[Paper] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
paper link: https:///abs/2503.09516
code link: http://github.com/PeterGriffinJin/Search-R1
해결하고자 하는 문제 및 배경
기존의 대규모 언어모델(LLMs)은 추론 능력이 뛰어나지만, 외부의 최신 정보 활용과 복잡한 문제 해결에는 한계가 있음.
특히, 검색엔진과의 효과적인 상호작용이 부족해 정보 검색과 추론을 결합한 효율적인 작업 수행이 어려웠음.
이를 해결하기 위해 강화학습(RL)을 통해 LLM이 스스로 검색을 수행하고 검색 결과를 활용한 추론을 하는 능력을 키우고자 함.
기존 해결법의 한계
- RAG 방식은 일반적으로 한 번의 검색으로 결과를 가져와 사용하는 단일 회차 검색 파이프라인을 따르기 때문에 복잡한 문제에 필요한 다중 단계 검색을 수행하기 어려움
- LLM이 검색 엔진을 도구로 활용하도록 하는 접근법의 경우
- 프롬프트 기반 방법(예: ReAct 등)은 새로운 질문에 대한 일반화에 한계가 있음
- 지도 학습 기반 미세조정 방법(예: Toolformer 등)은 검색-추론 상호작용에 대한 대량의 고품질 레이블 데이터가 필요
