
Newspaper3k
뉴스 데이터를 크롤링을 위한 패키지
package 사용하기
!pip install newspaper3k # newspaper3k 패키지 설치
from newspaper import Article # newspaper패키지의 Article모듈 임포트제목과 본문 찾아내기
# 파싱할 뉴스 기사 주소
url = 'https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=101&oid=030&aid=0002881076'
article = Article(url, language='ko') # 한국어이므로 language='ko'설정
article.download() #해당 뉴스 다운로드
article.parse() #뉴스 제목과 본문을 찾아내는 분석 진행!print(article.title) #기사의 제목 출력
print(article.text) #기사의 본문 출력네이버 뉴스 크롤링 해 보기
필요한 패키지 준비
!pip install beautifulSoup4
!pip install newspaper3k
import requests # requests라는 패키지를 임포트
# pandas라는 패키지를 임포트하는데 앞으로 pd로 부르겠음
import pandas as pd
# newspaper라는 패키지로부터 Article이라는 모듈을 임포트
from newspaper import Article
# bs4라는 패키지로부터 BeautifulSoup라는 모듈을 임포트
from bs4 import BeautifulSoup 변수생성
page_num = 1
code = 101
date = 20200506
url = 'https://news.naver.com/main/list.naver?mode=LSD&mid=sec&sid1='+str(code)+'&date='+str(date)+'&page='+str(page_num)
# 숫자는 문자열과 더할 수 없으므로 str으로 변환 후 이어붙여준다.requests
- url에 나열되어있는 뉴스 기사들, 뉴스 기사들마다 가지고 있는 뉴스 url 을 가져오기 위해 전체 HTML텍스트를 가져와서 어떠한 변수에 저장을 해야할 것.
해당 url의 HTML문서를 가져오게 하는 것이requests라는 모듈이 담당
news = requests.get(url)
# url 의 전체 HTML텍스트를 news 변수에 할당한다.
news.content
# HTML문서를 텍스트로 우리가 볼 수 있게 프린트 해준다.
크롤링 차단 방지: 유저 에이전트(User Agent)를 지정
- 서버에서 사용자를 알 수 없는 어떠한 접근을 차단, 그러므로 유저 에이전트를 지정하여 우회하여 접근한다.
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
news = requests.get(url, headers=headers) # 유저정보를 requests.get시 포함.
news.content함수 생성
- HTML에서 news url 부분만 뽑아 리스트 형대로 저장하는 함수 생성
def make_urllist(page_num, code, date):
urllist= []
for i in range(1, page_num + 1):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
url = 'https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1='+str(code)+'&date='+str(date)+'&page='+str(i)
news = requests.get(url, headers=headers)
soup = BeautifulSoup(news.content, 'html.parser')
news_list = soup.select('.newsflash_body .type06_headline li dl')
news_list.extend(soup.select('.newsflash_body .type06 li dl'))
for line in news_list:
urllist.append(line.a.get('href'))
return urllist함수 이용, 뉴스 url 출력하기
url_list = make_urllist(1,101,20200506)
print('뉴스 기사의 총 url 갯수 :',len(url_list))
url_list[:5]👉🏻 결과
뉴스 기사의 url 갯수 : 20
['https://n.news.naver.com/mnews/article/057/0001451723?sid=101',
'https://n.news.naver.com/mnews/article/057/0001451721?sid=101',
'https://n.news.naver.com/mnews/article/057/0001451718?sid=101',
'https://n.news.naver.com/mnews/article/003/0009849190?sid=101',
'https://n.news.naver.com/mnews/article/057/0001451717?sid=101']데이터프레임 생성
dictionarys 이용하여 코드를 보기쉽게 변환
categories = {'101' : '경제', '102' : '사회', '103' : '생활/문화', '105' : 'IT/과학'}데이터프레임을 위한 함수 생성
# 데이터프레임을 생성하는 함수.
def make_data(urllist, code):
text_list = []
title_list = []
for url in urllist:
article = Article(url, language='ko')
article.download()
article.parse()
text_list.append(article.text)
title_list.append(article.title)
df = pd.DataFrame({'contents': text_list,'title': title_list})
df['code'] = categories[str(code)]
return df데이터프레임 생성
data = make_data(url_list, 101) #경제카테고리 선택
data[:10] # 상위 10개 출력
여러가지 카테고리 뉴스의 데이터프레임 생성
함수 생성
def make_total_data(page_num, code_list, date):
df = None
for code in code_list:
url_list = make_urllist(page_num, code, date)
df_temp = make_data(url_list, code)
print(str(code)+'번 코드에 대한 데이터를 만들었습니다.')
