서울시 범죄 현황 데이터
1. 구별 데이터로 정리
2.범죄 데이터 정렬을 위한 데이터 정리
- 정규화, 검거율 추가, 구별 CCTV자료에서 인구수와 CCTV수 추가
3.정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 대표값으로 사용
4.서울시 범죄현황 데이터 시각화
5. 서울시 범죄 현황에 대한 지도 시각화
6. 서울시 범죄 현황 발생 장소 분석
1. 구별 데이터 정리
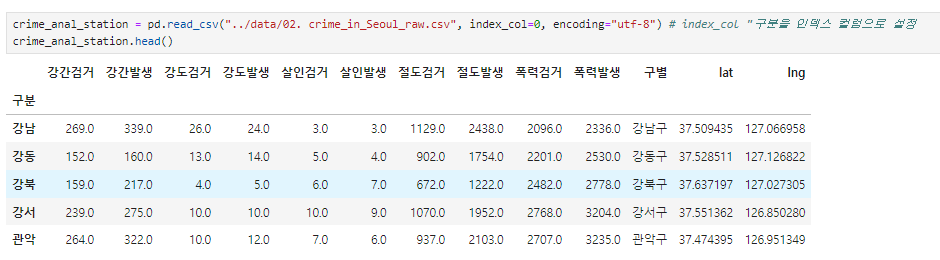
index_col "구분을 인덱스 컬럼으로 설정
crime_anal_station = pd.read_csv("../data/02. crime_in_Seoul_raw.csv", index_col=0, encoding="utf-8")
crime_anal_station.head()
컬럼'구별'을 인덱스로 설정
- pd.pivot_table(data,index=,aggfunc=)
위도, 경도 컬럼 삭제
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc="sum")
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis=1, inplace=True)
crime_anal_gu.head()검거율 컬럼 추가
target = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
num = ["강간검거","강도검거","살인검거","절도검거","폭력검거"]
den = ["강간발생","강도발생","살인발생","절도발생","폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()필요없는 컬럼 제거
crime_anal_gu.drop(["강간검거","강도검거","살인검거","절도검거","폭력검거"], axis=1, inplace=True)
crime_anal_gu.head()100보다 큰 숫자 100으로 설정
