- tabula, 데이터 불러오기
import tabula
import pickle
# Tabula로 PDF 읽기 -> DataFrame List
ingredients_list = tabula.read_pdf('./datas/별첨1. 표준화명칭목록_220530.pdf', pages='all', lattice=True)
# DataFrame List를 Pickle로 저장
with open('./datas/ingredients_list.pkl', 'wb') as f:
pickle.dump(ingredients_list, f)1-1. 성분사전 Dataframe 만들기
# pd. concat : 리스트에 있는 여러 DataFrame을 하나의 DataFrame으로 합침
ingredients_df = pd.concat(ingredients_list, ignore_index=False)
#ignore_index=False: 이 옵션은 합치는 과정에서 원래의 index를 유지할 것인지를 결정합니다. False로 설정된 경우, 원래 DataFrame들의 index가 그대로 유지됩니다. 만약 True로 설정한다면, index는 리셋되어 0부터 다시 시작됩니다.
ingredients_df1-2. 성분사전 DataFrame 내의 Data 수정하기
-
hint1: '\r'를 대체 할 때 한글('표준 성분명', '구명칭')의 경우 띄어쓰기가 없고, 영어('표준 영문명', '구영문명)의 경우 띄어쓰기를 해야 합니다.
-
hint2: 모든 영문명의 경우 대문자로 시작합니다.
ingredients_df.reset_index(drop=True, inplace=True)ingredients_df['표준 성분명'] = ingredients_df['표준 성분명'].replace('\r', "",regex = True)
ingredients_df['구명칭'] = ingredients_df['구명칭'].replace('\r', "", regex = True)
ingredients_df['표준 영문명'] = ingredients_df['표준 영문명'].replace('\r', " ", regex = True)
ingredients_df['구영문명'] = ingredients_df['구영문명'].replace('\r', " ", regex = True)1-3. 성분사전 Dataframe 내의 Data 수정하기
pdf를 dataframe으로 전환하면서 일부 누락된 데이터가 있습니다. 아래 cell의 replace_dict는 현재값(key):변경할값(value)의 쌍으로 이루어져 있습니다. 이 replace_dict를 이용하여 성분사전 dataframe '표준 영문명' column의 값을 변경하세요.
replace_dict = {
'Acetobacter/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitumit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Acetobacter/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitumit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Saccharomyces/Licorice Root/Rehmannia Glutinosa Root/Angelica Gigas Root/Ophiopogon Japonicus Root/Atractylodes Macrocephala Root/Paeonia Lactiflora Root/Anemarrhena Asphodeloides Root/Fraxinus Excelsior Bark/Asparagus Cochinchinensis/Phellodendron Amurense': 'Saccharomyces/Licorice Root/Rehmannia Glutinosa Root/Angelica Gigas Root/Ophiopogon Japonicus Root/Atractylodes Macrocephala Root/Paeonia Lactiflora Root/Anemarrhena Asphodeloides Root/Fraxinus Excelsior Bark/Asparagus Cochinchinensis/Phellodendron Amurense Bark Ferment Extract',
'Bacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Bacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Bifida/Angelica Gigas/Angelica Tenuissima Root/Antler Velvet/Rehmannia Glutinosa Root/Atractylodes Japonica Rhizome/Cnidium Officinale Root/Cordyceps Sinensis/Ledebouriella Seseloides Root/Licorice Root/Paeonia Lactiflora Root/Panax Ginseng': 'Bifida/Angelica Gigas/Angelica Tenuissima Root/Antler Velvet/Rehmannia Glutinosa Root/Atractylodes Japonica Rhizome/Cnidium Officinale Root/Cordyceps Sinensis/Ledebouriella Seseloides Root/Licorice Root/Paeonia Lactiflora Root/Panax Ginseng Root/Phellinus Linteus/Scutellaria Baicalensis Root Ferment',
