241017 CS 과제의 내용을 수업으로 진행한 내용!
메모리
물리주소와 논리주소
CPU와 실행중인 프로그램은 메모리 어디에 무엇이 저장되어 있는지 알지 못한다.
-> 메모리는 새로운 프로그램이 실행될 때 마다 새로 얹고, 사용이 끝나면 메모리에서 날려버리기 때문이다. 그래서 같은 프로그램을 실행한다고 해도 동일한 메모리 주소에 적재되지 않을 수도 있다. 그래서 알기를 포기한 것. (?)
그래서 CPU나 실행 중인 프로그램은 물리 주소보다는 논리 주소를 사용한다. 논리 주소는 프로
프로그램들은 다른 프로그램들이 메모리 몇 번지에 저장되어 있는지 (물리 주소가 무엇인지) 굳이 알 필요가 없다. 새 프로그램이 언제든 메모리에 적재될 수 있고, 실행되지 않으면 언제든 메모리에서 날려버릴 수 있기 때문.
그래서 메모장, 카톡, 게임들은 다 물리주소가 아니라 0번지부터 시작하는 자신만을 위한 주소인 논리 주소를 가지고 있다.
예를 들어 10번지라는 주소는 메모장, 카톡, 게임에 모두 논리 주소로 존재할 수 있다. 프로그램마다 같은 논리 주소가 얼마든지 있을 수 있다.
- 운영체제 - 컴퓨터 자원과 프로그램들을 관리하는 프로그램
이 운영체제가 논리 주소와 물리 주소를 맵핑해준다. 우리는 운영체제 하면 윈도우 라고만 알고있지만, 생각보다 운영체제는 많은 일을 하는 중요한 요소.
물리주소는 말 그대로 실제 정보가 저장된 하드웨어 상의 위치.
CPU와 프로그램이 쓰는 주소는 고유하게 할당된 논리 주소.
그러면 논리 주소는 어떻게 물리 주소로 변환하나요? 🤔
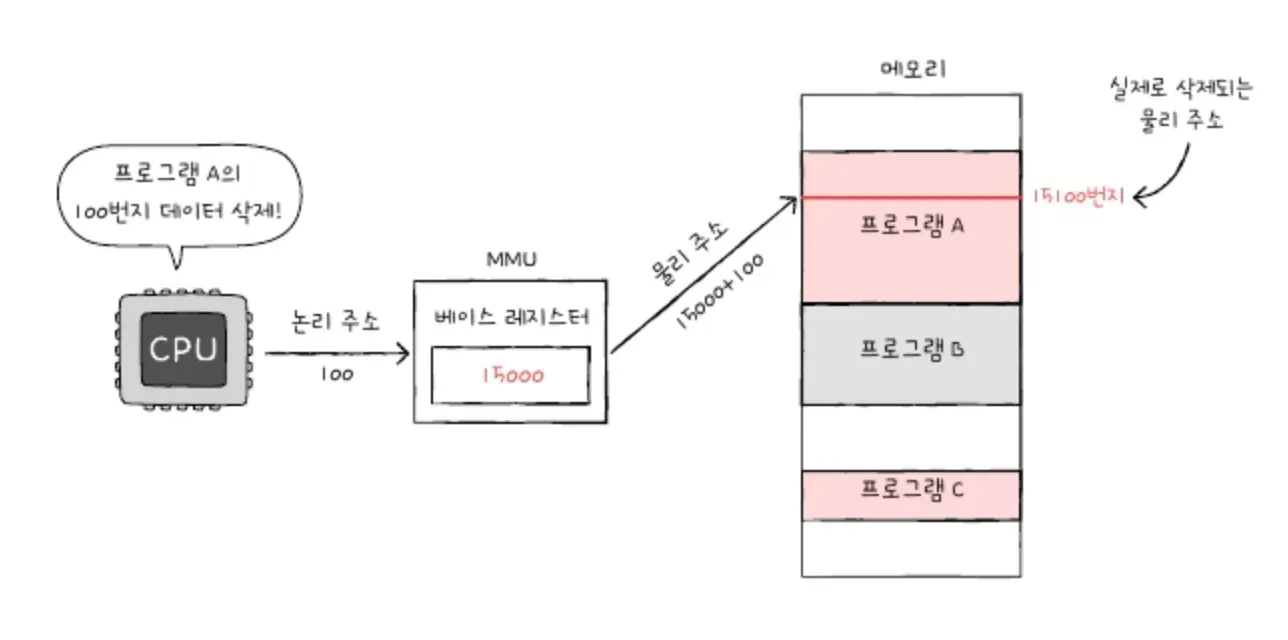
CPU와 주소 버스 사이에 있는 메모리 관리 장치인 MMU(Memory Management Unit) 이라는 하드웨어가 해준다.
MMU는 CPU가 발생시킨 논리 주소에 '베이스 레지스터' 라는 값을 더해서 논리 주소를 물리 주소로 변환한다.
예를 들어 지금 베이스 레지스터에 7000이 저장되어 있고 CPU가 발생시킨 논리 주소가 105라면, 105 + 7000 이 되어 7105가 물리 주소가 되는 것.