- LLM에게 추론 중 검색 엔진을 사용하라고 프롬프트로 지시하는 Inference-time 기법만으로는 모델이 검색 엔진과 상호작용하는 법을 스스로 학습하지 못하기 때문에 최적이 아니다.
해결 방법
Search-R1 이라는 새로운 RL 프레임워크를 제안함.
이 프레임워크는 추론과 검색이 반복적으로 이루어지는 멀티턴 상호작용을 지원함.
검색 과정은 환경(Environment)의 일부로 취급되어, LLM은 스스로 검색 쿼리를 생성하고 검색된 정보를 활용하여 단계적으로 문제를 해결함.
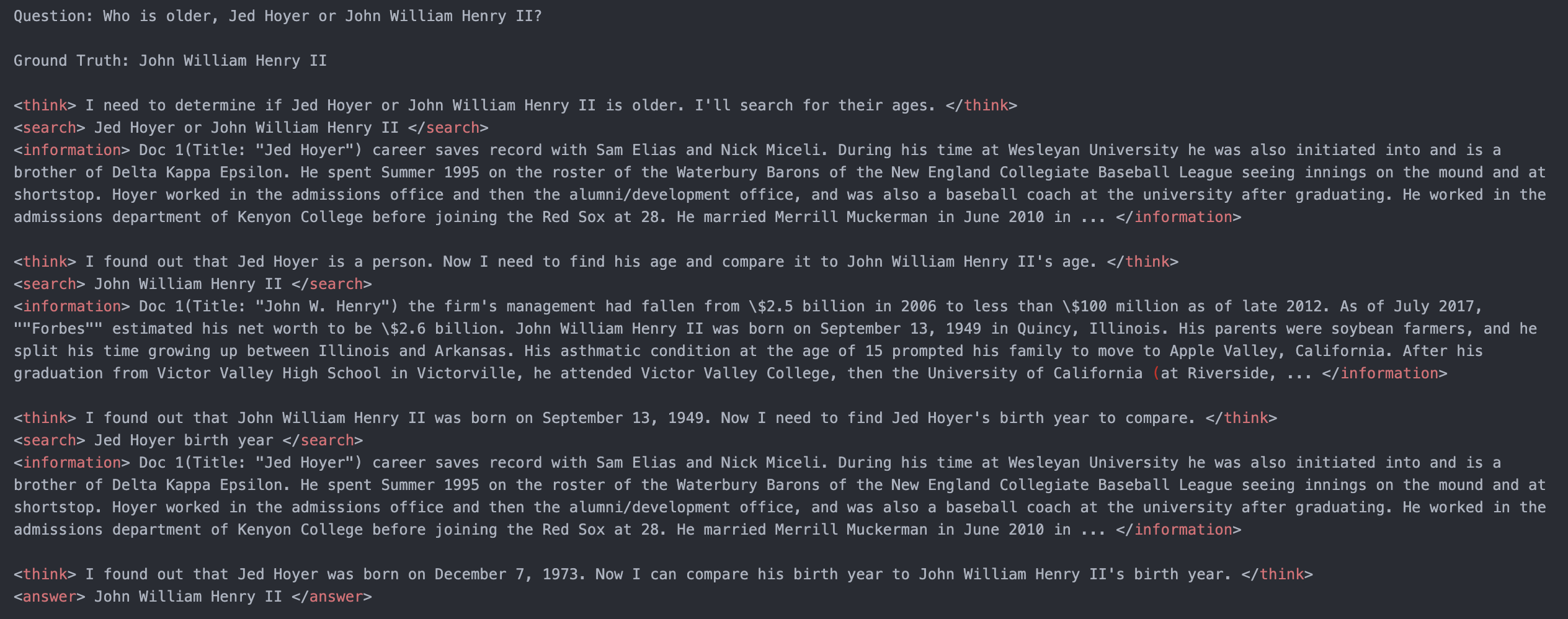
LLM token
훈련 중 검색된 내용에 대해서는 별도의 토큰 마스킹(token masking)을 적용해 학습 안정성을 높임.
- <think> 와 </think> 사이: LLM의 내적 추론 과정
- <search> 와 </search> 사이: 필요할 때 생성한 검색 쿼리
- <information> 과 </information> 사이: 실제 검색 엔진으로부터 반환된 검색 결과 정보이며, 태그로 묶여 모델의 입력 맥락에 추가
- <answer>와 </answer> 사이: 최종 답변
- 이러한 형식으로 LLM은 자신의 추론→검색→추론 의 멀티턴 인터랙션을 하나의 일관된 출력 시퀀스로 생성하게 되며, 검색 호출 횟수나 시점을 스스로 결정할 수 있음.
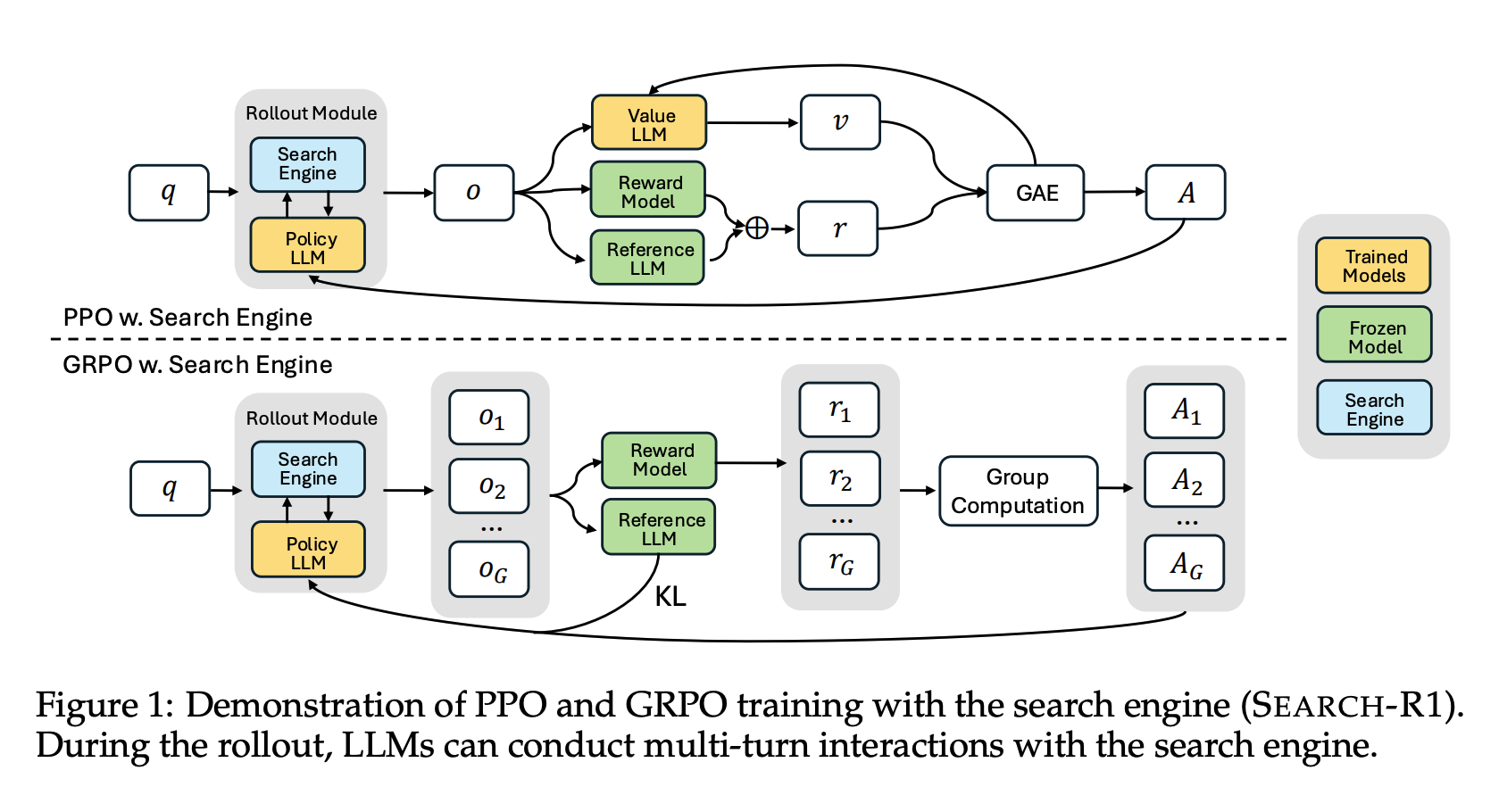
