수업
사무자동화를 알아? 왜 DB가 평정을 하게 됐을까?
-
데이터 I/O가 쉬워서!
-
백업도 복구도 간편하고 크게 문제가 없다.
RDB는 PIT 리커버리 라는 기능이 있다. DB에서 날릴 수 있는 시간은 최대 1분이다. RDS는 1분단위로 저장되기 때문에, 지금이 7시 29분이라면 7시 28분까지의 작업은 모두 저장된다. -
데이터 모델링만 잘하면 중복 문제도 없다
엑셀에서는 데이터가 중복되기 쉽다. 다른 시트에 어디있는지 언제
데이터 원장은 -
비밀 데이터를 비밀스럽게 보관할 수 있다.
DB는 접근권한을 설정할 수 있어서
넌클러스터드 인덱스 요청...?
트리거...?
스토어드 프로시저(SP)...? -> 이건 중요하다
DBA가 있으면 DB 스키마를 덤프로 떠서 DBA에게 분석을 요청한다.
게임에서는 DB의 최적화가 상당히 중요하다! 반응속도가 중요하기 때문.
최근에 뜨고있는 DB는 Postgre.
MySQL 5와 8은 하늘과 땅차이다. 5는 마이그레이션도 안되니까 가능하면 8로 쓸것.
-
DDL - Data Definition Language
CREATE ALTER -
DQL - Data Query Language -> 이건 무조건 알아야 한다!
SELECT -
DML - Manipulation Language -> 이것도 무조건 알아야 한다!
INSERT, UPDATE, DELETE -
JOIN은 INNER, LEFT, RIGHT, OUTER가 있다
INNER는 두 테이블에서 일치하는 데이터만 끌어오는 교집합
LEFT는 왼쪽 테이블 기반으로 왼쪽은 모든 테이블, 오른쪽에서 일치하는 데이터
RIGHT는 오른쪽 테이블 기반으로 오른쪽이 모든 테이블, 왼쪽에서 일치하는 데이터
OUTER는 그런거 없고 다 나와! 헤쳐모여. 합집합. 일치하지 않는 데이터도 포함 -
와일드카드가 지금 공부하는 수준에서는 편할 수 있지만, 데이터가 수억 수조인 현업에서는 와일드카드를 쓰는 순간 트래픽 과부하가 걸린다.
또한 새 컬럼 추가, 기존 컬럼 삭제 시 와일드카드 사용 쿼리가 예상치 못한 결과를 반환할 수도 있다.
-> 그래서 DB에서 데이터 불러오는 것 만큼은 체리픽이 필요하다!
반드시 컬럼을 명시해서 불러오도록 하자.
숙제
240914 챌린지반 숙제
- 흉부외과 또는 일반외과 의사 목록 출력하기
select dr_name, dr_id, mcdp_cd, date_format(hire_ymd, '%Y-%m-%d')
from doctor
where mcdp_cd in ('CS', 'GS')
order by hire_ymd desc, dr_name asc이거는 전에 풀어놓은 기록이 있었다. date_format에서 헤맸던 기억이 있다... 따흐흑
자꾸 지라 쿼리문이 생각나는데, where ~ 컬럼 in (조건1, 조건2) 이런 식으로 걸면 조건1 OR 조건2로 찾아주나보다.
- 과일로 만든 아이스크림 고르기
SELECT fh.FLAVOR FROM FIRST_HALF fh
INNER JOIN ICECREAM_INFO info ON fh.FLAVOR = info.FLAVOR
WHERE fh.TOTAL_ORDER > 3000
AND info.INGREDIENT_TYPE = "fruit_based"
ORDER BY fh.TOTAL_ORDER DESC처음에 이걸 그냥 FLAVOR 로만 써줬더니 in field list is ambiguous 라는 오류를 내뱉었다. FROM을 붙여줬음에도 불구 INNER JOIN을 했더니 두 테이블을 FLAVOR를 기준으로 연결시켜서 그런가보다. (FLAVOR는 FIRST_HALF 테이블에도 있고 ICECREAM_INFO 테이블에도 있음)
240914 공부
JOIN 개념이 헷갈려요 -> 겹치는 '데이터'를 찾아주는 것!