(작년 검거 데이터도 포함되어 있기 때문에 검거율이 100이상일 가능성이 있다)
crime_anal_gu[crime_anal_gu[target]>100]=100컬럼 이름 변경
crime_anal_gu.rename(columns={"강간발생":"강간", "강도발생":"강도","살인발생":"살인","절도발생":"절도","폭력발생":"폭력"}, inplace=True)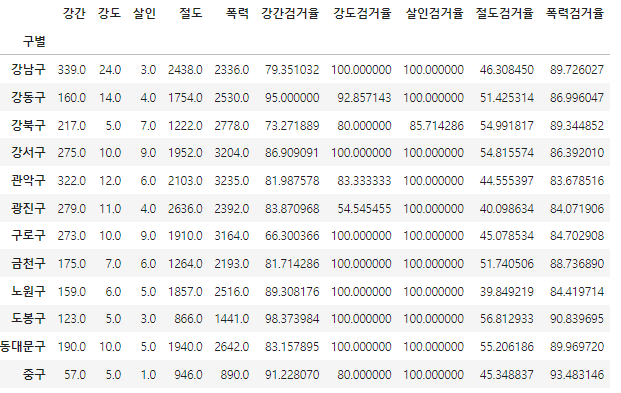
2.범죄 데이터 정렬을 위한 데이터 정리
- 정규화, 검거율 추가, 구별 CCTV자료에서 인구수와 CCTV수 추가정규화
- 컬럼 리스트 생성
- 데이터[컬럼] / 데이터[컬럼].max() 로 정규화 데이터 생성
# 정규화 : 최고값은 1, 최소값은 0
col = ["살인","강도","강간","절도","폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()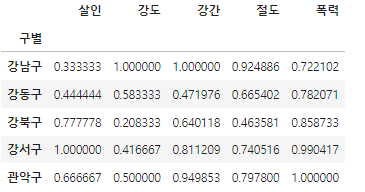
crime_anal_norm 에 검거율 추가
col2 = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()구별 CCTV 자료에서 인구수와 CCTV 수 추가
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv",index_col="구별", encoding="utf-8")
result_CCTV.head(1)
crime_anal_norm[["인구수","CCTV"]] = result_CCTV[["인구수","소계"]]
crime_anal_norm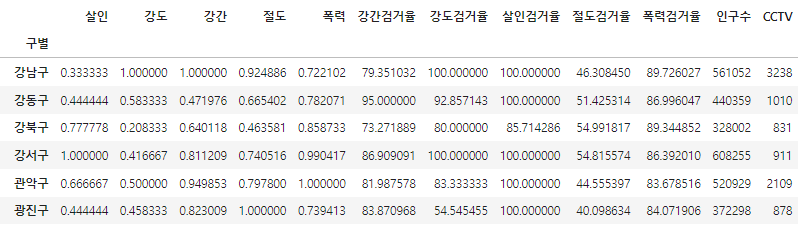
3.정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 대표값으로 사용
"범죄"컬럼 생성
5대 범죄 np.mean(data, axis=1) 로 평균값 구함
col = ["강간","강도","살인","절도","폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()검거 컬럼 생성
