Object recognition (객체 탐지)
객체 탐지 (object recognition)는 classification (분류) + localization (위치 지정) 으로 이루어져 있다.
One stage / Two stage Detector
객체 탐지는 1) One stage detector ex) YOLO
2) Two stage detector ex) R-CNN, Fast F-CNN, Faster R-CNN 로 나눌 수 있다.
1) One stage detector : 한꺼번에 객체 찾고 영역 찾기
= 속도 빠르지만 성능 낮음
2) Two stage detector : 선택 탐색 알고리즘으로 객체가 존재할 만한 proposed regions를 제안 → CNN 연산을 적용 → 특징 추출 → SVM을 통한 분류가 이루어진다.
: Region proposal을 찾는 영역 / ROL (Region of Interest)을 판단하는 영역으로 구성된다.
= 성능 좋지만 속도 느림
R-CNN
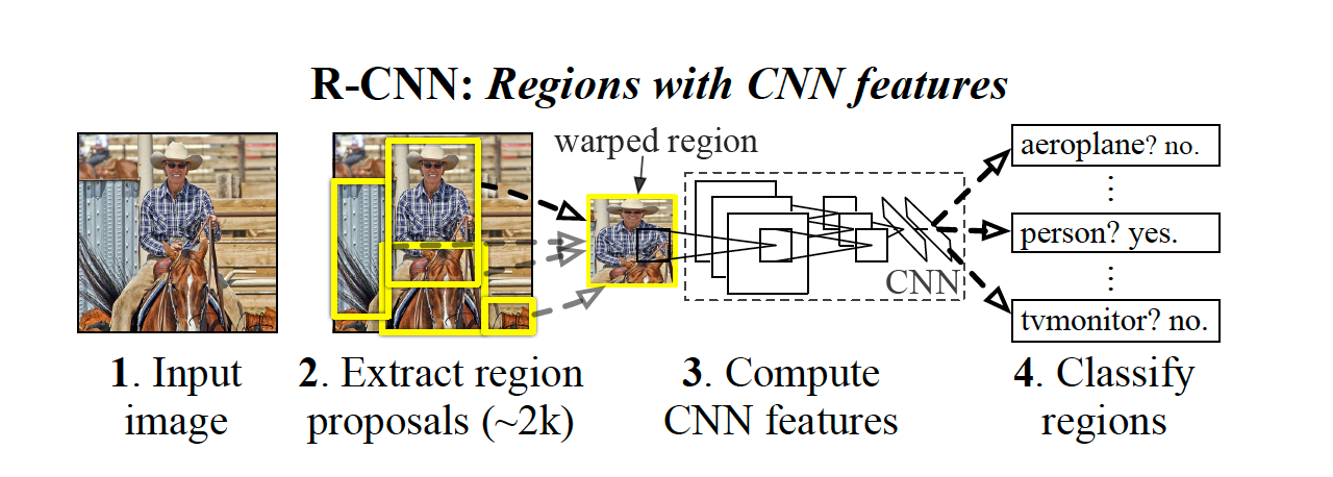
1. Region Proposal : 입력 이미지에 selective search 알고리즘을 적용하여 물체가 있을 만한 박스 추출 (~2k, 2천 영역)
2. 모든 박스를 resize (warping) : 고정된 크기로 warping하여 CNN의 input으로 사용
3. Region Classification : 이미지넷 데이터로 학습시켜 놓은 CNN layer를 통과시켜 feature map 추출
4. Classifiy regions: feature map을 SVM을 통해 분류한 후, regressor을 통해 bounding box 위치 조절
R-CNN의 단점?
강제로 크기를 맞추기 위한 warping으로 이미지의 변형◦손실이 일어나게 됨
Region proposal에서 제안된 2천 개의 모든 후보 영역에 대해 CNN 연산이 이루어져야 하므로 많은 연산량이 필요하며 느림
Fast R-CNN
: 기존의 R-CNN, SPP-net의 문제를 해결해 연산시간을 줄이고 성능을 높인 알고리즘
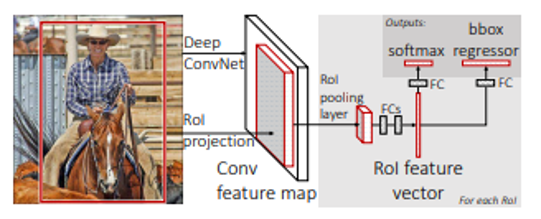
1. 이미지 전체에 CNN을 적용하여 생성된 feature map에서 후보영역을 생성 (각 후보영역에 CNN을 적용하는 R-CNN과의 차이점)
2. 생성된 후보 영역을 Rol pooling을 통해 고정 사이즈의 feature vector로 추출
3. feature vector에 FC Layer을 거쳐 softmax를 통해 분류
4. regressor을 통해 bounding box 위치 조절
= CNN 특징 추출 및 classification, bounding box regression을 모두 하나의 모델에서 학습시키고자 한 모델 (end-to-end 학습 가능)
Rol pooling Layer (Rol)
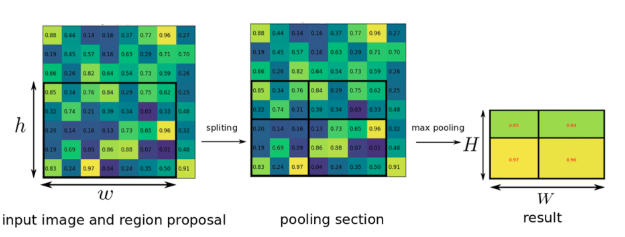
: Rol 영역에 해당하는 부분만 max pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소하는 단계
references
