Anomaly Detection (이상 탐지)
-
Outliers
: outlier들은 세 가지 구별되는 특징을 가지고 있음
1) rare- 지도학습이 사용되었을 때 특이치의 희귀성은 타겟이 imbalance 함을 나타냄
2) heterogenous- 다른 종류의 희귀성을 포함하고 있음
3) evolving- 사기꾼이 시스템을 공격하기 위한 새로운 기술을 배우거나 발명 가능 -
Anomaly detection
: Normal sample (정상)과 Abnormal sample (이상치, 특이치)을 구별해내는 문제를 의미 -
지도학습 vs 비지도학습
Supervised learning - 주어진 학습 데이터셋에 정상 sample과 비정상 sample의 data와 라벨이 모두 존재하는 경우
장점) 라벨링이 되어 있기 때문에 이상치 유형을 보다 정확하게 유형(대상)으로 지정 가능
단점) 라벨링된 예제가 없다면 새로운 유형의 이상 이후 탐색이 불가능
Semi-supervised learing - data imbalance가 심한 경우 정상 sample만 이용해서 모델을 학습하는 것 (One class svm이 해당)
장점) 정상 sample만 있어도 학습 가능
Unsupervised learning - 대부분의 데이터가 정상 sample이라는 가정을 하여 라벨이 없는 경우 (PCA, KNN이 해당)
One Class SVM
: One class svm은 데이터를 특정 공간으로 이동하여 원점과 가까운 관측값을 이상치로 판별하는 모델 기반 방법론이며, 멀티모달 데이터에 대해 잘 수행된다.
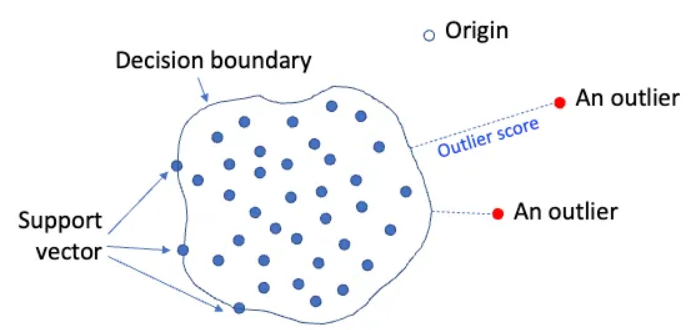
원점은 알고리즘이 정상 데이터와 분리하고자 하는 클래스로, 정상 smaple을 둘러싸는 Decision boundary를 설정하고 boundary를 최대한 좁혀 boundary 밖에 있는 sample들은 모두 비정상으로 간주하는 것
OCSVM은 커널과 몇 가지 하이퍼파라미터의 선택에 민감하며 선택 사항에 따라 성능이 크게 달라질 수 있다.
-> 이로 인한 해결책은 여러 모델을 구축하고 안정적인 결과를 위해 예측을 평균화하는 과정이 필요
: 특징 공간에서 의사결정경계면으로 이상치를 판별하기 때문에, 고차원 초평면에서 좋은 성능을 발휘한다.
: OCSVM은 정상 클래스가 아닌 데이터를 탐지하기 위해 정상 클래스의 속성을 모델링한다.
references
Handbook of Anomaly Detection
Raghavendra Chalapathy, Sanjay Chawla. “Deep Learning for Anomaly Detection: A Survey.” arXiv, 2019.