마찬가지로 범죄별 검거율 평균값 구함
col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm["검거"]=np.mean(crime_anal_norm[col],axis=1)
crime_anal_norm.head()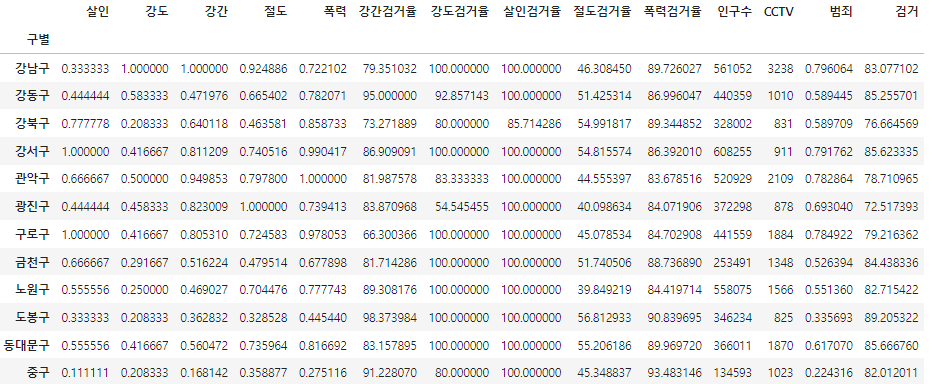
4.서울시 범죄현황 데이터 시각화
시각화 기본 세팅
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"]=False
get_ipython().run_line_magic("matplotlib", "inline")
rc("font", family="Malgun Gothic")pairplot 강도, 살인, 폭력에 대한 상관관계 확인
sns.pairplot(data=(어떤 데이터에서), vars=(어떤 변수로), kind=(어떤 종류의 그래프 'scatter', 'kde', 'hist', 'reg'), height=(크기))
sns.pairplot(data=crime_anal_norm, vars=["살인","강도","폭력"], kind="reg", height=3)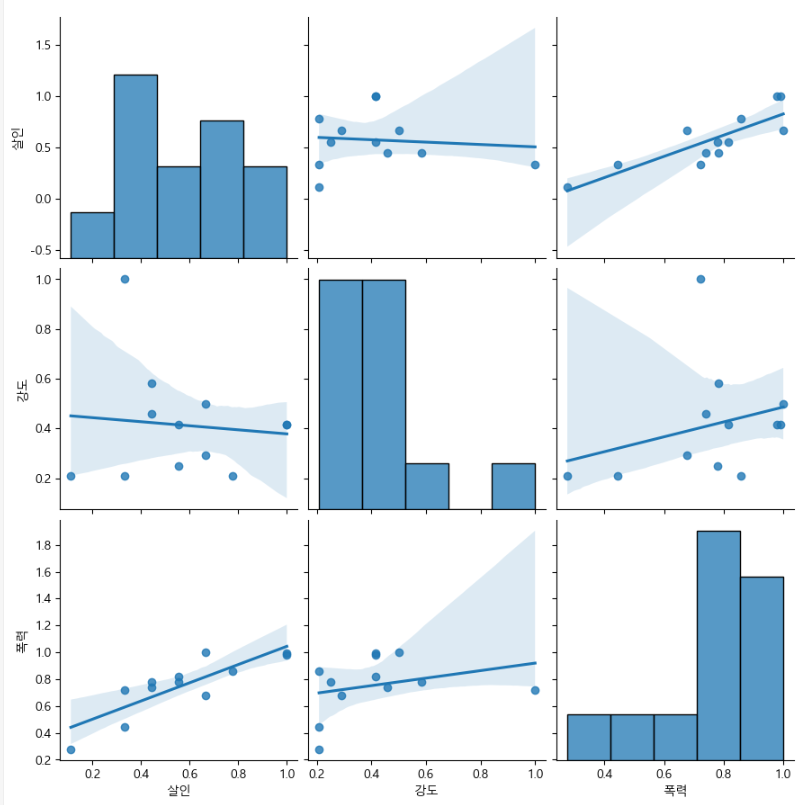
변수별 상관관계 확인 가능
인구수, CCTV와 살인, 강도의 상관관계 확인
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["살인","강도"],
kind="reg",
height=4
)
plt.show()
drawGraph()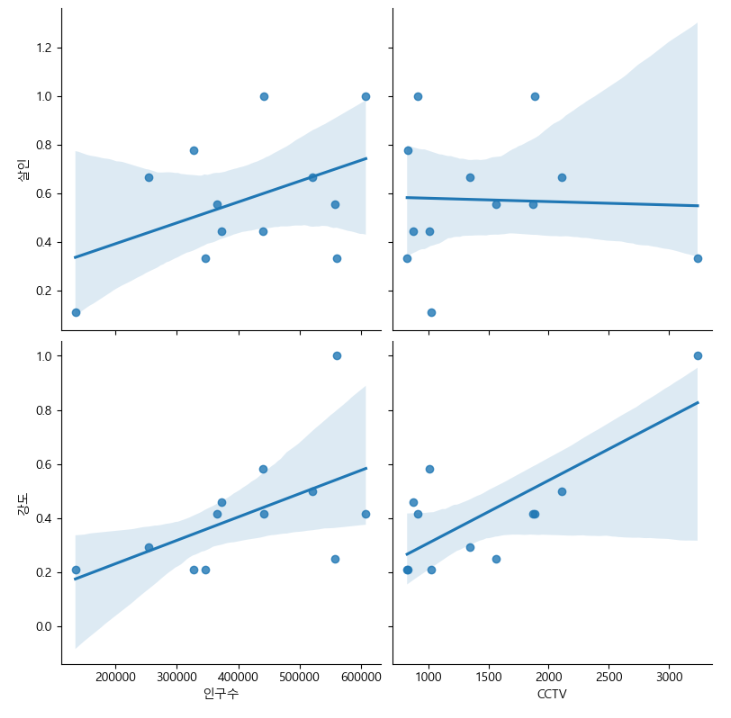
인구수, CCTV와 살인검거율, 폭력검거율의 상관관계 확인
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["살인검거율","폭력검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()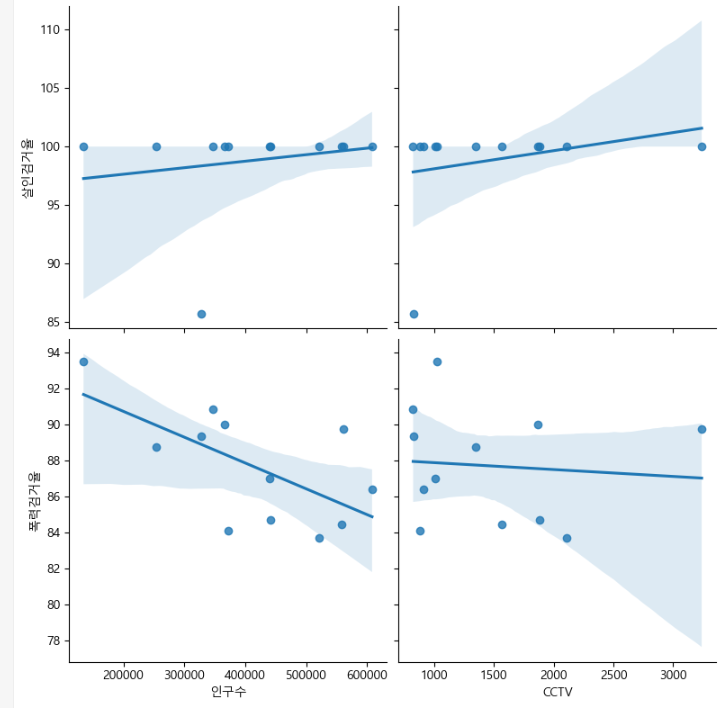
