
궁금하신 점이나 고칠 부분이 있다면 언제든지 댓글 남겨주세요!
이 자료를 기록해두지않으면 너무 아까울것 같아서 남긴다...
빅데이터 분석 수업을 들으면서 생긴 과제를 하는데 맨땅에 거진 박치기를 하듯이 공부를 했다.
공부 보다는 삽질, 이 삽질을 기록한다.
선형회귀 모델은 뭔지, 심지어 독립변수, 종속변수도 모르고 시작한 삽질..
선형회귀 모델📉
먼저 wine_input.py 코드를 가지고 분석을 해야되는데 wine_both.csv파일의 데이터를 가지고 분석을 실시했다 와인의 품질을 측정하고 예측하는 코드였다.
이 코드에서 내가 구해야 할 quality는 종속변수가 되고 나머지 이 종속변수를 결정하는 값들이 바로 독립변수의 개념이 되는거다.
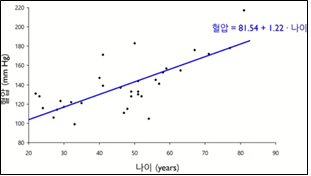
아래는 선형회귀 모델 예제의 그래프인데 혈압을 구하려고하니 혈압이 바로 종속변수가 되고 혈압을 결정하는 나이가 바로 독립변수가 되겠다.
혈압 = 81.54 + 1.22*나이 의 경우 절편=81.54, 기울기=1.22 나이만 입력하면 원하는 값인 혈압을 예측할 수 있다.
선형 회귀 모델 E(Y) = f(x) = beta0 + beta1X1... beta(p)X(p)
그리고 미리 말하자면, 선형회귀 모델은 구하는 값이 변동되는 숫자의 값일때, 적용하는 모델이라고 생각하면된다. 로지스틱 회귀모델은 뒤에서 설명하도록 하겠다.
상관관계 분석 (산점도)
입력 변수간에 변수 쌍 사이에 상관계수를 계산해보았다.
먼저 산점도를 작성해보았다.
print(wine.corr()) # 변수간 관계 살펴보기(산점도 작성) # Look at relationship between pairs of variables # Take a "small" sample of red and white wines for plotting def take_sample(data_frame, replace=False, n=200): return data_frame.loc[np.random.choice(data_frame.index, replace=replace, size=n)] reds = wine.loc[wine['type']=='red', :] whites = wine.loc[wine['type']=='white', :] reds_sample = take_sample(wine.loc[wine['type']=='red', :]) whites_sample = take_sample(wine.loc[wine['type']=='white', :]) wine_sample = pd.concat([reds_sample, whites_sample]) wine['in_sample'] = np.where(wine.index.isin(wine_sample.index), 1.,0.) reds_sample = reds.loc[np.random.choice(reds.index, 100)] whites_sample = whites.loc[np.random.choice(whites.index, 100)] wine_sample = pd.concat([reds_sample,whites_sample], ignore_index=True)
corr()함수는 모든 변수 쌍 사이의 상관계수를 구한다.
결과를 보면 알코올, 이산화황, 산성도, 이산화황, 구연산은 품질과 양의 상관관계가 있다. 반면 결합산, 휘발산, 잔여 설탕, 염화물, 총이산화항, 밀도는 품질과 음의 상관관계가 있다.
