자료
위의 자료를 참고하였습니다.
서론
- 혼동 행렬은 분류 모형을 평가하는 지표입니다.
- 혼동 행렬은 분석 모델에서 구한 분류의 예측 범주와 데이터의 실제 분류 범주를 교차표 형태로 정리한 행렬 또는 평가지표입니다.
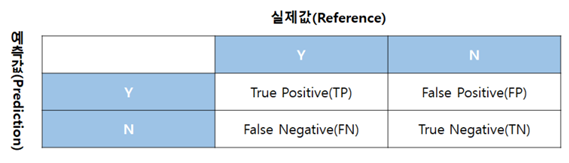
종속변수가 범주형일 때 사용한다는 점을 잊으면 안됩니다.
여기서는 R의 Ionosphere데이터를 사용해서 예측값을 만들어보고
혼동행렬을 사용해서 둘을 비교해보았습니다.
패키지 설치
필요한 패키지들은 모조리 미리 다운부터 받습니다.
install.packages("mlbench")
install.packages("rlang")
install.packages("caret")
install.packages("randomForest")
library(mlbench)
data(Ionosphere)
df = Ionosphere데이터 나누기
ConfusionMatrix(혼동행렬)은 caret패키지에 포함되어 있습니다.
랜덤값을 추출하기 위해 seed를 설정해줘야 합니다.
set.seed(2)
library(caret)
idx = caret::createDataPartition(df$Class, p = 0.7)
df_train = df[idx$Resample1, ]
df_test = df[-idx$Resample1, ]인덱스 변수인 idx를 만들어줍니다.
p = 0.7은 70%를 기준으로 한다는 뜻을 의미합니다
훈련데이터 : 7, 테스트 데이터 : 3 이렇게 7대3으로 나눈다는 의미입니.
혹시모르니까 진짜 맞는지 검증!
nrow(Ionosphere)
nrow(df_train)
nrow(df_test)Ionosphere의 총 열의 수는 351, 둘의 합이 정확히 일치하는 것을 볼 수 있습니다.
> nrow(Ionosphere)
[1] 351
> nrow(df_train)
[1] 247
> nrow(df_test)
[1] 104로지스틱 회귀 모델
이번에는 로지스틱회귀모델에 적용을해서 값을 예측해봅시다
model_glm = glm(Class ~ . , data = subset(df_train, select = c(-V1, -V2)), family = "binomial")
pred_glm_test = predict(model_glm, newdata = df_test, type = "response")
head(pred_glm_test)위에서 말했듯이 우리가 혼동행렬을 사용하기 위해서 종속변수가 범주형에 속해야한다.
그리고, 로지스틱 회귀모델도 종속변수가 범주형이 되기 때문에, Class를 종속변수로 설정해주고 나머지는 독립변수로 설정해주었습니다.
subset을 사용해서 V1과 V2 컬럼은 제거해주고, 로지스틱 회귀모델을 만들어줍니다.
다음은 이제 예측인데 predict함수를 사용합니다.
로지스틱 회귀 모델인 model_glm 회귀식과 테스트로 사용할 데이터df_test를 넣어줍니다
그리고 predict함수에서 type="response"를 넣어주고 예측을 하면 0~1사이의 확률로 구해줍니다.
> head(pred_glm_test)
1 8 11 13 16 20
0.9160221 0.6103701 0.9757966 0.9897865 0.1838459 0.8888246 예측 결과의 데이터입니다.
pred_glm_test_class = factor(ifelse(pred_glm_test >= 0.5, 1, 0))
levels(pred_glm_test_class) <- c("bad", "good")
head(pred_glm_test_class)혼동행렬을 사용하기위해서는 예측 결과를 factor형으로 변경해주어야 합니다.
범주형으로 만들어줘야합니다.
여기서는 중간을 0.5로 설정하고 0.5보다 크거나 1에 가까울수록 "good", 0.5보다 작거나 0에 가까우면 "bad"로 설정했습니다.
> head(pred_glm_test_class)
1 8 11 13 16 20
good good good good bad good
Levels: bad good이제 이 예측 모델을 평가하기 위해 혼동행렬에 넣어봅시다.
ConfusionMatrix 함수의 첫번째 인자는 예측데이터, 두번째 인자는 실제데이터 입니다.
cfm_glm = caret::confusionMatrix(pred_glm_test_class, df_test$Class)
cfm_glm> cfm_glm
Confusion Matrix and Statistics
Reference
Prediction bad good
bad 23 4
good 14 63
Accuracy : 0.8269
95% CI : (0.7403, 0.8941)
No Information Rate : 0.6442
P-Value [Acc > NIR] : 3.278e-05
Kappa : 0.5981
Mcnemar's Test P-Value : 0.03389
Sensitivity : 0.6216
Specificity : 0.9403
Pos Pred Value : 0.8519
Neg Pred Value : 0.8182
Prevalence : 0.3558
Detection Rate : 0.2212
Detection Prevalence : 0.2596
Balanced Accuracy : 0.7810
'Positive' Class : bad Accuracy를 보면 정확도를 알 수 있습니다.
이 모델의 예측 정확도는 0.8269로 82.69%라고 볼 수 있습니다.
랜덤포레스트
이번에는 랜덤포레스트를 사용해서 예측을 해봅시다
library(randomForest)
model_rf = randomForest(Class ~ . , data = subset(df_train, select = c(-V1, -V2) ))
pred_rf_test = predict(model_rf, newdata = df_test, type="response")
cfm_rf = caret::confusionMatrix(pred_rf_test, df_test$Class)
head(pred_rf_test)식 자체가 똑같다 보니 크게 다르지 않습니다. 다만 모델을 랜덤포레스트를 사용한다 뿐입니다.
> head(pred_rf_test)
1 8 11 13 16 20
good bad good good bad bad
Levels: bad goodhead의 결과는 동일합니다
하지만 혼동행렬의 결과는 다릅니다
> cfm_rf
Confusion Matrix and Statistics
Reference
Prediction bad good
bad 32 2
good 5 65
Accuracy : 0.9327
95% CI : (0.8662, 0.9725)
No Information Rate : 0.6442
P-Value [Acc > NIR] : 5.263e-12
Kappa : 0.8505
Mcnemar's Test P-Value : 0.4497
Sensitivity : 0.8649
Specificity : 0.9701
Pos Pred Value : 0.9412
Neg Pred Value : 0.9286
Prevalence : 0.3558
Detection Rate : 0.3077
Detection Prevalence : 0.3269
Balanced Accuracy : 0.9175
'Positive' Class : bad 랜덤포레스트의 분류 정확도는 Accuracy값이 0.9327로 93.27%입니다.
로지스틱 회귀모델보다 더 우수하다는 것을 알 수 있습니다.