인구수, CCTV와 절도검거율, 강도검거율의 상관관계 확인
def drawGraph():
sns.pairplot(data=crime_anal_norm,
x_vars=["인구수","CCTV"],
y_vars=["절도검거율","강도검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()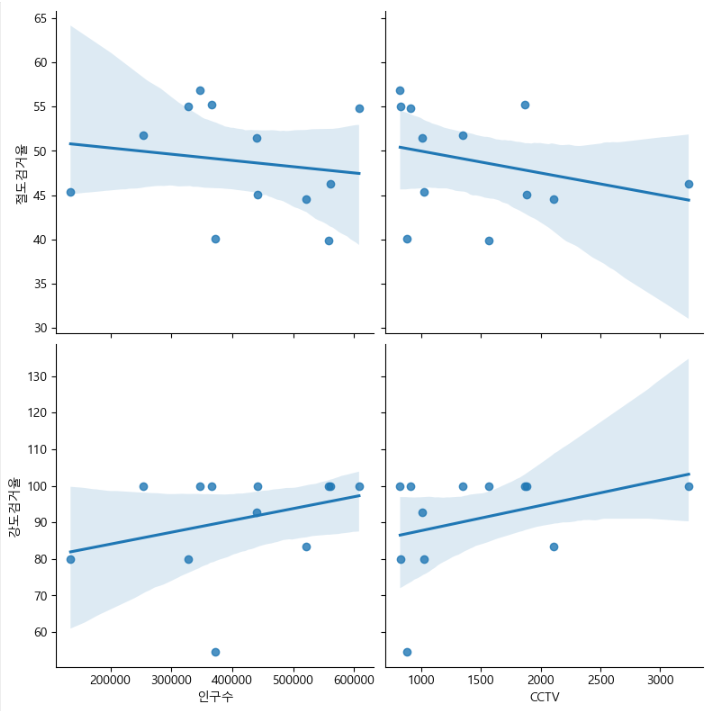
검거율 heatmap
'검거'컬럼을 기준으로 정렬
1. target_col 생성
2. 검거 컬럼을 기준으로 내림차순 정렬 (검거율이 높은 순서대로 정렬)
3. 그래프 설정
(1)plt.figure(figsize=(크기))
(2)sns.heatmap(data=, annot=(수치표현),fmt=(포맷), linewidths=(박스 사이 간격), cmap=(색))
(3)plt.title("제목")
(4)plt.show()
def drawGraph():
#데이터 프레임 생성
target_col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율","검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거", ascending=False) # 내림차순
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, #데이터값 표현
fmt="f", #d=정수형, f=실수형
linewidths=0.5, #간격 설정
cmap="RdPu",
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬")
plt.show()
drawGraph()
처음에 heatmap 글자가 잘리는 오류가 났었다.
구글링 결과 seaborn version update가 필요했고,
pip install seaborn --upgrade 를 통해 버전 13으로 업그레이드 해줬더니 글자가 모두 나왔다.
