지니뮤직 사이트의 음악차트 크롤링하기
도구 준비
import requests
import pandas as pd
from bs4 import BeautifulSoup HTML문서 가져오기
url = 'https://www.genie.co.kr/chart/top200?ditc=D&ymd=20211103&hh=13&rtm=N&pg=1'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
ginie = requests.get(url,headers = headers)필요한 부분 가져오기
soup = BeautifulSoup(ginie.content,'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')특정 정보 가져오기
.text: 태그 내부의 내용만 가져옴strip(): 문자 앞뒤의 공백 제거
title_list = []
singer_list = []
rank_list = []
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip().strip('19금').strip()
singer = tr.select_one('td.info > a.artist.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
title_list.append(title)
singer_list.append(singer)
rank_list.append(rank)
print(title,singer,rank) #내용 확인 해보기!데이터 프레임 생성
df = pd.Dataframe({'title': title_list,'singer':singer_list,'title':title_list})
#순서대로 입력되므로 타이틀을 빼주어도 index 값으로 확인 가능
df.sample(5)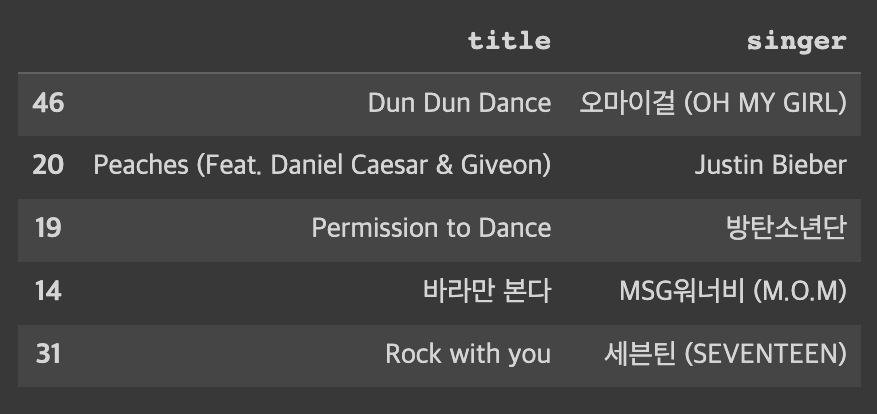
함수 생성
- 총정리 : 날짜에 따른 음악 순위 데이터프레임을 생성하는 함수 만들기
def music_top50 (date):
url = 'https://www.genie.co.kr/chart/top200?ditc=D&ymd='+str(date)+'&hh=13&rtm=N&pg=1'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
ginie = requests.get(url,headers = headers)
soup = BeautifulSoup(ginie.content,'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
title_list = []
singer_list = []
#rank_list = []
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip().strip('19금').strip()
singer = tr.select_one('td.info > a.artist.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
title_list.append(title)
singer_list.append(singer)
#rank_list.append(rank)
df = pd.DataFrame({'title': title_list,'singer':singer_list})
return df- 함수 사용
today_musiclist = music_top50(20220903)
today_musiclist.head(5)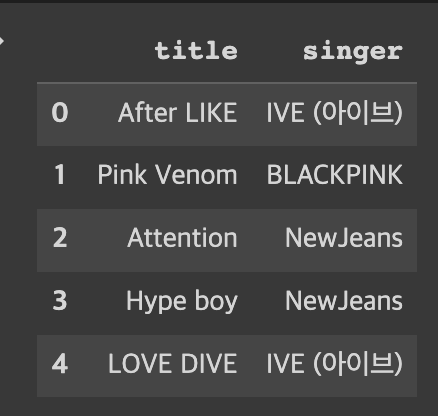

Hello, I'm libramin!