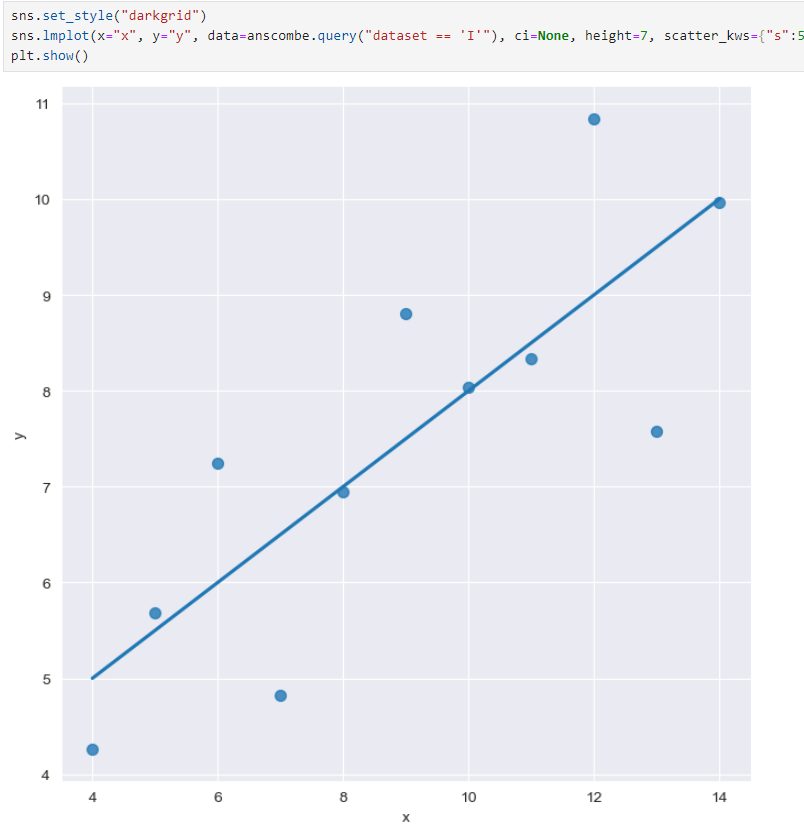
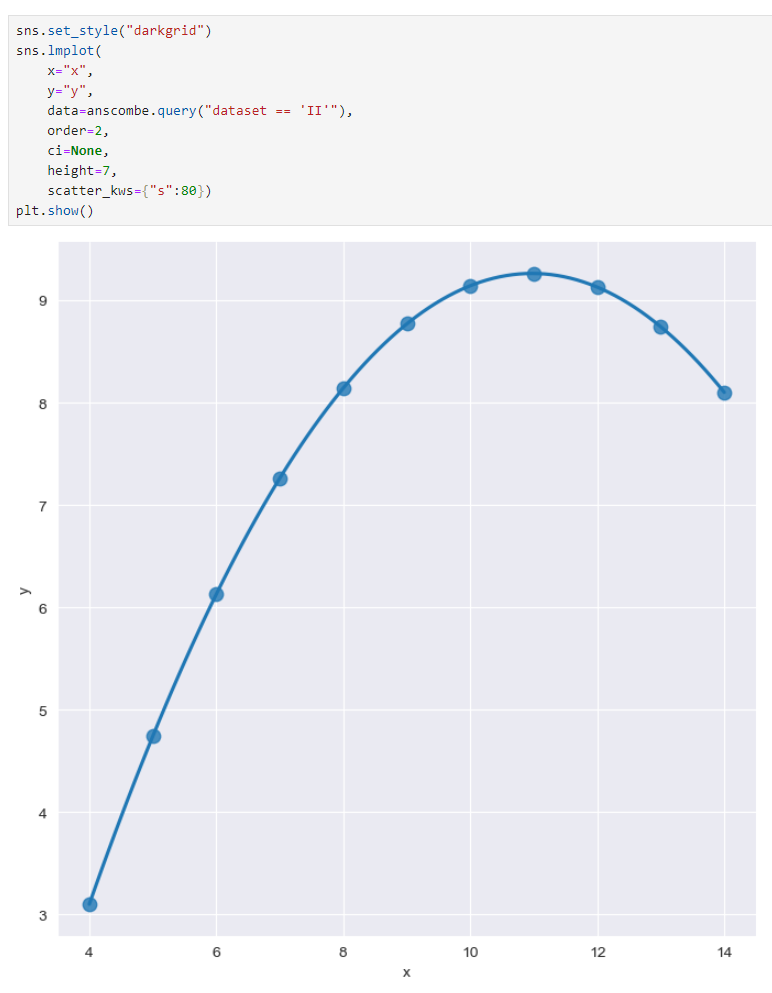
order = 1~2 설정
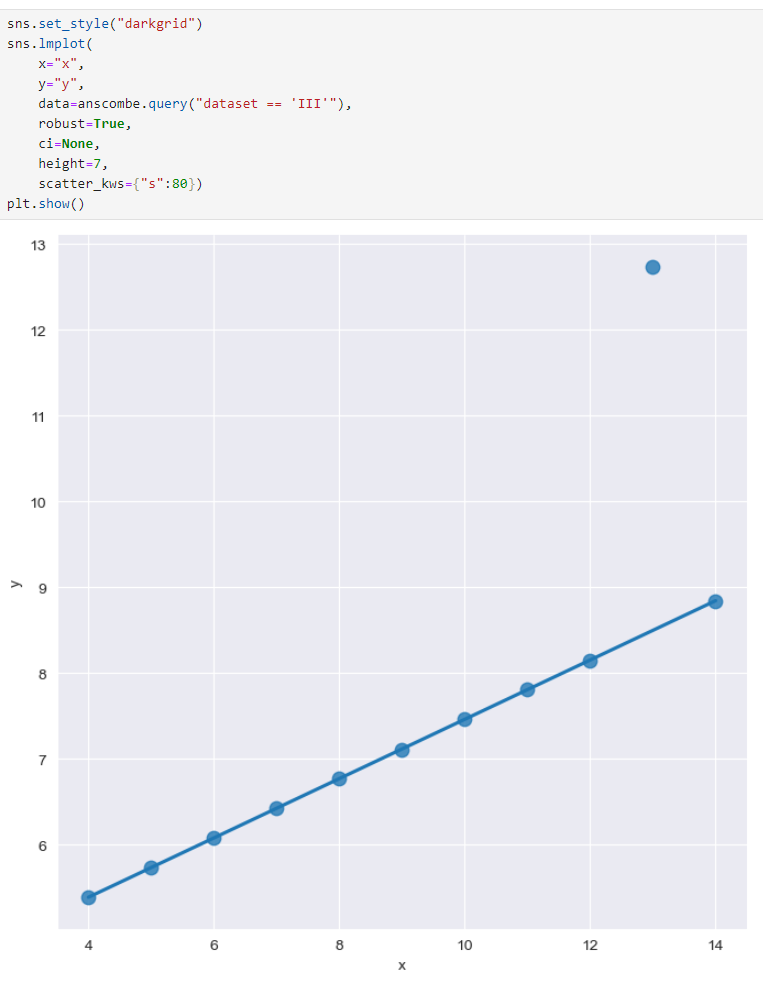
outlier : robust=True 동떨어진 데이터 설정
이 부분에서도 어떤 오류가 나서, miniconda에서 따로 설치해줬다. 이름은 잊어버렸다.
자료 출처: 제로베이스 데이터 취업 스쿨

Hi Welcome