- DataFrame 불러오기 & 전처리
import pandas as pd
df = pd.read_table('../data/datas-20240207T090241Z-001/datas/report.txt', encoding='utf-8')
df.drop([0, 1, 2], axis=0, inplace=True)
df.reset_index(drop=True, inplace=True)
df.head()1-2. 컬럼명 변경하기
df.rename(columns={
df.columns[0] : '기간',
df.columns[1] : '자치구',
df.columns[2] : '세대',
df.columns[3] : '합계',
df.columns[4] : '남자',
df.columns[5] : '여자',
df.columns[6] : '한국인 계',
df.columns[7] : '한국인 남자',
df.columns[8] : '한국인 여자',
df.columns[9] : '등록외국인 계',
df.columns[10] : '등록외국인 남자',
df.columns[11] : '등록외국인 여자',
df.columns[12] : '세대당인구',
df.columns[13] : '65세이상고령자'
}, inplace=True)
df_target = df
df_target.head()
1-3. 천단위 구분자 제거하고 data type을 int또는 float로 변경하기
target_columns = ['세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자']
for column in target_columns:
df_target[column] = df_target[column].str.replace(',','').astype('int64')
df_target['세대당인구'] = df_target['세대당인구'].astype('float')
df_target.head()
2-1. 권역 컬럼 추가하기
df_target['권역']=''
for n in range(0,len(df_target['자치구'])):
for key, value in region_dict.items():
if df_target['자치구'][n] in value:
df_target.loc[n,'권역'] = key
else:
continue
df_target2-2. pivot_table 생성 및 권역별 합계 구하기
df_pivot = pd.pivot_table(df_target, index='권역', values=['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'], aggfunc='sum')
df_pivot.sort_values(by='합계',ascending=False, axis=0, inplace=True)
df_pivot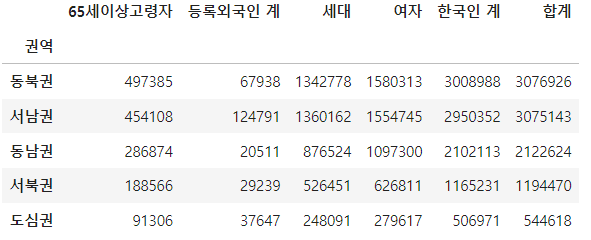
2-3. '고령자','외국인','여성','세대당' 인구 컬럼 만들기, 외국인 비율순으로 오름차순
df_pivot['고령자비율'] = df_pivot['65세이상고령자'] / df_pivot['합계'] * 100
df_pivot['외국인비율'] = df_pivot['등록외국인 계'] / df_pivot['합계'] * 100