RL 최적화
-
Proximal Policy Optimization (PPO)와 Group Regularized Policy Optimization (GRPO) 를 각각 실험
-
안정적인 학습을 위해 OpenAI의 RLHF와 유사하게 레퍼런스 모델을 둬 정책의 변화를 제한하고, 가치 함수를 활용해 이득(advantage)을 계산하는 구조를 사용
-
GRPO 기법 도입: 한 번의 질의에 대해 여러 후보 출력을 생성하여 별도의 가치망 없이 상대적인 보상 우열만으로 정책을 업데이트하는 방법
-
PPO와 GRPO 비교
- GRPO가 대체로 학습 초반 수렴 속도와 최종 성능은 높음- PPO가 훈련 안정성 측면에서 우수하여 일부 경우 GRPO에서 보상이 급격히 무너지는 (collapsing) 현상을 막아줌.
-
복잡한 중간 과정을 생략하고, 최종 결과에만 기반한 간단한 보상(Outcome-based reward)으로 효과적인 훈련이 가능하도록 설계함.
결과
다양한 질의응답 데이터셋(NQ, TriviaQA, HotpotQA 등 7가지)을 활용한 실험에서 Search-R1은 기존 RAG 기반 모델 대비 성능을 크게 향상시킴.
Qwen2.5-7B 모델에서 기존 방법 대비 평균 41% 성능 향상을, Qwen2.5-3B 모델에서는 평균 20% 성능 향상을 달성함.