'Leuconostoc/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Leuconostoc/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
'Saccharomyces/Anemarrhena Asphodeloides Root/Angelica Gigas Root/Asparagus Cochinchinensis/Atractylodes Macrocephala Root/Fraxinus Excelsior Bark/Licorice Root/Ophiopogon Japonicus Root/Paeonia Lactiflora Root/Phellodendron Amurense': 'Saccharomyces/Anemarrhena Asphodeloides Root/Angelica Gigas Root/Asparagus Cochinchinensis/Atractylodes Macrocephala Root/Fraxinus Excelsior Bark/Licorice Root/Ophiopogon Japonicus Root/Paeonia Lactiflora Root/Phellodendron Amurense Bark Ferment Extract',
'Saccharomyces/Camellia Japonica Flower/Castanea Crenata Shell/Diospyros Kaki Leaf/Paeonia Suffruticosa Root/Rhus Javanica/Sanguisorba Officinalis Root Extract': 'Saccharomyces/Camellia Japonica Flower/Castanea Crenata Shell/Diospyros Kaki Leaf/Paeonia Suffruticosa Root/Rhus Javanica/Sanguisorba Officinalis Root Extract Ferment Filtrate',
'Lactobacillus/Honeysuckle Flower/Licorice Root/Morus Alba Root/Pueraria Lobata Root/Schisandra Chinensis Fruit/Scutellaria Baicalensis Root/Sophora Japonica Flower': 'Lactobacillus/Honeysuckle Flower/Licorice Root/Morus Alba Root/Pueraria Lobata Root/Schizandra Chinensis Fruit/Scutellaria Baicalensis Root/Sophora Japonica Flower Extract Ferment Filtrate',
'Lactobacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/Cinnamomum Cassia': 'Lactobacillus/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/Cinnamomum Cassia Ramulus Bark Ferment Filtrate',
'Saccharomyces/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia': 'Saccharomyces/Lycium Chinense Fruit/Rehmannia Glutinosa Root/Cuscuta Chinensis Fruit/Cistanche Deserticola/Zanthoxylum Piperitum Fruit/Chrysanthemum Morifolium Fruit/Poria Cocos/ Cinnamomum Cassia Ferment',
}ingredients_df['표준 영문명'] = ingredients_df['표준 영문명'].replace(replace_dict)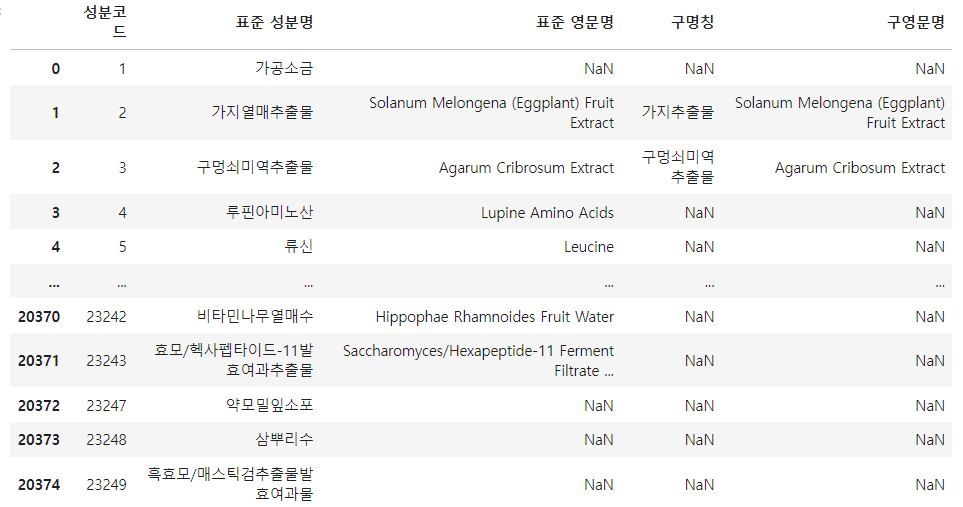
2-1. Target DataFrame 중 Ingredients Column 내의 Data 수정하기
조건1: 맨 끝에 마침표('.')가 있다면 마지막 마침표만 제거하세요
조건2: '. May Contain'를 포함하고 있다면, '. May Contain' 이후의 데이터를 제거하세요
조건3: 아래의 replace_str_dict는 현재값(key):변경할값(value)의 쌍으로 이루어져 있습니다. 이 replace_str_dict를 이용하여 데이터를 변경하세요 - 참고: replace_str_dict의 내용만 변경하면 됩니다. 다른 누락사항을 확인하여 변경할 필요는 없습니다.
replace_str_dict = {
'Algae (Seaweed) Extract': 'Algae Extract',
'Citrus Aurantifolia (Lime) Extract': 'Citrus Aurantifolia (Lime) Fruit Extract',
'Eucalyptus Globulus (Eucalyptus) Leaf Oil': 'Eucalyptus Globulus Leaf Oil',
'Galactomyces Ferment Filtrate (Pitera)': 'Galactomyces Ferment Filtrate',