def drawGraph():
target_col = ["살인","강도","강간","절도","폭력","범죄"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="범죄", ascending=False)
plt.figure(figsize=(10,10))
sns.heatmap(data=crime_anal_norm_sort[target_col],
annot=True,
fmt="f",
linewidth=0.5,
cmap="RdPu")
plt.title("범죄비율(정규화된 발생 건수로 정렬")
plt.show()
drawGraph()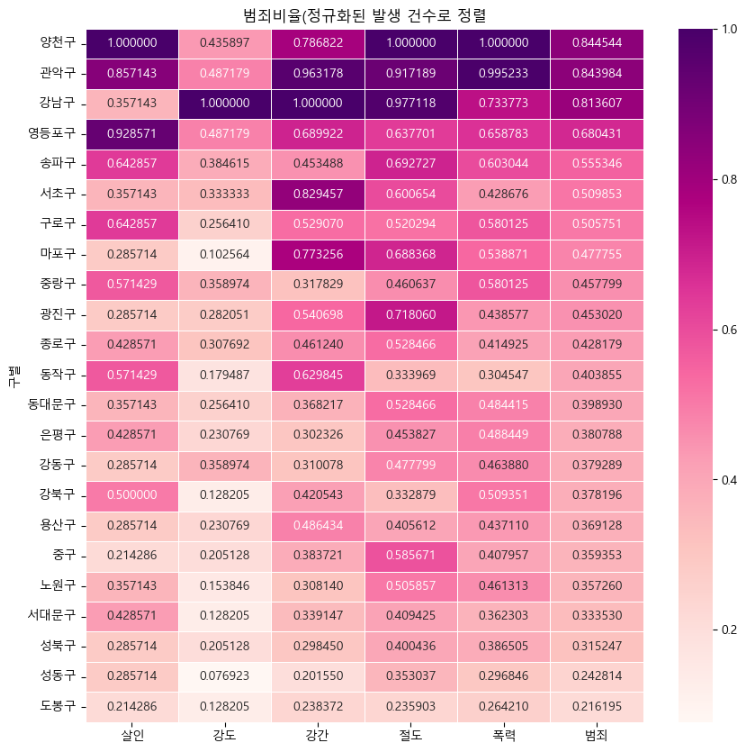
5. 서울시 범죄 현황에 대한 지도 시각화
기본 세팅
import json
import pandas as pd
import folium데이터 불러오기
crime_anal_norm = pd.read_csv("../data/Data/02. crime_in_Seoul_final.csv", index_col=0, encoding="utf-8")
geo_path = "../data/Data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))살인발생 건수 지도 시각화
변수 = folium.Map(loction=[위도, 경도],zoom_start=줌정도, tiles=지도스타일)
folium.Choropleth(geo_data=지리데이터,
data=데이터,
columns=[data.index, data[컬럼]],
key_on="feature.id",
fill_color="색상",
fill_opacity="투명도",
line_opacity="투명도",
legend_name="범례이름").add_to(변수)
my_map = folium.Map(
location=[37.5502, 126.982],
zoom_start=11,
tiles="CartoDB Positron")
folium.Choropleth(
geo_data=geo_str, #우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm["살인"], # 살인발생 건수 데이터
columns=[crime_anal_norm.index, crime_anal_norm["살인"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 살인 발생 건수"
).add_to(my_map)
my_map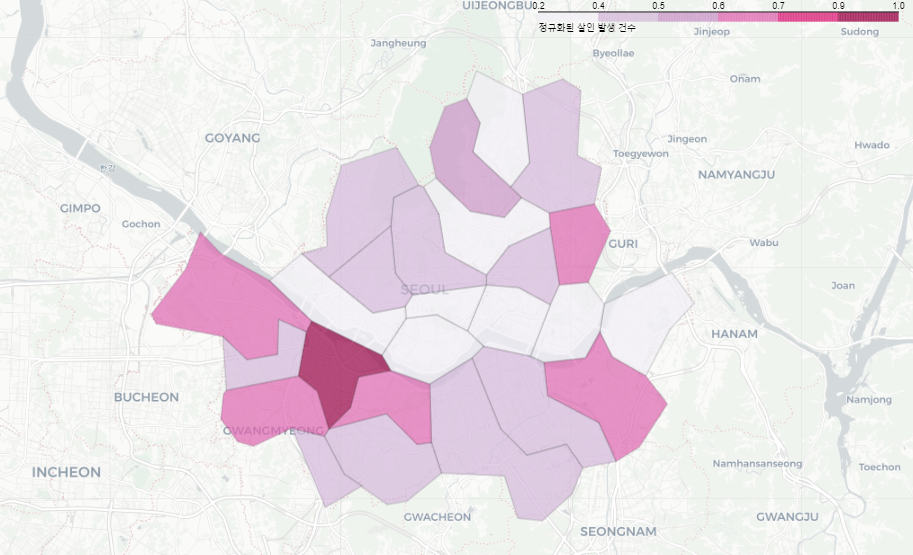
강의에서 사용한 "Stamen Toner"스타일이 현재 버전에서는 없는 것 같아, 대충 비슷한 지도로 대체했다.
