Okapi BM25 모델에 대하여
BM25는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 랭킹 함수로 사용되는 정보검색 알고리즘으로, Bag-of-word 개념을 통해 쿼리에 있는 용어가 각각의 문서에 얼마나 자주 등장하는지를 TF-IDF를 활용해 평가한다. 키워드 q_1,...,q_n을 포함하는 쿼리 Q가 주어질 때 문서 D에 대한 BM25 점수는 다음과 같다.
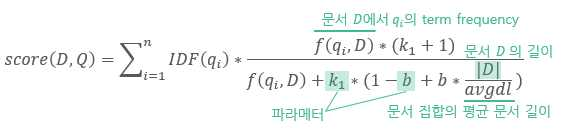
IDF는 자주 등장하는 단어에 대해서는 가중치를 낮게 설정하고, 자주 등장하지 않는 단어는 더 큰 가중치를 두도록 설정한다.
파라미터 b는 문서의 길이의 중요도를 조절하는 값으로, 보통 0.75로 설정한다.
파라미터 k1은 TF가 점수에 주는 영향을 조절하는 값으로, 일반적으로 1.2~2.0으로 설정한다.
참고문헌 : https://littlefoxdiary.tistory.com/12
BM25 모델 사용해 보기
파이썬을 활용해 BM25 모델을 사용해 보기 위해 BM25 라이브러리를 설치해준다.

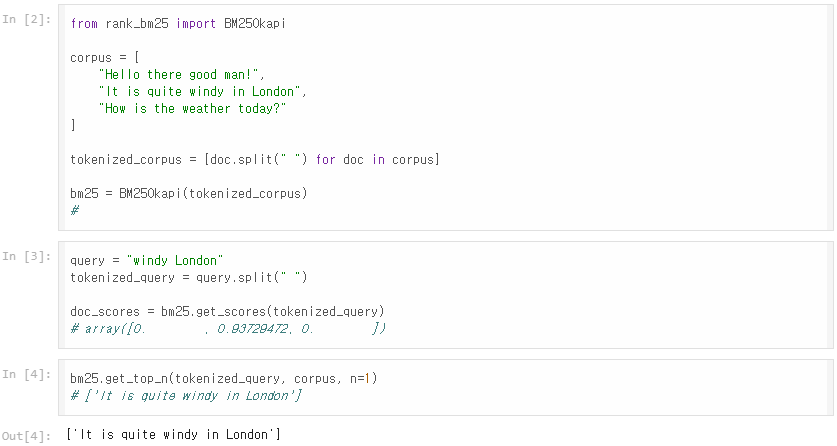
다음과 같이 문서 내에 주어진 예제를 실행하여 정상적으로 작동하는지 확인한다.
예제와 다른 영어 문서를 사용하여 몇 가지 예제에 대해서 잘 동작하는지 확인해보자. 준비한 영어 문서는 10개의 비디오 게임 명대사를 모아놓은 것이다.
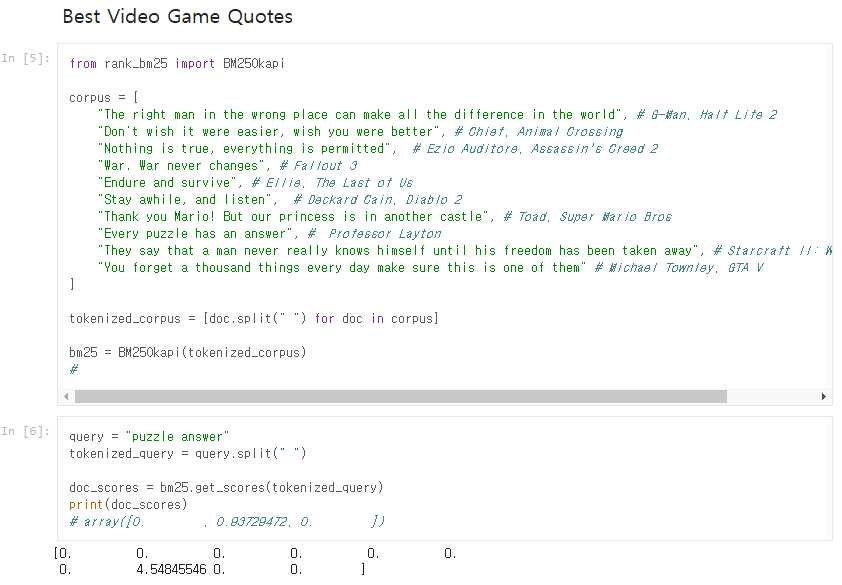
쿼리를 “puzzle answer“라고 했을 때, corpus 중에서 ‘puzzle’이나 ‘answer’를 포함한 문서를 찾아야 한다. 이에 해당하는 문서는 index=7의 ‘레이튼 교수 시리즈’의 명대사다.