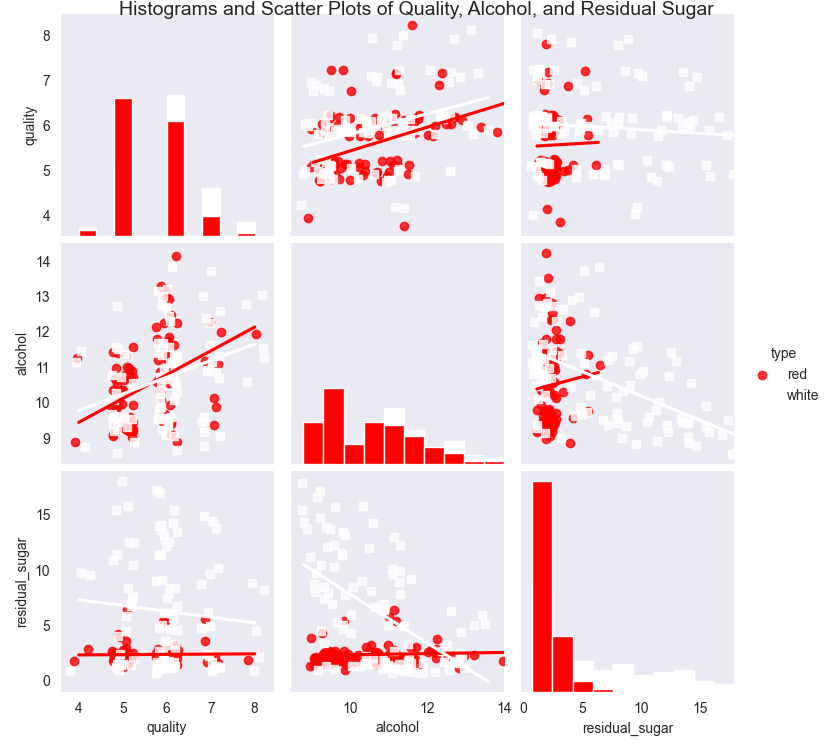
해당 그림의 산점도 나타나게 된다.
최소제곱법
선형회귀분석에서는 최소 제곱법을 적용한다.
my_formula = 'quality ~ alcohol + chlorides + citric_acid + density + fixed_acidity + free_sulfur_dioxide + pH + residual_sugar + sulphates + total_sulfur_dioxide + volatile_acidity' lm = ols(my_formula, data=wine).fit() print(lm.summary()) print("\nQuantities you can extract from the result:\n%s" %dir(lm)) print("\nCoefficients:\n%s" % lm.params) print("\nCoefficient Std Errors:\n%s" % lm.bse) print("\nAdj. R-squared:\n%.ef" % lm.rsquared_adj) print("\nF-statistic: %.1f P-value: %.2f" % (lm.fvalue, lm.f_pvalue)) print("\nNumber of obs: %d Number of fitted values: %s" % (lm.nobs, len(lm.fittedvalues)))
my_formula에서 먼저 내가 적용할 선형회귀 모델에서 종속변수와 독립변수를 선언하다고 생각하면된다 가장먼저오는 quality ~ 부터 시작하는데 이게 바로 우리가 구할 y값인 종속변수가 되는거다 나머지 ~뒤에 있는 부분들이 바로 독립변수들이 되겠다,
위의 코드에서 lm = ols(my_formula, data=wine).fit() 부분에서 ols가 최소제곱법(OLS: Ordinary Least Squares)을 적용시킨다는 것을 의미하고 종속변수와 독립변수선언한 변수를 기존의 wine 데이터 프레임을 적용시켰다. 그리고 fit()은 학습을 시킨다는 의미를 갖는다.
표준화
⭐내가 가장 어려웠던 부분 표준화 정말 삽질 많이했다.⭐
표준화 공식: (구하려는값(종속변수) - 독립변수평균) / 독립변수표준편차
이 표준화를 해야되는 이유, 그리고 하면서 생긴 의문점들을 정리해보고자 한다.
표준화를 하면서 생긴 의문점들
첫번째 표준화를 왜 해야할까?
우선 표준화를 진행한 변수는 평균은 0이고, 표준편차는 1이 된다. wine_describe() 의 결과를 보면
위의 결과에서 빨간 네모의 값을 잘보면, min의 값과 max의 값차이가 상당하다.
바로 여기부분이 표준화가 필요한이유이다. 독립변수가 갖는 범위를 감안하여 표준화가 필요하다 판단 될 경우, 표준화를 진행해야한다.
그렇다면 표준화를 진행하면 어떻게 달라질까 먼저 표준화를 진행하지않고 결과 값을 보고 그다음 표준화를 진행한뒤의 결과를 비교해보자.
