파이참으로 HTML만 이용하던 것에서 벗어나, 드디어 Python 문법을 시작! .py 파일을 만들어 보았다. :3
늘 기억해둬야 할것 - 변수 자료형 함수 조건문 반복문
이 다섯 요소는 어떤 언어를 가든 변하지 않아요. 언어에 따라 선언 방법이나 형태가 조금 다르지만!
- 파이썬이 JAVA나 C랑 다른 점은 선언이 편하다는 것. 자료형을 안 쓰고 세미콜론도 필요 없다.
변수, 자료형
<숫자, 문자형>
a = 3 하면 얘는 자동으로 int 형이 되는거고
a = 'sally' 하면 얘는 자동으로 String이 되는 것.
is_adult = True 하면 자동으로 Boolean 형이 된다. 참 쉽쥬?
<리스트형> -> JS랑 똑같아용 명령어만 달라용
a_list = ['사과', '배', '감', '키위']
a_list[0]='사과' //
a_list.append('귤') //어? .push 썼던건 뭐에요?->그건 JS에용
a_list.append([3,7])
->이렇게 하면 a_list[4][1]=7이에용.
리스트형이나 배열은 링크 링크처럼 타고 타고 들어간다는 느낌!
<Dictionary형> -> 얘도 똑같! key : value 형태를 기억!
a_dict={} 텅 비었어용
a_dict={'name':'kelly', 'age':34}
a_dict['height'] = 165
->이러면 a_dict = {'name':'kelly', 'age':34, 'height':165}
<리스트xDictionary 조합!>
people = [{'name':'kelly', 'age':34, 'height':165}, {'name':'john', 'age':17, 'height':177}, {'name':'Chris', 'age':23, 'height':184}, {'name':'Bella', 'age':46, 'height':156}]
people[0][name] = 'kelly'
people[2][age] = 23
people[3][height] = 156
함수, 반복문, 조건문
PIP(Python Install Package)를 써보자
▶패키지? -> 모듈(기능 묶음의 일종)을 모은 단위. 이 패키지의 묶음이 라이브러리.
근데요? 그게 왜요? -> 외부 라이브러리를 사용하기 위해서 패키지를 설치해야 해용.
외부 라이브러리를 왜 사용하는데요? -> 외부 정보를 이용해서 자료를 추출해야 할 일이 있을테니까! 서울시가 주는 날씨정보 내 홈페이지에 뙇 붙이고 싶지 않아?😎
※가상환경: 라이브러리를 모아두는 곳. 줄여서 venv.
파이썬 프로젝트 새로 만들 때 건드리면 안되는 venv 폴더가 바로 이것!
사전적으로는 '같은 시스템 내 다른 파이썬 응용 프로그램의 동작에 영향을 주지 않기 위한 격리된 실행 환경' (쿠버네티스 같은 건가...?)
이를테면 프로젝트별로 사용되는 패키지가 담긴 바구니.
가상환경 A에는 A프로젝트에 사용되는 패키지 a,b,c가 있고
가상환경 B에는 B프로젝트에 사용되는 패키지 b'(b의 다른 빌드버전),e,q,h가 있는것.
※근데 가상환경 얘기는 왜 해요?
->네가 하는 프로젝트의 라이브러리를 네 가상환경(바구니)에 설치하려면 PIP를 이용해서 다운로드 받을거기 때문임😎
파이썬은 기본적으로 데이터를 다루는 경우가 많아서, 외부데이터를 받아올 수 있는 패키지들이 가상환경에 깔려있어야 함. 아니 도구가 있어야 요리를 하쥐!
requests 패키지 깔고 외부 데이터를 이용해 ↓이런 식으로 쓸 수 있다.
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows=rjson['RealtimeCityAir']['row']
#데이터 다루는 문법은 형식마다 다르다. 이 경우는 json형식이라 이렇게 쓴 것!
#자료 소스 보면 알겠지만 배열식이다. for문을 돌릴 수 있다.
#파이썬에서 for문은 배열 속 자료들을 하나하나 꺼내겠단 것임!
for row in rows:
print(row)
#이렇게 하면 rows 내부의 값들이 하나씩 찍힐것임.
