데이터의 경향 표시
인구수와 소계 컬럼으로 scatter plot 그리기
- plt.figure(figsize=) : 그래프 사이즈
- plt.scatter(x,y,s=50):scatter plot
- plt.xlabel(), plt.ylabel() : x, y축 레이블
- plt.grid(True): 격자 그리기
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"],data_result["소계"], s= 50)
plt.xlabel("인구수")
plt.ylabel("소계")
plt.grid(True)
plt.show()
drawGraph()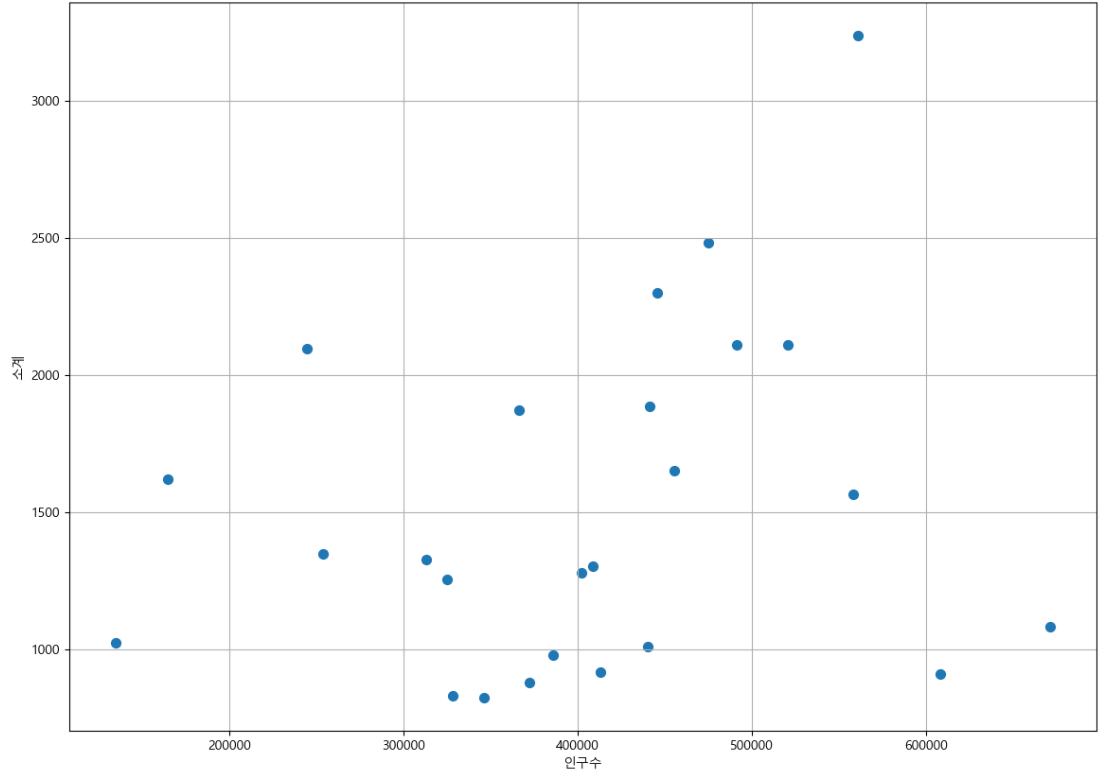
그래프 다듬기
경향과의 오차 만들기
- 경향(trend)과의 오차를 만들자
- 경향은 f1 함수에 해당 인구를 입력
- f1(data_result["인구수"])
np.polyfit, np.poly1d: 함수 만들기
fpl = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fpl)
fx = np.linspace(100000,700000, 100)오차컬럼 만들기
data_result["오차"]=data_result["소계"]-f1(data_result["인구수"])경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
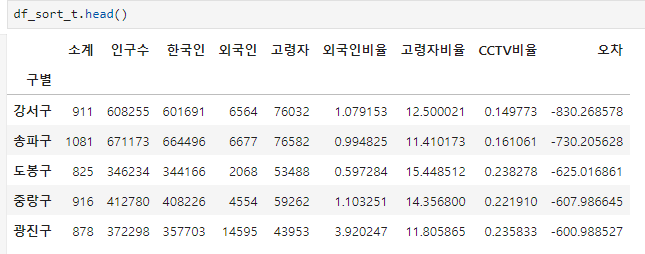
오차를 내림차순과 오름차순으로 정렬한 변수
df_sort_f = data_result.sort_values(by="오차", ascending=False)