if df is not None:
df = pd.concat([df, df_temp])
else:
df = df_temp
return df함수 실행 : 데이터프레임 생성
code_list = [101, 102, 103]
df = make_total_data(1, code_list, 20200506)
print('뉴스 기사의 개수 :',len(df))
df.sample(10)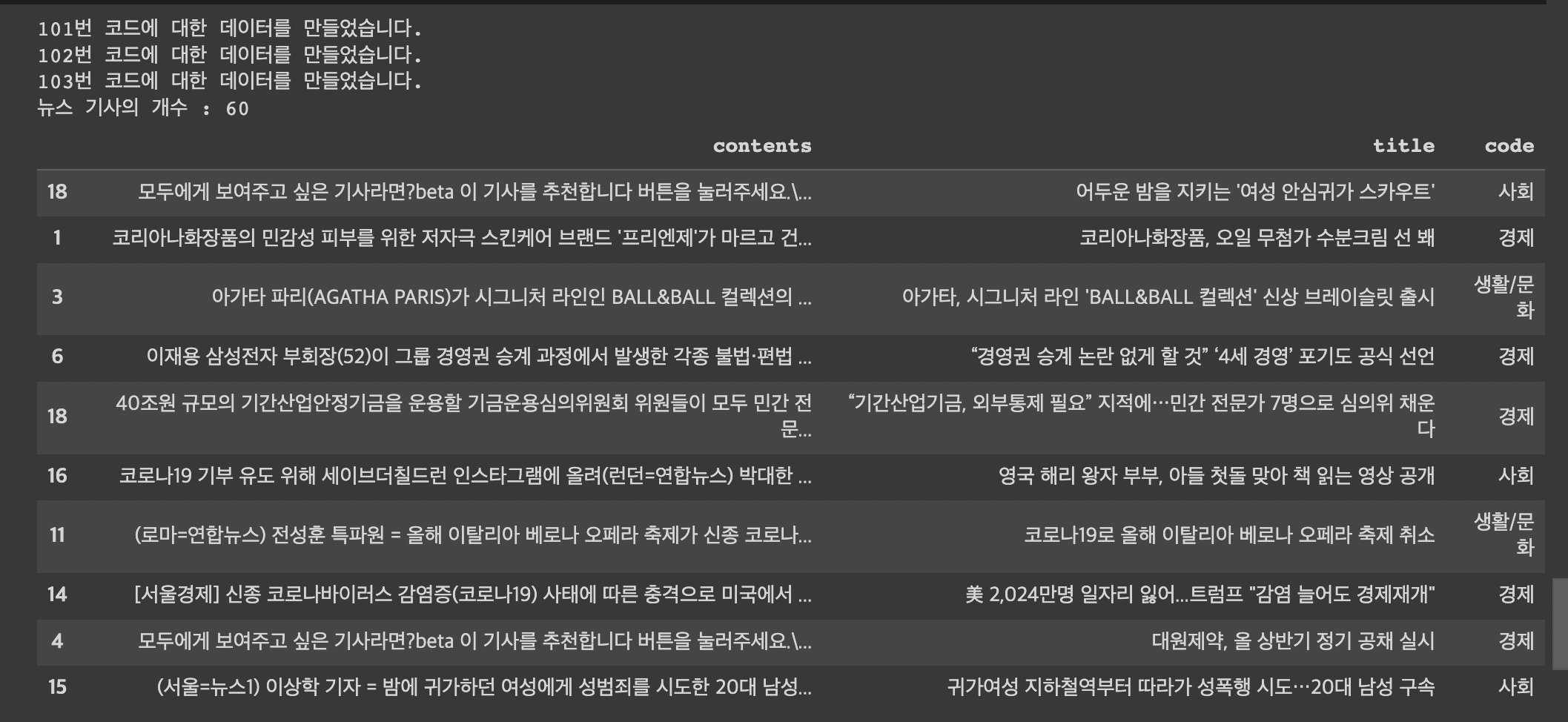
저장하기
df.to_csv('news_data.csv', index=False)
Hello, I'm libramin!