#이때 row는 저 데이터 내부의 row라는 항목명 가리키는게 아님.
#그냥 rows에서 값 꺼내려고 for문 돌리기 위한 변수명. abc로 써도 됨.
for abc in rows:
gu_name = abc['MSRSTE_NM']
gu_mise = abc['IDEX_MVL']
print(gu_name, gu_mise)
#이렇게 짰더니 행정구명 & 미세먼지 수치가 잘 추출되었다!
for abc in rows:
gu_name = abc['MSRSTE_NM']
gu_mise = abc['IDEX_MVL']
if gu_mise < 40:
print(gu_name)
#미세먼지 수치가 40보다 적은 구만 찍어달라고 하는 if문.
#파이썬의 if문은 직관적이다. 괄호 없이 조건만, 콜론, 프린트.※연습 도중 gu_mise = abc['IDEX_MVL'] 열에서 에러 발생!
'예기치 않은 들여쓰기' 라고 빨간 에러가 떴다. 이유가 뭘까?
->들여쓰기 수준이 동일하지 않을 때 뜬다. 스페이스바를 누르거나 하지 않았는지 살펴볼 것!
파이썬은 들여쓰기 수준으로 하위항목이 결정되기 때문에, 윗줄보다 아랫줄이 더 들어가 있으면 아랫줄은 윗줄의 결과물(종속)이란 얘기.
그래서 파이썬은 들여쓰기에 아주 주의해야 한다!
크롤링이 뭔가요? - 웹사이트를 긁어와보자
▶크롤링 : 어떤 웹사이트에서 내가 원하는 정보만 샥샥 긁어오는 것
크롤링을 하려면 두 가지가 필요하다.
1. 내가 원하는 데이터를 가진 페이지의 html을 요청하는 것
2. 요청해서 받아온 html 파일에서 내가 원하는 데이터를 뽑는 것
->1은 requests 패키지로 가능하고(이미 해봤고),
2는 뷰티풀 슾(bs4)라는 패키지가 필요하다. 스프가 아름다우면 크롤링이 되나보다
설정 > 프로젝트 > Python 인터프리터 에서 bs4를 설치해보자.
(아래 내용은 bs4라는 패키지 사용방법이지 파이썬 문법이 아니니 헷갈리지 않길!)
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
supu = BeautifulSoup(data.text, 'html.parser')
#이름은 본인이 원하는대로 지으면 된다. 스프니까 supu로 지어보았다.
print(supu)▶저 headers는 뭐에요? -> 실제로 html을 불러와달라고 call을 날린건 우리가 짠 코드지만, 브라우저에서 call 한 것처럼 처리해주는 것(사람이 부른 것처럼!)
위 코드를 실행하면 링크의 네이버 영화 페이지 html이 쭉 불러와진다. 크롤링 필요요소 1번인 html 요청 성공! 그러면 2번을 해보자.
▶원하는 부분 데이터만 추출하는 방법:
추출하고 싶은 대상 우클릭 > 검사 > Copy > Copy selector 클릭
변수 이름 = soup.select_one('여기에 복사한 데이터를 붙여넣자!')
ex) title = soup.select_one('#old_content > table > tbody > tr:nth-child(4) > td.title > div > a')
이를테면 해당 내용이 영화 제목인 경우, 다음과 같이 써보자.
title = supu.select_one('#old_content > table > tbody > tr:nth-child(8) > td.title > div > a')
#이 코드를 print(title) 해보면
<a href="/movie/bi/mi/basic.naver?code=175092" title="먼 훗날 우리">먼 훗날 우리</a>
#이렇게 나온다. 여기서 제목인 텍스트만 얻고 싶으니 print(title.text) 하면
먼 훗날 우리
#이렇게 제목만 뙇 나온다이런 식으로 자료를 긁어올 수 있다. 그러면 영화 페이지에서 순위, 제목, 평점을 추출해서 원하는 데이터를 뽑아볼 수 있을 것이다. :)
3-8 Quiz - 웹스크래핑(크롤링) 연습 답안!