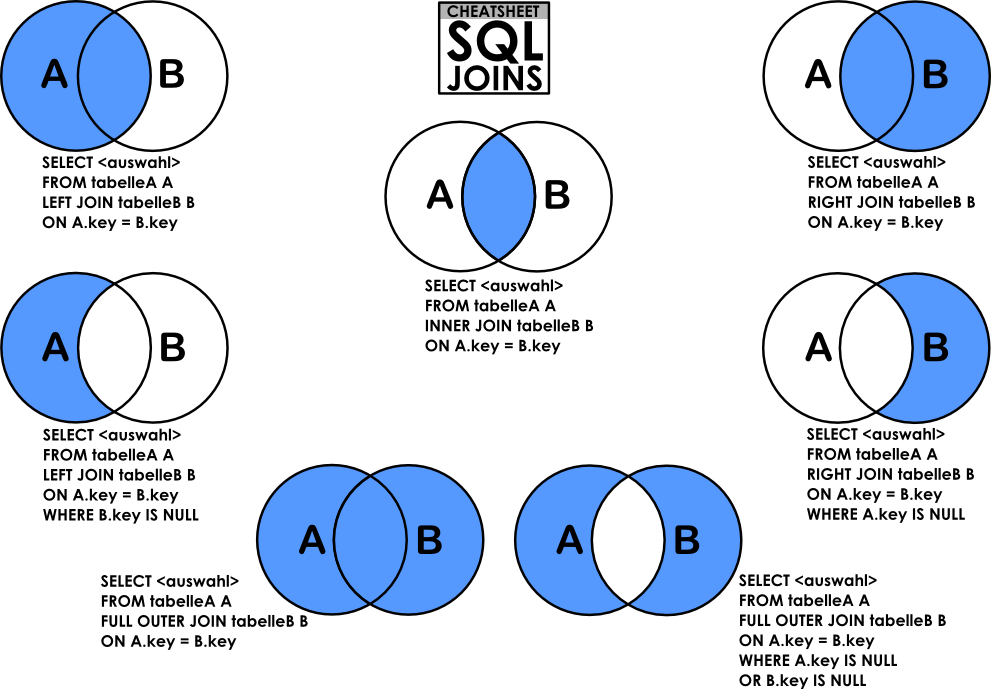
- INNER JOIN은 겹치는 컬럼이 존재하는 경우에만 사용할 수 있다. 그 겹치는 컬럼을 접착제 삼아 둘을 연결하는데, 기준 테이블과 조인 테이블 양쪽에 모두 일치하는 '데이터'가 있어야 조회된다.
이게 뭔 소리야? 😥 -> '컬럼을 이용해 붙인다' 라고 생각하니 OUTER JOIN마냥 조건에 안맞는 것들도 다 붙는거 아냐? 라는 생각이 들어 헷갈렸다.
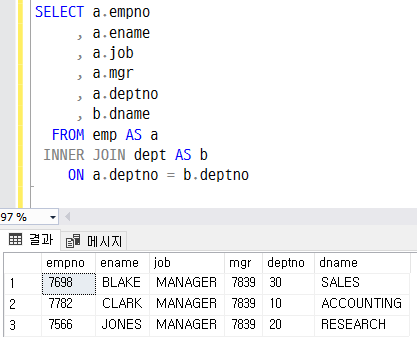
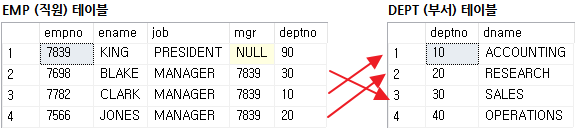
조인은 기준 테이블(emp), 조인 테이블(dept)에 조인 컬럼(deptno)에 해당하는 값이 모두 존재하는 경우에만 데이터가 조회된다.
emp 테이블 "KING"의 deptno "90"은 dept 테이블에 존재하지 않기 때문에 조회되지 않는다.
참고 블로그2에 써있던 위 내용이 도움이 되었다.
-> JOIN은 단순히 컬럼만 공통이고 땡이 아니라 데이터를 찾아주는 것이다. 저 벤다이어그램은 컬럼이 아니라 '데이터'다. 컬럼 공통은 기본이고(컬럼으로 찾아야 하니까), 그 컬럼을 기반으로 '데이터'가 공통인 행들만 딱 걸러서 나한테 보여주는 것.