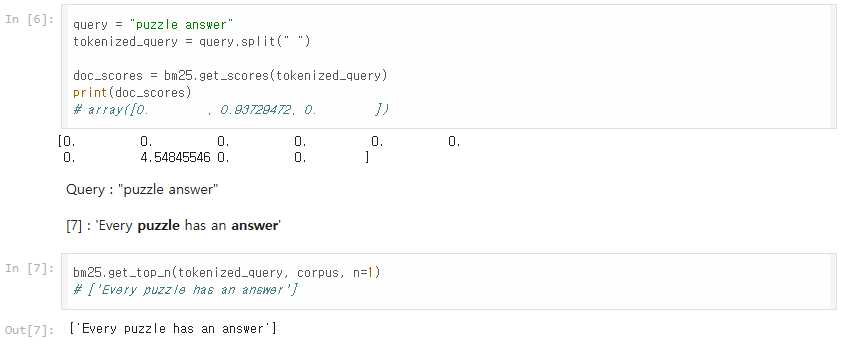
쿼리를 “make sure”라고 했을 때, corpus 중에서 ‘make’나 ‘sure’를 포함한 문서를 찾아야 한다.
이 중 index=0의 ‘하프라이프2’ 명대사는 ‘make’는 포함하고 있으며, index=9의 ‘GTA 5’의 명대사는 ‘make’와 ‘sure’를 모두 포함하고 있다.
따라서 쿼리와 더 연관성이 있는 문서는 index = 9의 ‘GTA 5’의 명대사이며, BM25 점수도 더 높다.
한국어 문서에 BM25 모델 적용해 보기
영문서에서 토큰화 과정을 거친 것처럼 한국어 문서에서도 띄어쓰기를 이용해 토큰화한 후 BM25 모델로 랭킹 점수를 측정해보자.
다음은 한국어 문서에 BM25 모델을 적용하는 예제다.
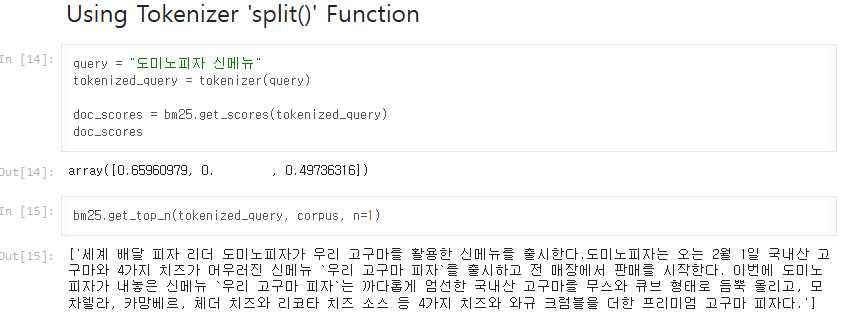
띄어쓰기만으로 tokenization을 진행하면 조사까지 포함해 단어의 df와 idf를 계산하는 것을 확인할 수 있다. 예시 query인 "도미노피자 신메뉴"를 이용해 문서를 검색해보자. split() 함수를 이용해 단어를 분리한 후 점수를 매기면 다음과 같다.
index=0인 문서의 경우, '도미노피자가', '신메뉴를', '도미노피자는' 등 조사가 붙어있는 단어는 점수에 포함하지 않고, 두 번의 '신메뉴'만으로 점수가 산출된다.
index=2인 문서 또한 '도미노피자가'는 포함하지 않고 '도미노피자'만으로 점수가 산출된다. 이는 영어 문서와 다르게 띄어쓰기만으로 단어를 토큰화시킬 수 없는 한국어 문서에서 발생하는 문제다.
그렇다면 한국어에 적합한 방법으로 단어를 나눠야 할 방법을 찾아야 할 것이다. 이에 대한 하나의 해결법으로 다음의 bigram 함수는 단어를 두 음절로 나누는 함수를 이용해보자.