그러면 물리 주소가 중복될 일은 없나요? 베이스 레지스터 값이 같으면요? 🤔
베이스 레지스터는 프로그램마다 값이 다르기 때문에 중복될 일이 없다! 똑같이 1번 테이블에 짜장면 한그릇 이라고 해도 1층이랑 2층의 1번 테이블이 각각 다른 셈.
베이스 레지스터는 프로그램의 가장 작은 물리 주소. 즉 프로그램의 첫 물리 주소를 저장하는 역할을 하며, 논리 주소는 프로그램의 시작점으로부터 떨어진 거리를 나타낸다.
메모리 보호 기법 이라는 게 있다 - '한계 레지스터'의 역할
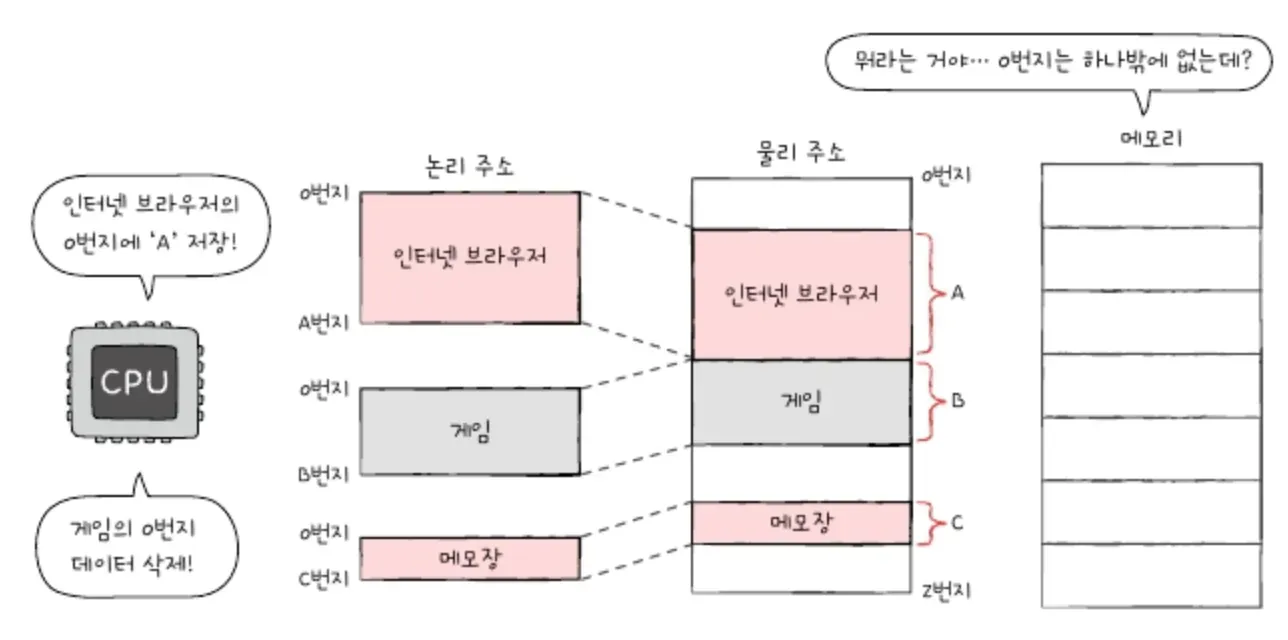
(정확히 이 이미지에 맞는 내용은 아니지만 내가 이해하기 위해 일단 가져와 봤다)
메모장의 물리 주소가 1000 ~ 1999,
크롬창의 물리 주소가 2000 ~ 2999,
게임의 물리 주소가 3000 ~ 3999번지라고 하자.
이때 메모장에서 '(논리 주소) 1500 번지에 숫자 100을 저장하라', 크롬에서 '(논리 주소) 1100 번지의 데이터를 삭제하라' 는 명령이 들어온다면 어떻게 될까?
이 명령들이 만약에 수행이 된다면, 메모장은 크롬 논리주소 500번지 에다가 100을 저장하고, 크롬은 게임 논리주소 100번지에 있는 데이터를 지워버리는 불상사가 발생할 것.
내가 이해를 못했던 건 '메모장 1500번지 있지 않나?' 라는 생각 때문이었는데, 그건 물리 주소고 프로그램이 돌아갈 때는 논리 주소 만을 봐야한다. 논리 주소는 물리 주소에 상관없이 0번지부터 새로 시작하는 주소라서 얼마든 중복될 수 있다고 했던 얘기가 이것.
물리 주소가 1000~1999까지니까, 논리 주소는 0~999번지 까지만 있는 셈.