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.9cokow4.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
c = movie.select_one('td.point')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = c.text
print(rank, title, star)이렇게 하면 결과가 이쁘게 뙇 나온다. :))

이걸 하다보니 대체 밥정이 무슨 영화일까 조금 궁금해졌다. 이야, 디지몬 선방했구나.
이 아래로는 DB얘기. 처음 써보는 mongoDB
SQL vs NoSQL -> NoSQL은 SQL 안쓴다가 아님. Not only SQL.
뭐가 달라요? -> SQL은 칸이 존재해서 칸대로 데이터를 정리, NoSQL은 칸이 없어서 들어오는대로 쌓는 느낌.
▶SQL : 이상한 데이터 들어올 일 없고, 빨리 찾을 수 있다.
체계적인 저장 구조로 유연성은 적지만, 자료 유형이 변하지 않을때 안정적으로 저장하기 좋다.
▶NoSQL : 체계는 없지만, 변하는 상황에 유연하게 대처 가능. 이를테면 이름, 전화번호만 받다가 주소도 받자! 하는 식으로 DB 내용이 바뀌어도 괜찮음. 주로 초기 서비스나 스타트업에서 많이 사용. 대표적인게 mongoDB. 우리도 쓸거야😎
doc = {'name':'Claire', 'age':38}
#보통은 이렇게 딕셔너리를 하나 만들고 이걸 넣으라는 식으로 함
db.users.insert_one(doc)
all_users = list(db.users.find({}, {'_id':False})) #요거를 보통 복사해서 쓴다
for user in all_users:
print(user)import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.9cokow4.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
c = movie.select_one('td.point')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = c.text
doc = {
'tit':title,
'ran':rank,
'st':star
}
- 아까 했는데 코드를 다시보니 기억이 안 나 당황했다. 어씨 이거 뭐야? doc는 뭔데?
▶doc = {'key':value}는 DB에 자료를 저장하기 위한 문법.
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)↑여기에서 왔다.
- 아래 코드 작성 중 변수 명을 잘못 써서 오류가 났었다! 뭐가 틀렸을까?
▶#'title':'가버나움'으로 했더니 오류가 났다. 내가 mongoDB에 밀어넣은 변수명 'tit'였기 때문!
모르겠다면 위의 코드를 보자. 내가 설정한 doc의 key값을.
->tit네! 나는 이게 헷갈렸던 것이다.
다음부턴 아예 jemok 이라고 해버릴까보다.🤔
doc = { 'tit':title, 'ran':rank, 'st':star }
movie = db.movies.find_one({'tit':'가버나움'})
star = movie['st']
all_movies = list(db.movies.find({'st':star},{'_id':False}))
for m in all_movies:
print(m['tit'])strip() 함수에 대한 고찰 - 쉽지 않았다
과제가 지니뮤직 크롤링이었는데, 써본 적 없는 strip()을 사용했어야 했다.
- 무엇보다 문제는 - strip()을 쓰면 문자열이 제거되어야 하는데, 제거가 되질 않는 것이다. 미쳐버리겠네!🤯😵😡👿 랭킹도 제목도 둘다 strip()이 먹히지 않잖아!
▶사용법이 잘못 되었다.
rank는 앞 두글자만(순위 숫자만) 추출해서 strip()을 적용했어야 했다.
title은 도중에 방해꾼이 있었다. 방해꾼을 제거했더니 역시 문제없이 적용되었다. 야호!🤩
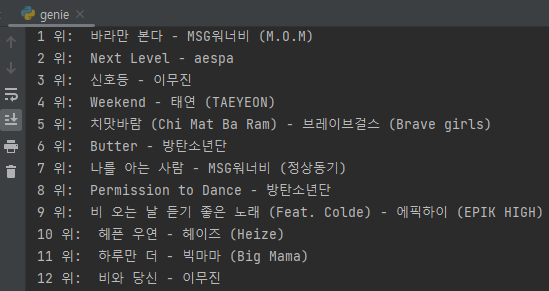
3주차 과제도 무사히 완료! 조금 더 꾸며보았다. 헿헤😋