서울시 범죄현황 분석
1. 데이터 읽기
2. null값 빼기
3. 피벗테이블(인덱스, 컬럼 설정)
4. 구글 maps API설치
5. 피벗테이블에 구별, 경도, 위도 컬럼 추가
6. 컬럼 한줄로 정리
데이터 읽기
import numpy as np
import pandas as pdcrime_raw_data = pd.read_csv("../data/Data/02. crime_in_Seoul.csv", thousands=',', encoding="euc-kr") # 숫자값을 문자로 인식할 수 있어서 설정
crime_raw_data데이터 정보
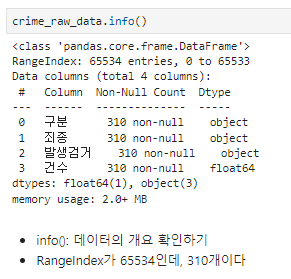
null값 빼기
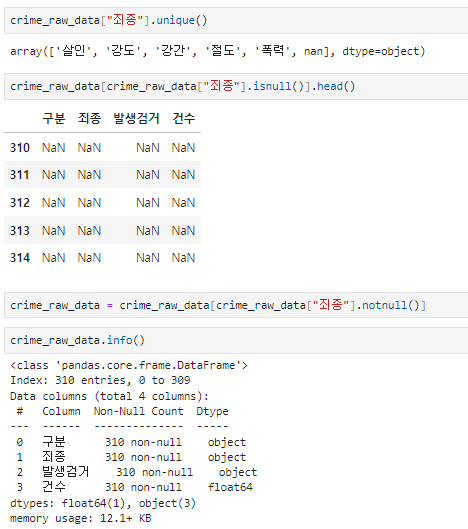
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()].unique()
.isnull(), .notnull()
피벗테이블(인덱스, 컬럼 설정)
- data.pivot_table(data, index=, columns=,aggfunc=)
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분", columns=["죄종","발생검거"],
aggfunc="sum")
crime_station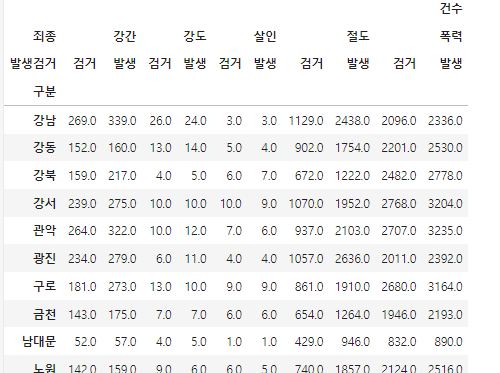
다중 컬럼
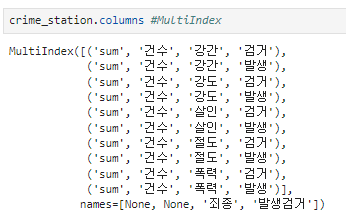
.columns.droplevel([]) : 다중 컬럼에서 특정 컬럼 제거
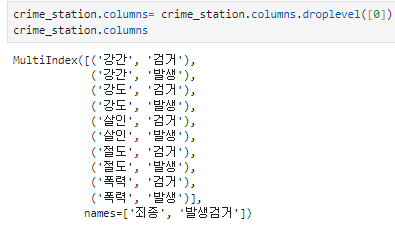
- 현재 인덱스는 경찰서 이름으로 되어 있음
- 경찰서 이름으로 구 이름을 알아내야 함
구글 maps API설치
- import googlemaps
- gmaps_key= API 인증키
- googlemaps.Client(key=gmaps_key)
gmaps.geocode("서울영등포경찰서",language="ko")

딕셔너리 값으로 결과 나옴
**위도, 경도 구하기**
```c
print(tmp[0].get("geometry")["location"]["lat"])
print(tmp[0].get("geometry")["location"]["lng"])tmp[0].get('formatted_address')결과
37.5260441
126.9008091
'대한민국 서울특별시 영등포구 국회대로 608'
피벗테이블에 구별, 경도, 위도 컬럼 추가
구별, lat, lng 컬럼 추가
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
crime_station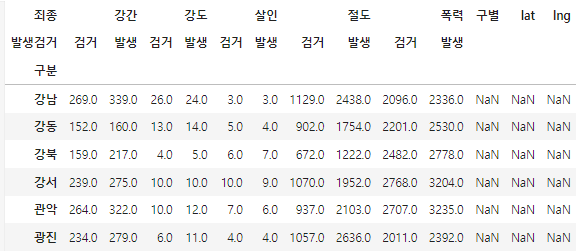
- 경찰서 이름에서 소속된 구이름 얻기
- 구이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 Nan을 모두 채워준다.
