
Package
누군가 이미 만들어놓은 함수, 클래스 덩어리 -> 'import'로 사용 선언
Pandas DataFrame
파이썬 데이터 분석을 위한 필수 패키지
import pandas as pd
#판다스를 사용할 때 pd라는 약자로 사용하겠다.판다스 데이터프레임 만들기
- 데이터 프레임 생성방법
데이터프레임명 = pd.DataFrame({
'columeName1' : [row1,row2,row3...],
...
'columeName2' : [row1,row2,row3...],
})- 예제
import pandas as pd
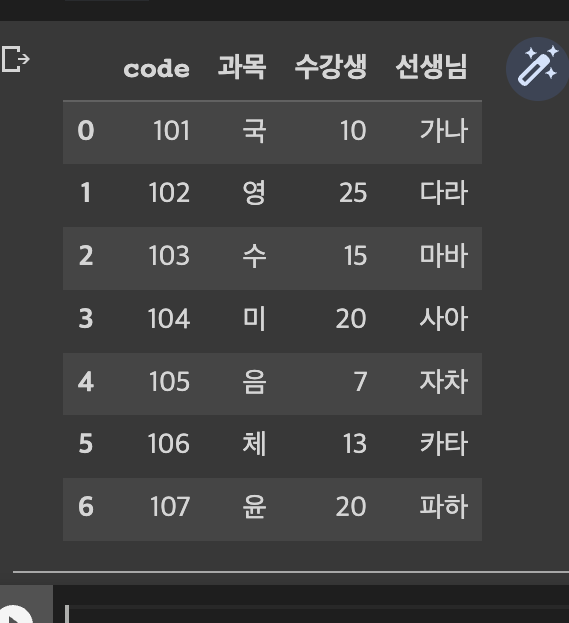
items = pd.DataFrame({
'code' : [101,102,103,104,105,106,107],
'과목' : ['국','영','수','미','음','체','윤'],
'수강생' : [10,25,15,20,7,13,20],
'선생님' : ['가나','다라','마바','사아','자차','카타','파하']
})
items
- 출력결과
데이터프레임 여러가지 사용 방법
- 일부 출력
items.head() #데이터의 상위 5개 출력
items.tail() #데이터의 하위 5개 출력
items.sample(3) #데이터의 랜덤 3개 출력- 데이터프레임 합치기
# 데이터프레임 2개를 연결
total_df = pd.concat([df1, df2])
total_df
#두 데이터 프레임 2개가 합쳐져서 출력된다.cvs
데이터 프레임 -> cvs 저장
total_df.to_csv('data.csv',index=False)
#데이터프레임을 'data.csv'로 저장해서 추후에 사용한다.
#csv는 엑셀의 한 종류라고 생각해도 된다.
#index=False 는 인덱스 번호 없이 저장하겠다.cvs -> 데이터프레임으로 불러오기
new_df = pd.read_table('data.csv',sep=',')
#sep: ,를 기준으로 열을 나누겠다.
#읽어와서 new_df에 할당한다.

Hello, I'm libramin!