df_pivot['여성비율'] = df_pivot['여자'] / df_pivot['합계'] * 100
df_pivot['세대당인구'] = (df_pivot['합계'] - df_pivot['등록외국인 계']) / df_pivot['세대'] * 100
df_pivot.sort_values(by='외국인비율', ascending=True, axis=0, inplace=True)
df_pivot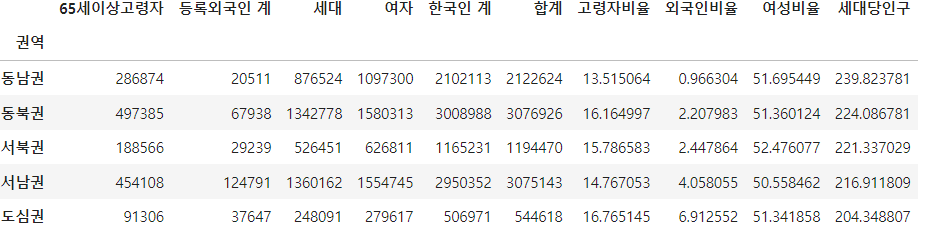
2-4. df_target데이터 프레임에 비율 추가 후, 세대당 인구순으로 내림차순
df_target['고령자비율'] = df_target['65세이상고령자'] / df_target['합계'] * 100
df_target['외국인비율'] = df_target['등록외국인 계'] / df_target['합계'] * 100
df_target['여성비율'] = df_target['여자'] / df_target['합계'] * 100
df_target.sort_values(by='세대당인구', ascending=False, axis=0, inplace=True)
df_target
2-5. df_pivot을 활용하여 고령자 비율, 외국인 비율, 여성비율, 세대당인구 간의 피어슨 상관계수 행렬 구하기
select_columns= ['고령자비율', '외국인비율', '여성비율', '세대당인구']
pivot_corr = df_pivot[select_columns].corr()
pivot_corr3-1. 자치구별 고령자비율을 내림차순에 따라 barh 그래프로 시각화
# 한글 설정
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
# %matplotlib inline
plt.rcParams['axes.unicode_minus']=False
rc("font", family='Malgun Gothic')plt.barh(df_target['자치구'], df_target['고령자비율'].sort_values(), label='고령자비율')
plt.legend(loc='lower left')
plt.title('구별 고령자비율')
plt.show()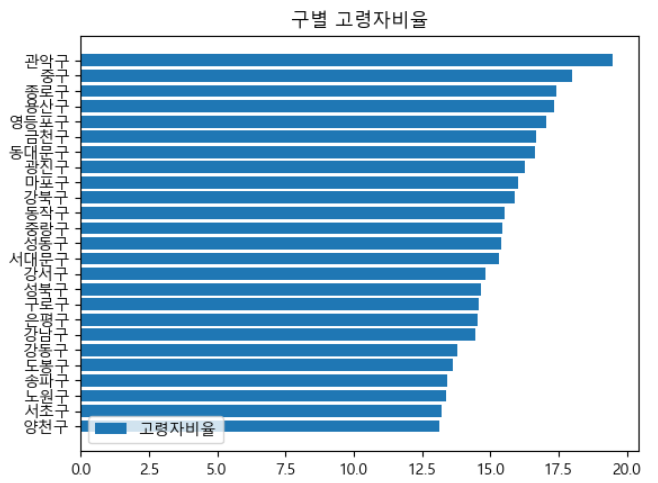
3-2. 권역별 등록외국인 계를 PIE chart로 시각화
df_pivot['등록외국인 계'].plot.pie()
plt.legend(df_pivot.index, loc='upper right')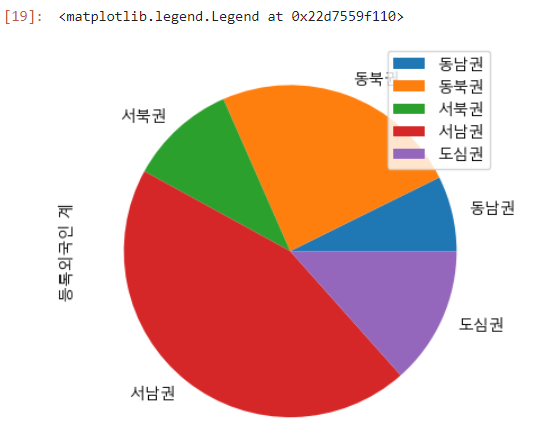
3-3. 권역별 외국인비율을 Box plot으로 시각화
df_target.boxplot(column='외국인비율', by='권역', figsize=(12, 8))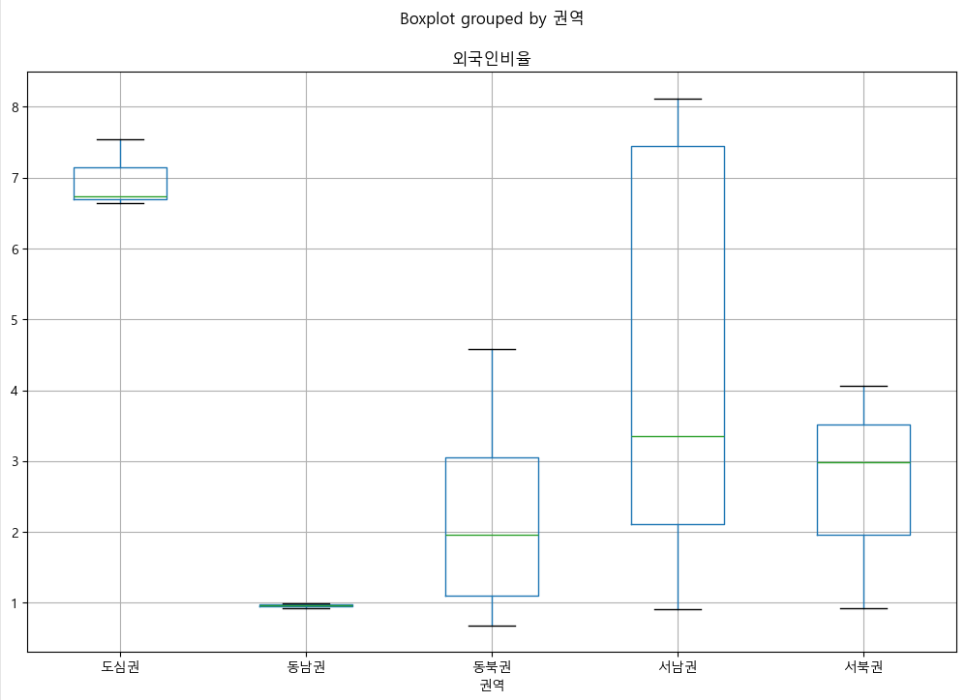
3-4. 자치구별 외국인비율-세대당인구를 Scatter plot에 나타내고, 상관관계에 따른 Regression Line시각화
sns.regplot(x=df_target['외국인비율'], y=df_target['세대당인구'], data=df_target)
plt.show()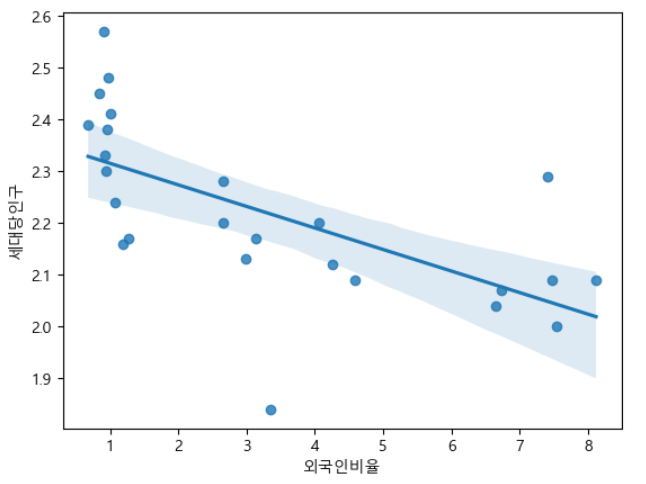
출처: 제로베이스 데이터 취업스쿨

Hi Welcome