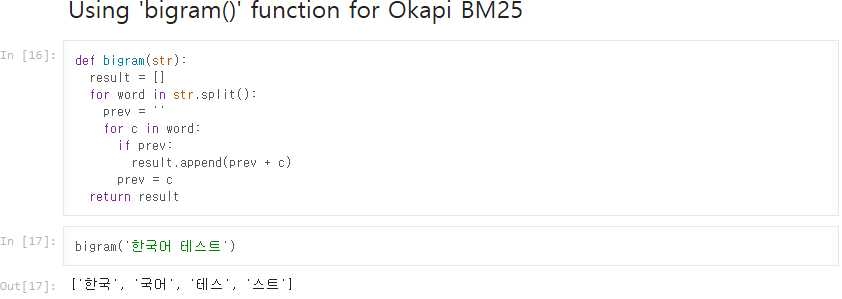
우선 document collection에 대해 bigram 함수를 이용해 단어를 분리하고, 이에 대한 BM25 랭킹을 진행한다.
Query에 대해서도 bigram을 진행하고, 이를 바탕으로 document colleciton에서 검색을 진행한다.
이렇게 한다면 조사와 분리된 단어를 검색할 수 있어 띄어쓰기를 통한 토큰화보다 이상적으로 한국어 문서에서 유사도 랭킹을 측정할 수 있다.
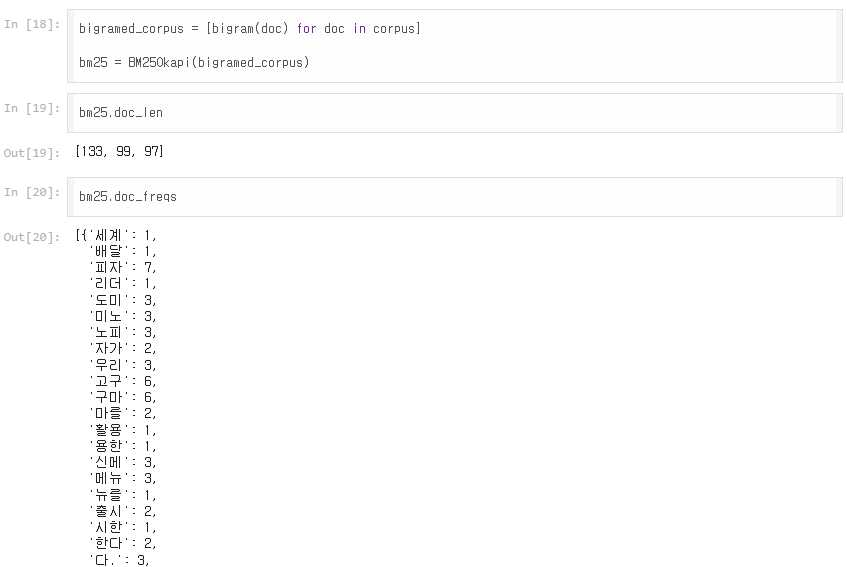
다음은 예시로 주어진 corpus에 대해 bigram() 함수를 적용해 BM25 랭킹을 진행하는 과정과 그 결과다.
모두 피자와 관련된 문서임에도 불구하고 index = 1인 문서에서는 점수가 0이 나온 것에 비해, 이번에는 세 문서에서 모두 적절하게 점수가 양수로 측정된다.
그 중 가장 연관성이 높은 문서는 index=0인 문서인 것이 확인되었으며, 한국어 문서에 대해서 BM25 모델이 잘 작동하는 것을 확인했다.

예제와 다른 한국어 문서를 사용하여 몇 가지 예제에 대해서 잘 동작하는지 확인해보자. 준비한 한국어 문서는 3개의 한국어 발라드 노래의 가사를 모아놓은 것이다.
첫 번째 문서는 AKMU의 ‘어떻게 이별까지 사랑하겠어 널 사랑하는 거지’, 두 번째 문서는 에일리의 ‘첫눈처럼 너에게 가겠다’, 세 번째 문서는 이세계아이돌의 ‘겨울봄’이다.

영어 문서에서 사용하듯이 띄어쓰기를 이용한 토큰화를 이용할 경우, 다음과 같이 명사와 조사가 같이 묶여 하나의 term으로 인식된다. 이 경우, 아래와 같이 쿼리를 입력했을 때 제대로 검색이 이루어지지 않는 문제가 발생한다.
