궁금하신 점이나 고칠 부분이 있다면 언제든지 댓글 남겨주세요!
로지스틱회귀 모델📈
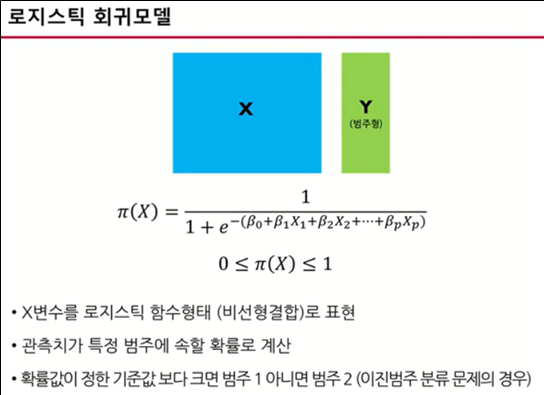
로지스틱 회귀모델은 고객 이탈 데이터를 통해서 공부했다. 고객 이탈 데이터셋은 True와 False로 이루어져서 이 값을 1과 0으로 바꾸고, 다시 이 데이터를 로지스틱회귀 모델로 적용하는 것이었다.
그리고 고객이 과연 이탈할지 잔류할지 예측하고 분석하는 모델이다. 이진형 데이터에 매우 강함
로지스틱 회귀모델의 사용
로지스틱 회귀모델을 사용하는 경우
- 새로운 관측치가 왔을 때 이를 기존 범주 중 하나로 예측(범주예측)
- 제품이 불량인지 양품인지 분류
- 카드 거래가 정상인지 사기인지 분류
- 고객이 이탈고객인지 잔류고객인지 분류
- 내원 고객이 질병이 있는지 없는지 분류
데이터 변환
우선 고객 이탈 데이터의 값들이 True 와 False로 이루어져있기 때문에
numeric 오류를 방지하기 위해서 둘의 값을 0 과 1로 구분지어 주어야한다.
churn.columns = [heading.lower() for heading in churn.columns.str.replace(' ', '_').str.replace("\'", "").str.strip('?')] churn['churn01'] = np.where(churn['churn'] == 'True.', 1., 0.)```
여기서 새로 변환시켜 추가해준 값들이 0 과 1의 값이 나중에 결과값을 판별 할 수 있도록 해준다.
새로운 churn01 컬럼 부분 생성 0.과 1.의 부분으로 구성되어 이 값의 범위로 예측의 결과를 알 수 있다.
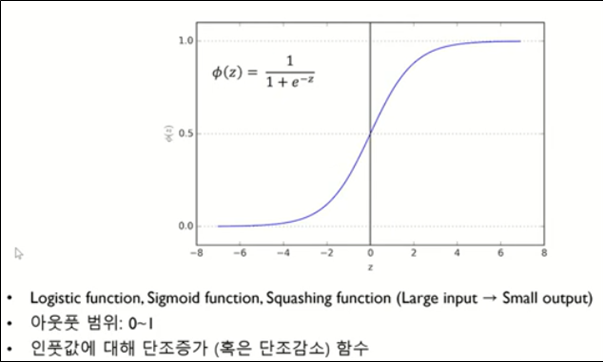
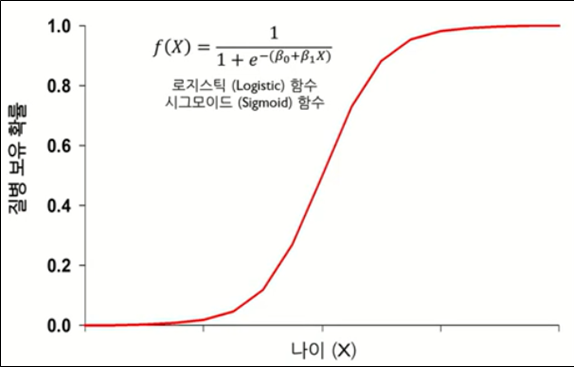
로지스트회귀분석에서 가장 중요한 부분이 이진형의 값을 처리하기 위해서 시그모이드 함수를 사용한다는 점이 매우 중요하다!
상수항 추가.