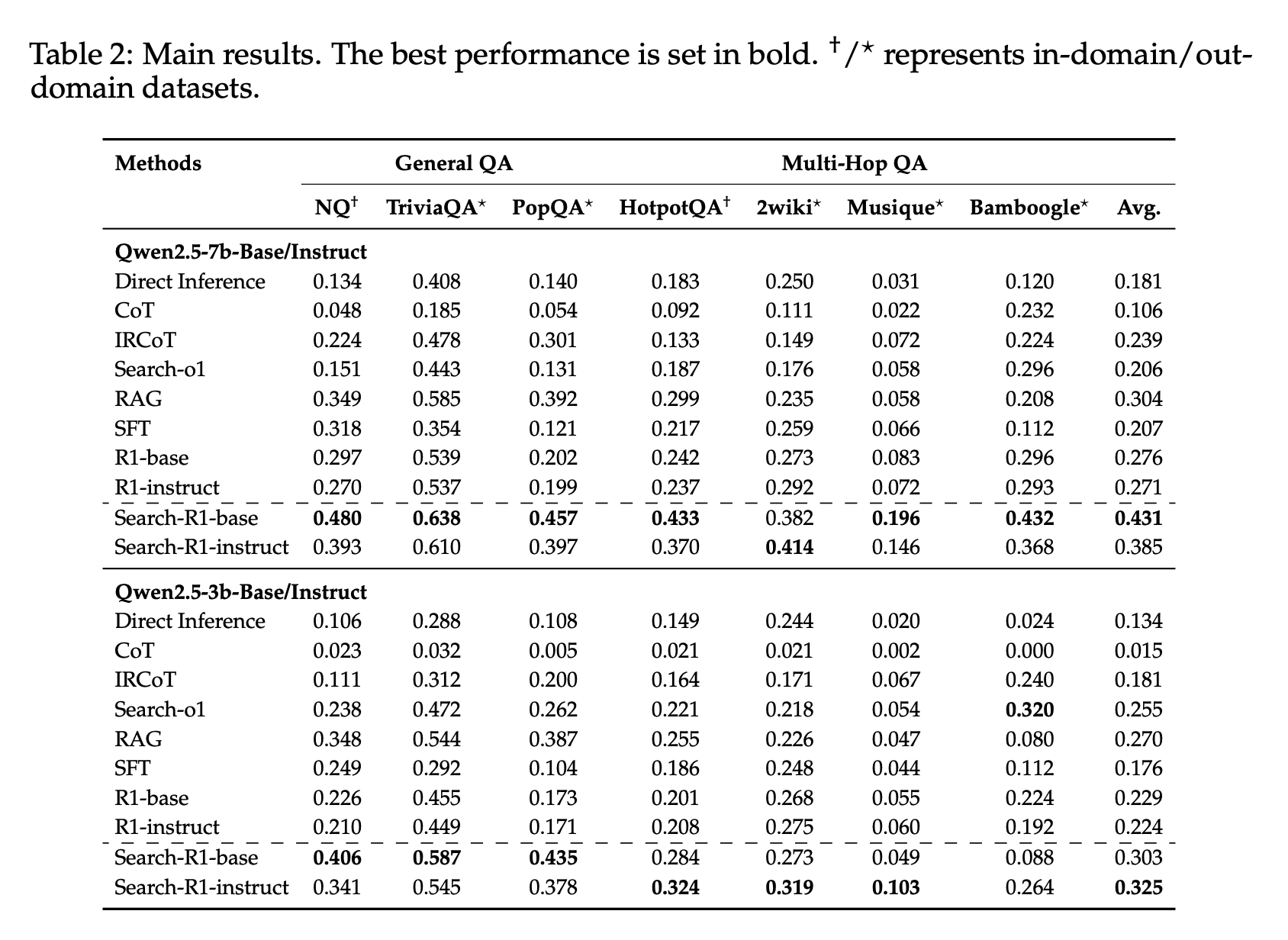
실험 결과, 검색 기능이 없는 RL 기반 모델(R1)보다 검색을 결합한 Search-R1의 성능이 우수함을 확인함.
중요성
Search-R1의 방법론은 LLM이 자체적으로 정보를 탐색하고 이를 바탕으로 추론하는 과정을 자율적으로 학습하는 데 중요한 기여를 함.
간단한 보상 설계로도 효과적인 성능 향상을 이룰 수 있어 RL 기반 LLM 학습에 효율성을 더함.
향후 LLM이 현실적이고 복잡한 질의응답 및 추론 작업을 보다 효율적이고 정확하게 수행하는 데 기여할 것으로 기대됨