-> '스탠다드반이면서 챌린지반인 사람들' 이라고 지정한게 INNER JOIN이다. 이러면 스탠다드반 전부가 나오는 것도 아니고 챌린지반 전부가 나오는 것도 아니고, '둘 다에 해당하는 사람'만 나온다.
-> 내가 생각했던 '컬럼이 공통이니 죄다 나오는거 아니야?' 는 FULL OUTER JOIN이다! 조건에 맞지 않아도 그냥 다 붙여 출력해주는 것. 그러면 스탠다드반도 모두가 나오고 챌린지반도 모두가 나온다. JOIN은 항상 데이터를 찾는다고 생각할 것!
스탠다드반 테이블 -> 이름 : {김철수, 서리하, 김개발, 김보통 } / 나이: { 25, 33, 31, 27}
챌린지반 테이블 -> 이름: {이영희, 서리하, 김개발, 박도전} / 나이: { 29, 33, 26, 28 }
이렇게 있다고 하자
스탠다드반 s inner join 챌린지반 c on s.이름 = c.이름이렇게 걸면 '이름'을 찾아주는 게 되어 서리하, 김개발이 나온다. 여기에 WHERE 나이 < 30 하면 김개발이 나오고, > 30 하면 서리하가 나온다.
- LEFT든 RIGHT든 다 OUTER JOIN의 일종이다! 그래서 둘을 모두 갖다붙이는 합집합이 'FULL' OUTER JOIN이고, 그냥 LEFT RIGHT도 OUTER이긴 OUTER다.
JOIN은 INNER JOIN과 LEFT JOIN이 많이 쓰이니 알아두자⭐
-
INNER JOIN - 특정 컬럼 기준으로 양쪽에 공통된 데이터만 쏙 뽑아준다.
헷갈리지 말 것은 그 컬럼을 기준으로 '양쪽 테이블이 연결'되어 있으니, 양쪽 테이블 내용을 다 '참조'는 할수 있다!A테이블에서 이런 조건, B테이블에서 저런 조건을 가지는 공통컬럼 내용을 찾아줘!라고 써도 조건 만족만 하면 얼마든 찾아준다. -
LEFT JOIN은 드라이빙 테이블(기준이 되는 테이블)을 왼쪽 것으로 선택하는 JOIN이다. 참고 블로그
LEFT(에 있는 테이블 기준으로) JOIN이라고 생각하자. 공통 컬럼을 JOIN 기준으로 잡고(앞으로 JOIN 조건이라고 하자), 대상테이블을 드라이빙 테이블 오른쪽에다 붙여준다.
그래서 LEFT JOIN이라는 이름대로 왼쪽 기준테이블은 모든 데이터가 다 있고, 오른쪽에는 조건에 맞는 데이터만 있고 나머지 필드는 NULL로 비게 된다.
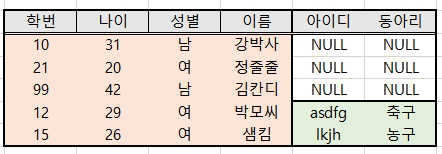
RIGHT JOIN과 FULL OUTER JOIN도 개념만 보고가자😏
-
RIGHT OUTER JOIN - 드라이빙 테이블을 오른쪽 것으로 선택하는 JOIN이다.
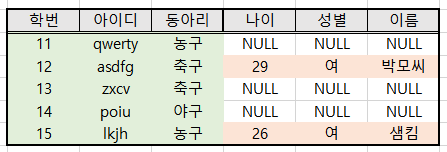
-
FULL OUTER JOIN - 야! 전부 헤쳐모여! 없어도 NULL로 채우고 그냥 우격다짐으로 갖다 붙인다.
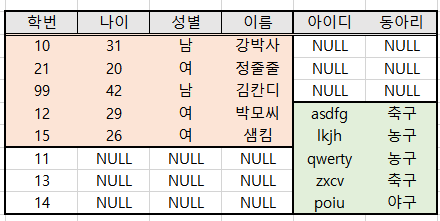
(이미지 출처: 참고 블로그)