인구대비 범죄 발생 건수 지도 시각화
tmp_criminal = crime_anal_norm["범죄"] / crime_anal_norm["인구수"]
tmp_criminal = crime_anal_norm["범죄"] / crime_anal_norm["인구수"]
my_map = folium.Map(
location=[37.5502, 126.982],
zoom_start=11,
tiles="CartoDB Positron")
folium.Choropleth(
geo_data=geo_str, #우리나라 경계선 좌표값이 담긴 데이터
data=tmp_criminal,
columns=[crime_anal_norm.index, tmp_criminal],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="인구수 대비 범죄 발생 건수"
).add_to(my_map)
my_map경찰서별 정보를 범죄발생과 함께 정리
경찰서 정보
crime_anal_station = pd.read_csv("../data/Data/02. crime_in_Seoul_raw.csv",encoding="utf-8")
crime_anal_station.tail(2)
범죄별 검거 컬럼 추가, 총 평균 컬럼 추가
col = ["살인검거", "강도검거", "강간검거", "절도검거", "폭력검거"]
tmp = crime_anal_station[col] / crime_anal_station[col].max()
crime_anal_station["검거"] = np.mean(tmp, axis=1) # 1은 행, 0은 열
crime_anal_station.tail()경찰서 위치 마커 표시
for idx, rows in data.iterrows():
folium.Marker(
location=[경도, 위도]).add_to(변수)
my_map =folium.Map(
location=[37.5502, 126.982], zoom_start=11
)
for idx, rows in crime_anal_station.iterrows():
folium.Marker(
location=[rows["lat"],rows["lng"]]).add_to(my_map)
my_map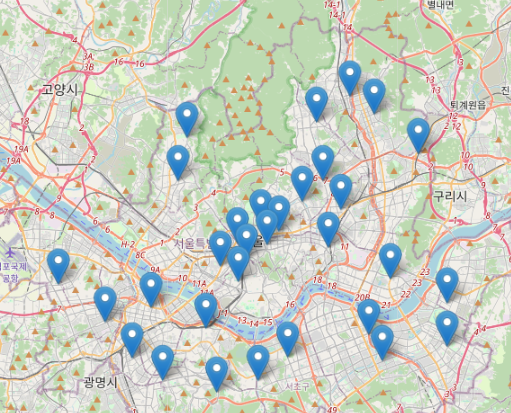
검거값에 값을 곱한 뒤 원의 넓이 적용
for idx, rows in data.iterrows():
folium.CircleMarker(
location=[경도, 위도],
radius="반지름넓이",
popup="문구",
color="색상",
fill="채우기bool",
fill_color=).add_to(변수)
my_map =folium.Map(
location=[37.5502, 126.982], zoom_start=11
)
folium.Choropleth(
geo_data=geo_str,
data=crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2).add_to(my_map)