'Bacillus/Soybean/ Folic Acid Ferment Extract': 'Bacillus/Folic Acid/Soybean Ferment Extract',
'Butyrospermum Parkii (Shea Butter)': 'Butyrospermum Parkii (Shea) Butter',
'Sea Salt/Maris Sal/Sel Marin': 'Sea Salt',
'Parfum/Fragrance': 'Fragrance|Perfume|Parfum',
', Fragrance': ', Fragrance|Perfume|Parfum',
}df_target['Ingredients'] = df_target['Ingredients'].replace('\.\,',',', regex=True)
df_target['Ingredients'] = df_target['Ingredients'].replace('\.$','',regex=True)
df_target['Ingredients'] = df_target['Ingredients'].replace('\. May Contain.*', '',regex=True)
df_target['Ingredients'] = df_target['Ingredients'].replace(replace_str_dict)
for key, value in replace_str_dict.items():
for idx, row in df_target.iterrows():
re_place = df_target.loc[idx, "Ingredients"].replace(key, value)
df_target.loc[idx, "Ingredients"] = re_place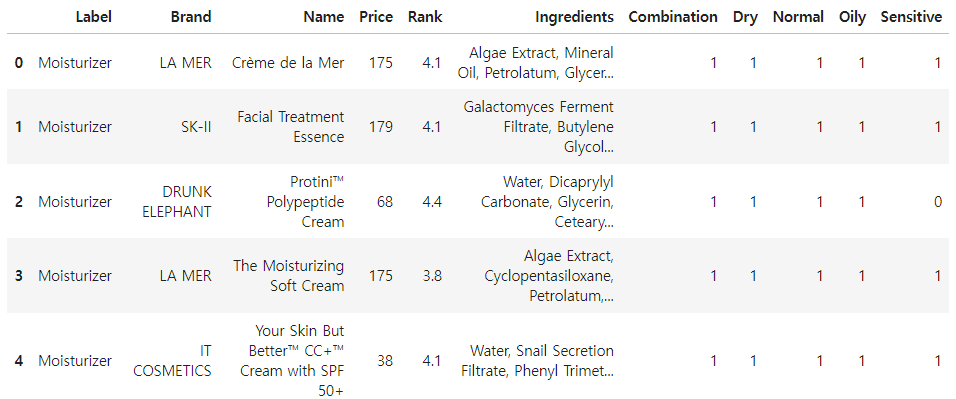
2-2. 'Ingredients Column Data 변환하기
조건1: 'Ingredients' Column의 각 데이터를 ', '(쉼표+띄어쓰기)로 분리하여 List로 변환하세요
조건2: 조건1에서 변경한 list의 각 Element 앞뒤의 공백이 있다면 공백을 삭제하세요
조건3: 'Ingredients List' Column을 새로 생성하여 조건1과 조건2에서 만든 list를 각 행에 맞게 입력하세요
ingredients_list = []
for j in range(0, len(df_target['Ingredients'])):
ingredient = df_target['Ingredients'][j].split(', ')
for n in range(0, len(ingredient)):
ingredient[n] = ingredient[n].strip()
ingredients_list.append(ingredient)
df_target['Ingredients List'] = ingredients_list
3-1. Ingredient List를 Mapping하여 Code List 컬럼 만들기
- 조건1: Ingredients List에 대응하는 Code List의 순서는 같아야 합니다.
- hint1: '표준 영문명'에서 찾지 못한다면 '구영문명'으로도 찾아보세요
- hint2: 대문자-소문자 차이가 있을 수 있습니다.
def map_code_list(ingredients_list):
code_list = []
for i in ingredients_list:
code = ingredients_df[(i.lower() == ingredients_df['표준 영문명'].str.lower()) | (i.lower() == ingredients_df['구영문명'].str.lower())]['성분코드'].values
if len(code) > 0:
code_list.append(code[0])
else:
code_list.append(None)
return code_list
new_code_list = []
for n in range(0, len(ingredients_list)):
new_code_list.append(map_code_list(ingredients_list[n]))
df_target['Code List'] = new_code_list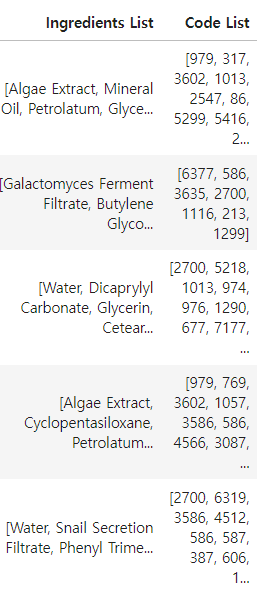
3-2 조건에 만족하는 code를 찾아 Dataframe 생성하기
이 DataFrame에서 나타난 Code 중 각 행 내에서 중복 없이 두 번 나온 Code는 [3, 9, 23, 34, 57, 234] 이고, 이 중 오름차순으로 첫번째부터 다섯번째까지의 수는 [3, 9, 23, 34, 57] 입니다.
참고
'3'의 경우 2번 행과 3번 행에서 나왔습니다.
0번 행의 '12'의 경우 중복하여 나왔으므로, 한 번 나온 것으로 count 합니다.
tmp_list = []
for n in range(0, len(df_target['Code List'])):
for j in set(df_target['Code List'][n]):
tmp_list.append(j)
count_list = []
for i in tmp_list:
if tmp_list.count(i) == 2:
count_list.append(i)
count_list.sort()
count_list = count_list[::2]
result_df = ingredients_df[ingredients_df['성분코드'].isin(count_list[0:5])]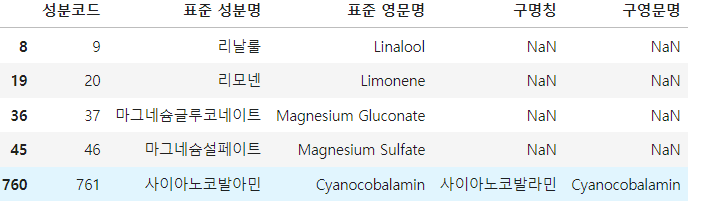
출처 : 제로베이스 데이터 취업 스쿨