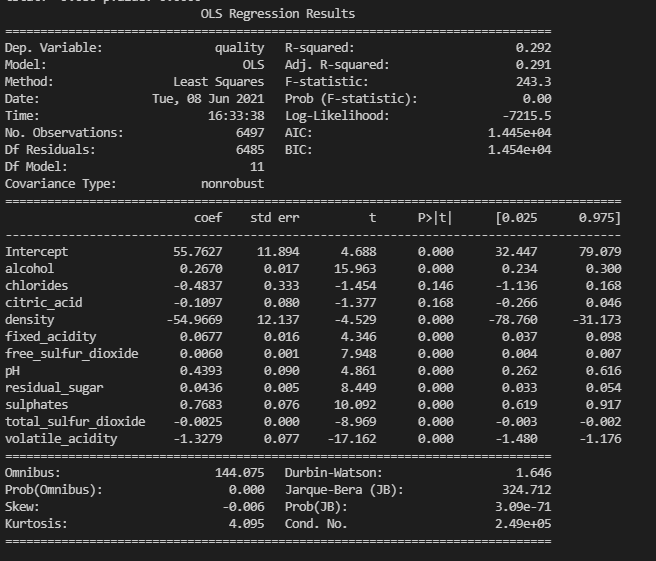
표준화를 하지 않은 선형회귀 모델
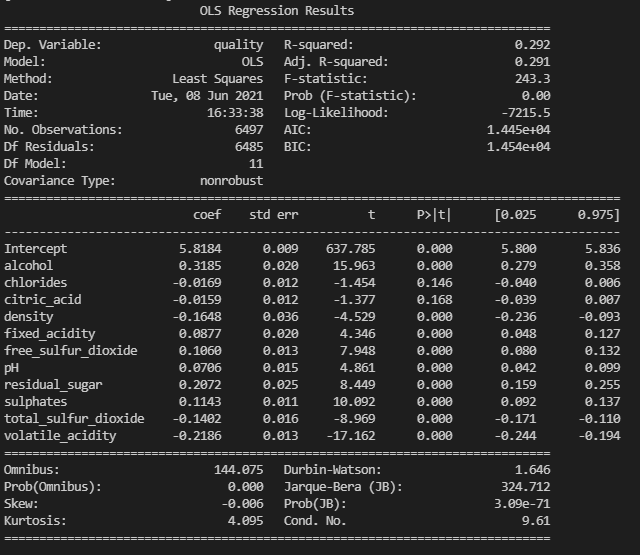
표준화를 한 후의 선형회귀 모델
결과 값의 차이가 곧바로 나타난다.
표준화를 진행하기 전에는 Intercept(절편) 의 값이 55.7627이었던 반면, 표준화 후에는 5.8184의 값이 나오게된다. 그리고 density 의 값도 눈에 띄게 변화가 나타났다.
👉 결국에 표준화를 진행해야 우리가 어떤 값이 종속변수에 가장 많이 영향을 미치게 되는지 정확한 독립변수를 알 수 있는 것이다. 독립변수를 진행하면 회귀계수의 해석이 달라지게 된다
표준화 코드
dependent_variable = wine['quality'] independent_variables = wine[wine.columns.difference(['quality', 'type', 'in_sample'])] independent_variables_standardized = (independent_variables - independent_variables.mean()) / independent_variables.std() wine_standardized = pd.concat([dependent_variable, independent_variables_standardized], axis=1) lm_standardized = ols(my_formula, data=wine_standardized).fit() print("테스트") print(lm_standardized) print(wine_standardized) print(lm_standardized.summary())
예측하기
이제 표준화가 끝났으니 예측의 결과를 보자.
와인 데이터의 상위 10개의 값으로 측정해보았다
예측 코드
#기존 데이터셋의 처음 10개의 값을 가지고 '새로운' 관측값 데이터셋을 만듬 new_observations = wine.loc[wine.index.isin(range(10)), independent_variables.columns] y_predicted = lm.predict(new_observations) y_predicted_rounded = [round(score, 2) for score in y_predicted] print(y_predicted_rounded)
해당 코드의 실행결과 예측 결과는 아래와 같게 나온다.
결과 : [5.0, 4.92, 5.03, 5.68, 5.0, 5.04, 5.02, 5.3, 5.24, 5.69]
기존의 데이터에서 상위10개 품질 값

결과 값이 완벽하다고는 할수 없지만 얼추 비슷하게 나오는것을 확인할 수 있다.