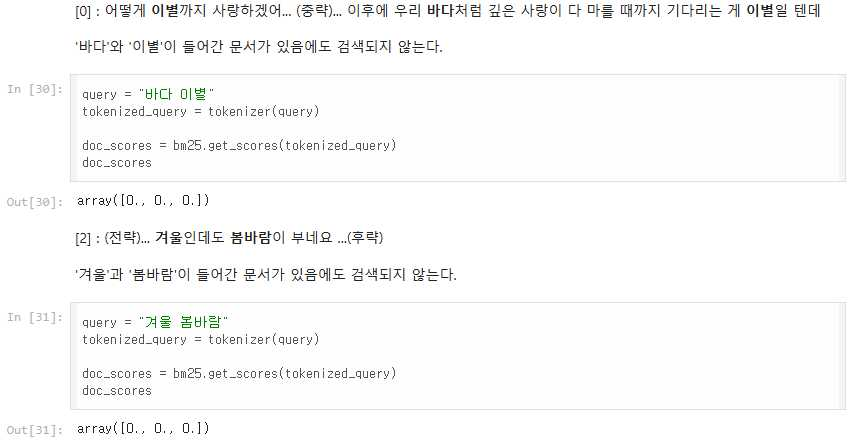
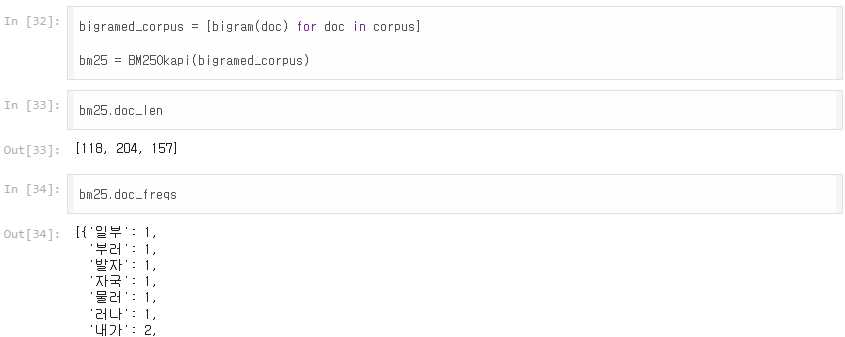
가령 쿼리가 “바다 이별”일 때, AKMU의 노래에는 이 두 단어가 모두 있지만, 조사와 함께 토큰화가 되어있어 쿼리의 두 단어만으로는 검색이 이루어지지 않는다.
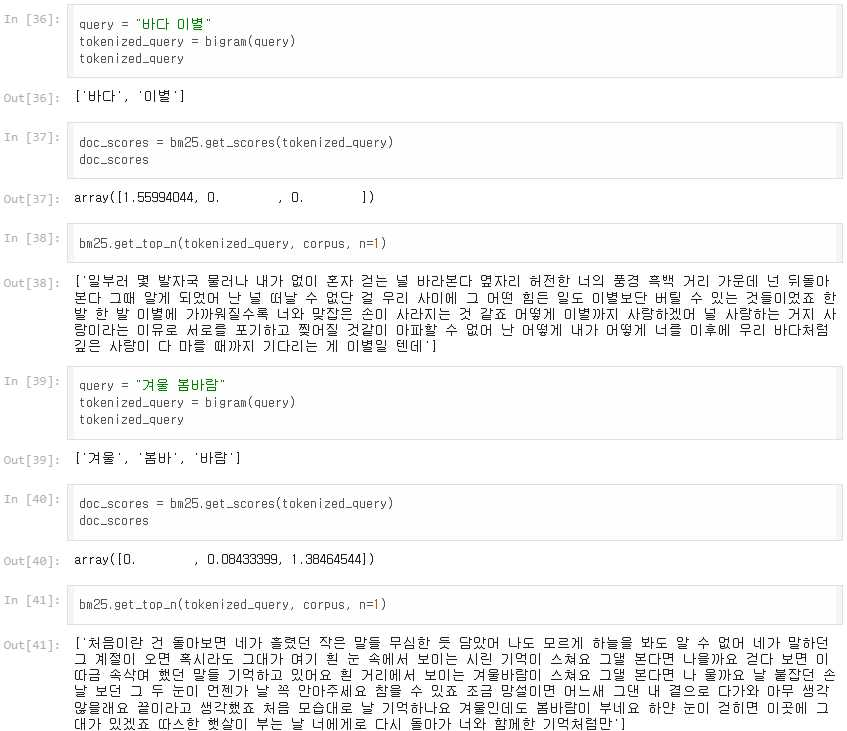
“겨울 봄바람”의 경우에도 이세계아이돌의 노래에 이 두 단어가 모두 포함되어있지만, 같은 이유로 검색이 이루어지지 않는다.
그렇다면 bigram() 함수를 이용해 음절은 나눈 후, 이를 바탕으로 랭킹 함수를 실행하고 쿼리를 통한 검색을 진행한다면 문제가 해결될 것이라고 기대한다.
다음과 같이 bigram() 함수를 적용하여 예제를 실행해 본 결과, 잘 동작하는 것을 확인했다.

위 내용에 해당하는 모든 코드는 GitHub 레포지토리로 저장해뒀으니 확인해도 좋다.