df_sort_t = data_result.sort_values(by="오차", ascending=True)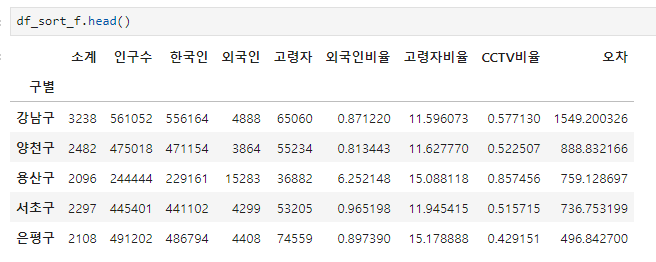
컬러맵 그래프 그리기
- plt.scatter(x, y, s=(점크기), c=,cmap=''(색 설정))
- plt.plot(x, y, ls=(선스타일), lw=(선굵기), color=(색))
- for문 사용하여 텍스트 입력
- plt.text(x위치, y위치, 넣을 텍스트)
from matplotlib.colors import ListedColormap
#colormap을 사용자 정의(user define)로 세팅
color_step=["#e74c3c","#2ecc71","#95a9a6","#3498db","#3498db"]
my_cmap = ListedColormap(color_step)def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"],data_result["소계"], s= 50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
#상위 5개
plt.text(
df_sort_f["인구수"][n]*1.02,
df_sort_f["소계"][n]*0.98,
df_sort_f.index[n],
fontsize=15)
#하위 5개
plt.text(
df_sort_t["인구수"][n]*1.02,
df_sort_t["소계"][n]*0.98,
df_sort_t.index[n],
fontsize=15)
plt.xlabel("인구수")
plt.ylabel("소계")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()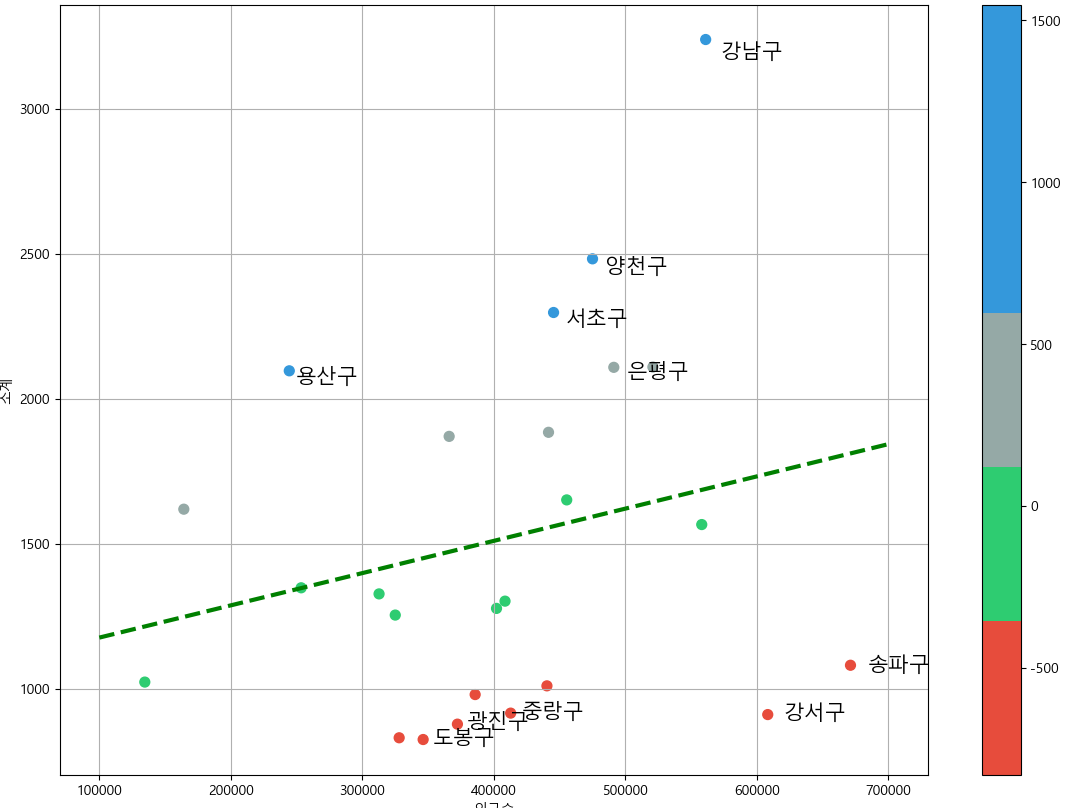

Hi Welcome