for idx, rows in crime_anal_station.iterrows():
folium.CircleMarker(
location=[rows["lat"],rows["lng"]],
radius=rows["검거"] * 50,
popup=rows["구분"] + " : " + "%.2f" % rows["검거"],
color="#3186cc",
fill=True,
fill_color="#3186cc"
).add_to(my_map)
my_map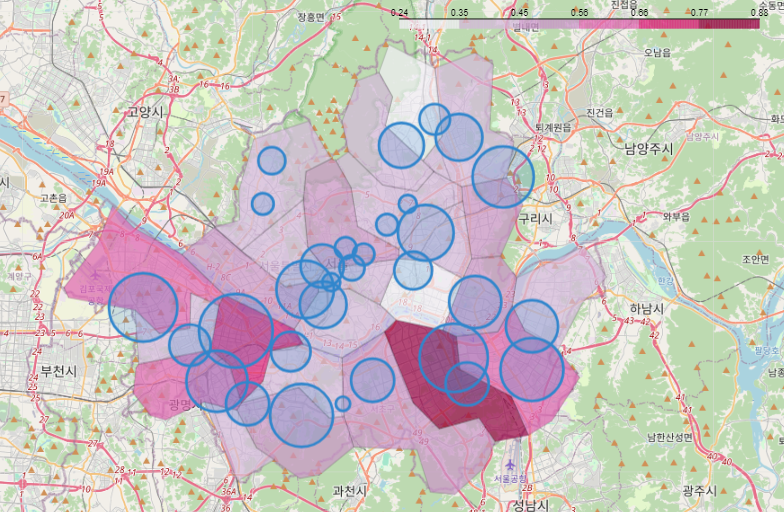
6. 서울시 범죄 현황 발생 장소 분석
데이터 불러오기
crime_loc_raw = pd.read_csv(
"../data/Data/02. crime_in_Seoul_location.csv",thousands=',', encoding="euc-kr"
)
crime_loc_raw.tail(2)피벗테이블 생성
- 인덱스, 컬럼 설정, aggfunc="sum"
crime_loc =crime_loc_raw.pivot_table(
crime_loc_raw, index="장소", columns="범죄명", aggfunc="sum"
)
crime_loc.columns = crime_loc.columns.droplevel(0)
crime_loc.tail(2)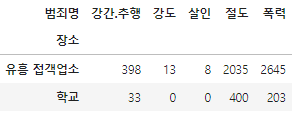
정규화
컬럼리스트 생성
crime_loc_norm = crime_loc / crime_loc.max()
col = ["살인", "강도", "강간", "절도", "폭력"]
crime_loc_norm = crime_loc / crime_loc.max() # 정규화
crime_loc_norm.head()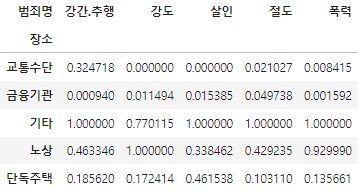
종합컬럼 생성
crime_loc_norm["종합"] = np.mean(crime_loc_norm, axis=1)
crime_loc_norm.tail(2)
범죄발생 장소 heatmap 만들기
종합 컬럼을 기준으로 내림차순으로 정렬(범죄발생율 높은 장소 순서대로 정렬)
plt.figure(figsize=크기)
sns.heatmap(data, annot=수치표현, fmt=포맷,linewidth=박스간 너비,cmap=색상)
plt.title("제목")
plt.show()
crime_loc_norm_sort = crime_loc_norm.sort_values(by="종합", ascending=False)
def drawGraph():
plt.figure(figsize=(10, 10))
sns.heatmap(
crime_loc_norm_sort,
annot=True,
fmt="f", #d : 정수형, f:실수형
linewidth=0.5,
cmap="RdPu")
plt.title("범죄발생장소")
plt.show()
drawGraph()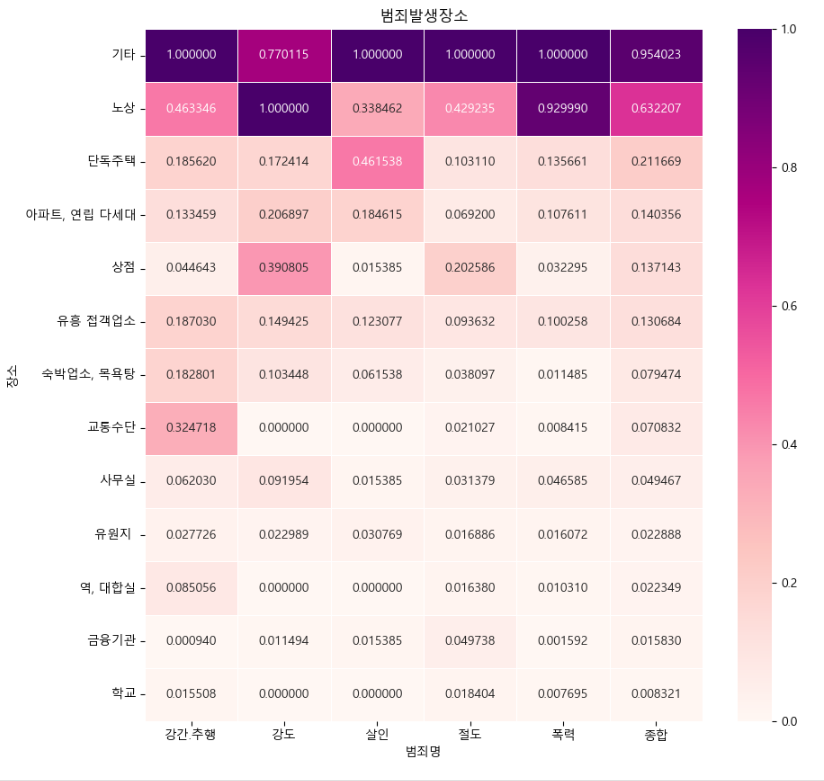
자료출처 : 제로베이스 데이터 취업 스쿨