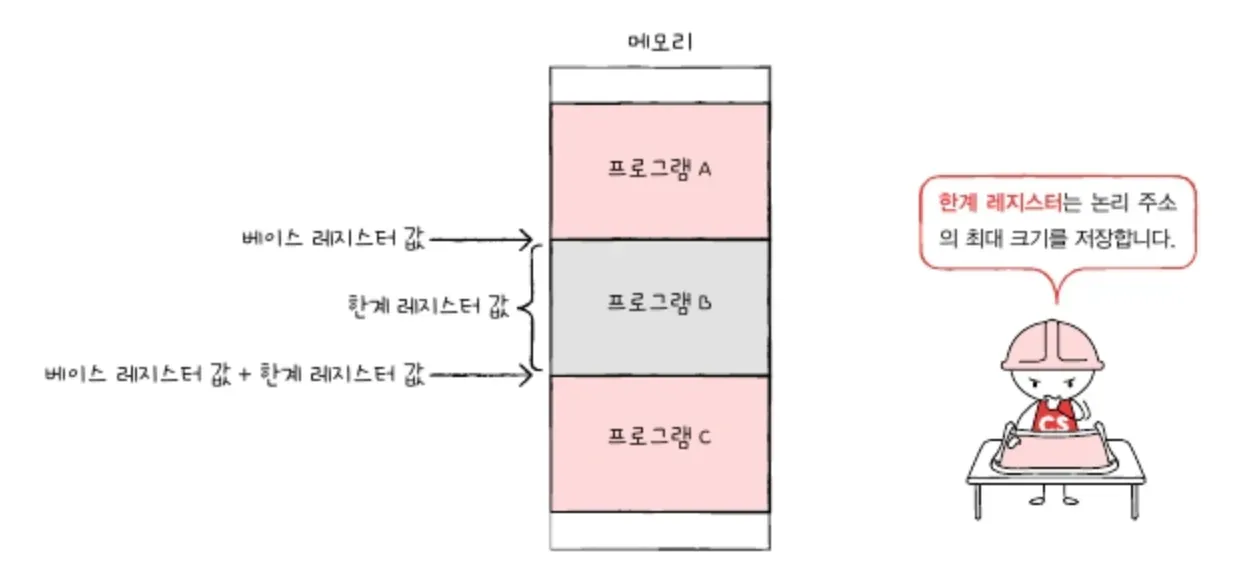
그렇기 때문에 논리 주소 범위를 벗어나는 명령어 실행을 방지하고, 실행 중인 프로그램이 다른 프로그램에 영향받지 않아야 한다.
-> 이를 위해 '한계 레지스터' 라는 게 존재한다. 한계 레지스터는 논리 주소의 최대 크기를 지정한다.
CPU가 접근하려는 논리 주소는 한계 레지스터가 저장한 값보다 커서는 안된다!
- CPU는 메모리에 접근하기 전에, 접근하려는 논리 주소가 한계 레지스터보다 작은지 항상 검사한다. 만약 한계 레지스터보다 높은 논리 주소에 접근하려고 하면 인터럽트(트랩)을 발생시켜 실행을 중단시킨다.
만약에 논리 주소가 없다고 하자
프로그램 A가 1000번지에 적재 - CPU도 프로그램 A 1000 으로 기억.
CPU: 100번지에 접근할래 -> 1100에 접근하게 된다.
프로그램 A를 껐다가 다시 켜서 이번엔 2000에 적재.
CPU: 100번지에 접근할ㄹ.........???? 뭐야 A 어디갔어?
하지만 논리 주소가 있다면
CPU: 논리주소 100에 접근하고 싶어 -> 논리주소를 이미 알고 있으니 베이스 레지스터를 더해주기만 하면 항상 같은 값에 접근할 수 있게 된다.
캐시메모리의 등장 - 연산속도와 메모리 접근속도의 간극
CPU가 메모리에 접근하는 시간은 CPU의 연산 속도보다 느리다. CPU 밖에 있는 메모리에 다녀오는게 내부에서 작업하는 것 보다 당연히 느릴 수 밖에 없다.
하지만 CPU 연산이 아무리 빨라도 메모리에 접근하는 시간이 느리면 이 연산속도가 무용지물이 된다. 뭐 방법이 없을까?
-> 이걸 위해서 나온 것이 캐시메모리다.
캐시메모리는 CPU와 메모리 사이에 존재하는, S램(Static RAM) 기반의 저장장치.
일반적인 램은 D램 이다. 삼성과 하이닉스가 잘 만드는 것도 바로 이 D램.
이렇게 캐시메모리 안 쓰고 DB로 쓰려고 만든게 바로 레디스.
메모리와 코딩과의 연관관계
자료구조를 아는가? 배열과 리스트의 차이 - 배열은 연속, 리스트는 연결
배열은 무조건 연속되어 있지만, 리스트는 연속되어 있을 수도 있고 아닐 수도 있다.
그래서 데이터 크기가 고정이라면 배열이 낫지만, 데이터 크기가 가변이라면 리스트가 나을 것이다. 이런 특징과 장단점을 고려해가면서 써야 한다.
불필요한 객체를 생성하지 않도록 하자
이런 객체가 생성/삭제 되면서 메모리를 쓰는 식의 코드가 그렇지 않은 코드보다 훨씬 리소스 낭비가 크다. int로 충분한데 float를 쓸 이유는 없다.