- iterrows()
count = 0
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp[0].get("formatted_address")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, "lat"] = lat
crime_station.loc[idx, "lng"] = lng
crime_station.loc[idx, "구별"] = tmp_gu.split()[2]
print(count)
count = count + 1 11번째 줄에서 list out of index 오류가 계속 났다,,
계속 해보고 코드도 강의랑 똑같이 했는데 오류해결을 못했다.
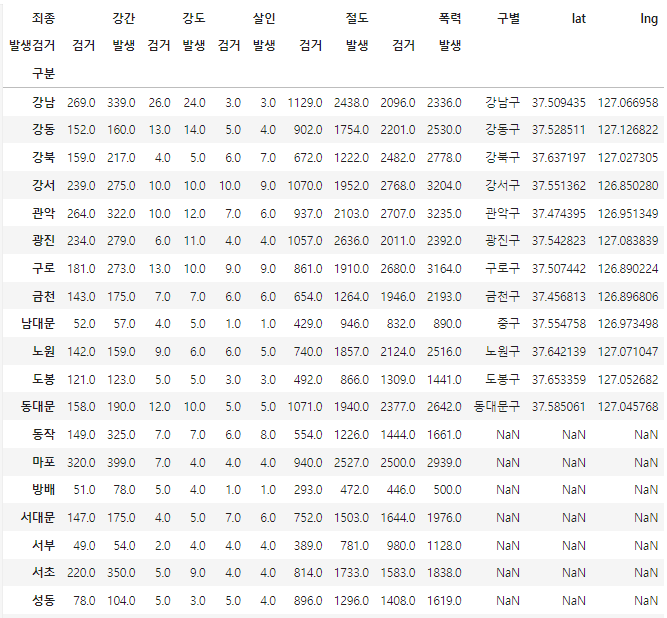
컴퓨터가 느려서 그런건가,,,잘 모르겠다.
컬럼 한줄로 정리
crime_station.columns.get_level_values(0)[2]'강도'
crime_station.columns.get_level_values(1)[1]'발생'
len(crime_station.columns.get_level_values(0))13
0에서 컬럼의 length까지 반복문
결과 :컬럼(0)[n] + 컬럼(1)[n]
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp
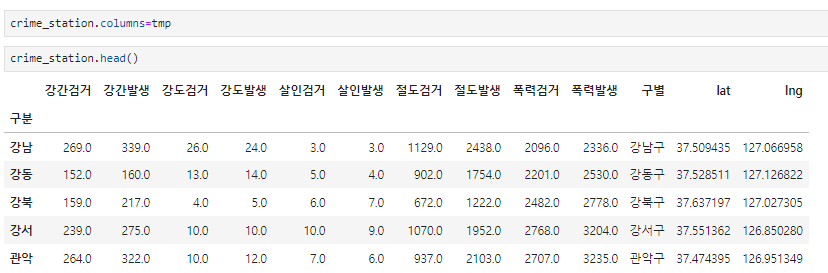
# 데이터 저장
crime_station.to_csv("../data/02. crime_in_Seoul_raw.csv", sep=',', encoding="utf-8")자료출처 : 제로베이스 데이터 취업스쿨

Hi Welcome