여기서 아까와 다른점이 있는데 바로 상수항을 추가한다는 점이다
솔직히 상수항을 추가하는 이유는 아직 잘 모르겠다.. 결과값이 제대로 나오게 하기 위함이라는데.. 비교를 해보니 별차이가 없는것 같던데.. 더 공부해야겠다
print("========================================================== 표준화 되기 전 ==========================================================") ```# Fit a logistic regression model dependent_variable = churn['churn01'] independent_variables = churn[['account_length', 'custserv_calls', 'total_charges']] independent_variables_with_constant = sm.add_constant(independent_variables, prepend=True) print(independent_variables_with_constant) logit_model = sm.Logit(dependent_variable, independent_variables_with_constant).fit() print(logit_model.summary()) # print("\nQuantities you can extract from the result:\n%s" % dir(logit_model)) print("\nCoefficients:\n%s" % logit_model.params) print("\nCoefficient Std Errors:\n%s" % logit_model.bse)
위의 코드에서 independent_variables_with_constant = sm.add_constant(independent_variables, prepend=True) 부분에서 sm.add_constant 가 바로 상수항을 추가하는 함수 부분이다.
odds
로지스틱 회귀분석에서는 회귀계수의 해석을 위해서 odds가 필요하다
그 이유는 로지스틱 회귀는 S자 곡선이므로 독립변수가 한 단위만큼 변할 때, 기대되는 종속변수의 변화가 일정하지 않기 때문이다. 이때문에 회귀계수가 종속변수의 성공 확률에 미치는 영향을 파악하기 위해서는 모형 평가의 기준, 즉 odds가 필요하다. 선형회귀모형의 절편과 마찬가지로 기준 odds는 모든 독립변수가 0인 경우에 성공 확률에 미치는 영향을 나타낸다.
# Fit Standardized def inverse_logit(model_formula): from math import exp return (1.0 / (1.0 + exp(-model_formula))) * 100 at_means = float(logit_model.params[0]) + \ float(logit_model.params[1])*float(churn['account_length'].mean()) + \ float(logit_model.params[2])*float(churn['custserv_calls'].mean()) + \ float(logit_model.params[3])*float(churn['total_charges'].mean()) print(churn['account_length'].mean()) print(churn['custserv_calls'].mean()) print(churn['total_charges'].mean()) print(at_means) print("Probability of churn when independent variables are at their mean values: %.2f" % inverse_logit(at_means)) cust_serv_mean = float(logit_model.params[0]) + \ float(logit_model.params[1])*float(churn['account_length'].mean()) + \ float(logit_model.params[2])*float(churn['custserv_calls'].mean()) + \ float(logit_model.params[3])*float(churn['total_charges'].mean()) cust_serv_mean_minus_one = float(logit_model.params[0]) + \ float(logit_model.params[1])*float(churn['account_length'].mean()) + \ float(logit_model.params[2])*float(churn['custserv_calls'].mean()-1.0) + \ float(logit_model.params[3])*float(churn['total_charges'].mean()) print(cust_serv_mean) print(churn['custserv_calls'].mean()-1.0) print(cust_serv_mean_minus_one) print("Probability of churn when account length changes by 1: %.2f" % (inverse_logit(cust_serv_mean) - inverse_logit(cust_serv_mean_minus_one)))
예측하기
이제 결과를 예측해보자. 해당 코드부분에서 표준화가 적용되지 않았는데 다음 부분에서 로지스틱 함수의 표준화를 같이 설명하도록 하겠다.
결과 예측이 제대로 나오는지 확인하기 위해서 기존 데이터의 상위 10개의 값과 비교를 해보자.
print("======================================= 값 예측하기 =============================================") new_observations = churn.loc[churn.index.isin(range(10)), independent_variables.columns] new_observations_with_constant = sm.add_constant(new_observations, prepend=True) y_predicted = logit_model.predict(new_observations_with_constant) y_predicted_rounded = [round(score, 2) for score in y_predicted] print(y_predicted_rounded)
결과는 아래와 같이 나온다.

기존의 데이터
아까 위에서 설명했듯이 로지스틱회귀 모델은 이진형 데이터에 강하다고 했다.
z의 값이 0.5를 기준으로 구분하면되니. 모두 0.5미만으로 False의 값 결과를 나타내고있다. 예측이 모두 성공했다!
