<안건 '3주차 과제에서 strip(’19금’) 대신 decompose/delattr 를 써보는건 어떨까?' 에 대하여>
1. decompose()를 써보자
잘 짜인 html은 트리 구조를 가진다고 한다.
▶decompose()는 트리 구조에서 자식 태그를 제거하는 메서드.
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
#title = song.select_one('td.info > a.title.ellipsis').text.strip().strip('19금').strip()
singer = song.select_one('td.info > a.artist.ellipsis').text
adult_tag = song.select_one('td.info > a.title.ellipsis > span')
title1 = song.select_one('td.info > a.title.ellipsis')
print(adult_tag)
이렇게 하고 있는데... 뭔가 계속 안된다.

우클릭 검사 해서 DevTool에서 보면 이렇게 생겼다.
이것을 본 내 생각:
1. 아, class명이 icon icon-19니까 icon이나 icon-19인 애를 decompose 하면 되겠구나! -> 컴파일 실패
2. 1이 안되네? 그러면... decompose는 자식 태그를 지우는거라고 했으니까 title에서 .decompose() 해볼까? -> 실패는 아닌데 전부다 None으로 나옴
3. 그러면 2에서 .span.decompose() 하면 될까? -> 컴파일 실패
아아아악 왜안됑ㄹㄴ애렁냄랴ㅓ애ㅑㄹ머애ㅑㅓ냄ㅇㄹ
🤯🤯🤯🤯🤯🤯😠😠😠😡😡😡🤬🤬🤬😩🤪😵🤮👿👿😈👿
오와아아악 됐다아아아!!! 얏따제!!!🤩🤩🤩
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
#title = song.select_one('td.info > a.title.ellipsis').text.strip().strip('19금').strip()
singer = song.select_one('td.info > a.artist.ellipsis').text
title1 = song.select_one('td.info > a.title.ellipsis')
#adult_tag = song.select_one('td.info > a.title.ellipsis > span')
if title1.select_one('span') is not None:
title1.select_one('span').decompose()
print(rank, title1.text.strip(),singer)
else: print(rank, title1.text.strip(),singer)
#print(adult_tag)
#if adult_tag is not None:
#deladult = adult_tag.decompose()
#print(deladult)
#print(rank,"위: ", title,"-", singer)
위와 같이 수많은 변수를 선언도 해보고 decompose도 붙이고 extract도 해보고 이름도 바꾸고 하길 다섯 시간만에 찾아냈다.
이 간결한 구조를 나는 금방 생각해내지 못하고 내내 고민했네.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
title = song.select_one('td.info > a.title.ellipsis')
singer = song.select_one('td.info > a.artist.ellipsis').text
if title.select_one('span') is not None:
title.select_one('span').decompose()
print(rank, "위:", title.text.strip(), "-", singer)
else:
print(rank, "위:", title.text.strip(), "-", singer)이것이 정리된 해답 코드.
이거 찾으려고 그렇게 고생한거구나! '되는' 코드는 의외로 간결한 것이 신기하다.
정말 간단한 if-else 문인데.
완료!😎
참고한 곳들:
https://blex.me/@mildsalmon/beautifulsoup
https://studyforus.com/innisfree/650714
https://realsalmon.tistory.com/11
2. re.sub()도 써보자
▶re.sub()가 뭔데요? 정규 표현식(regex. Regular expression)의 일종.
특정 문자열을 다른 문자열로 치환할 때 쓰는 형식 언어. 정규식에서 사용되는 기호를 Meta문자 라고 함.
re.sub(A, B, text) = text에 있는 A를 B로 바꿔줘
▶정규 표현식은 또 뭔데용? 특정한 규칙을 가진 문자열의 집합을 표현하는 식이에용.
그러니까, 조건만 잘 설정하면 '내가 원하는 조건의 문자열을 보여줘' 가 가능.
※정규표현식을 쓰려면 import re 해야 함
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
title = song.select_one('td.info > a.title.ellipsis').text
singer = song.select_one('td.info > a.artist.ellipsis').text
title19 = re.sub('19금', "", title).strip()
print(rank, "위: ", title19, "-", singer)re.sub('19금', "", title).strip()
->re.sub('찾을 값(패턴)', "바꿀 문자열", 원본) 이므로,
이 식은 'title에 있는 19금을 찾아서 공백으로 바꿔줘' 인것.
완료!😎
3. delattr()도 써볼까?
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
title = song.select_one('td.info > a.title.ellipsis')
singer = song.select_one('td.info > a.artist.ellipsis').text
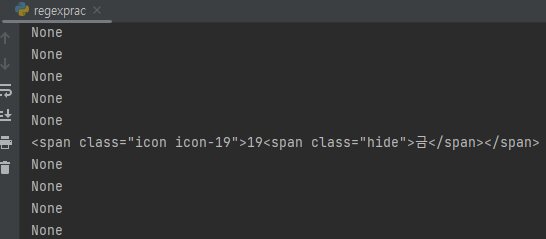
title19 = getattr(title, 'span')
print(title19)아니, 이거 하면 19금 span class 나오면서. 왜 delattr는 컴파일 에러가 나는거야?
🤯🤯🤯🤯🤯🤯🤯😡😡😡😡😡😡😡😡
아아아아아악 왜안돼애애애애애애
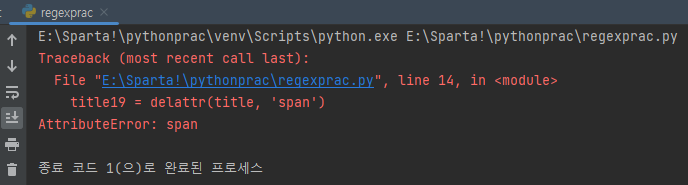
title19 = delattr(title.self.__class__,'span')
응 실패!
TypeError: can't set attributes of built-in/extension type 'NoneType'import requests
import re
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
rank = song.select_one('td.number').text.strip()[0:2].strip()
title = song.select_one('td.info > a.title.ellipsis')
singer = song.select_one('td.info > a.artist.ellipsis').text
a = getattr(title, 'span')
print(a)▶지금의 문제:
getattr(title, 'span') 은 결과가 나온다. 개중 span을 가진건 한 섹션 뿐이다.
근데 delattr(title, 'span')은 AttributeError: span 이 뜬다.
거기다 hasattr(title, 'span') 했더니 전부다 true로 나온다.
실제로 print(title) 하면 span class를 가진 건 한 섹션 뿐인데?
대체 뭐지? 뭐가 문젤까? del은 왜 안되고 has는 왜 전부 True일까?😖😖😖😖
▶고민해본 내용:
delattr()가 말하는 Attribute는 대체 뭘까? 클래스의 속성이라던데. 뭐지...? 클래스 이름...? href 같은거...?
delattr(object, name)
Parameter로 받는 object에 존재하는 name의 attribute(변수, 데이터, 함수, ...)를 삭제한다.
출처: https://jasmine125.tistory.com/840
오! Attribute가 단순히 class의 이름을 말하는게 아니었나보다. 변수, 데이터, 함수 기타 등등을 삭제한단다.
근데 내가 삭제하고 싶은 것도 데이터인데
getattr(title, 'span')는 제대로 나오는데 -> 그러면 'span'이 attribute가 맞다는 얘긴데
왜 안되지?🤔 delattr를 쓸수 없나?
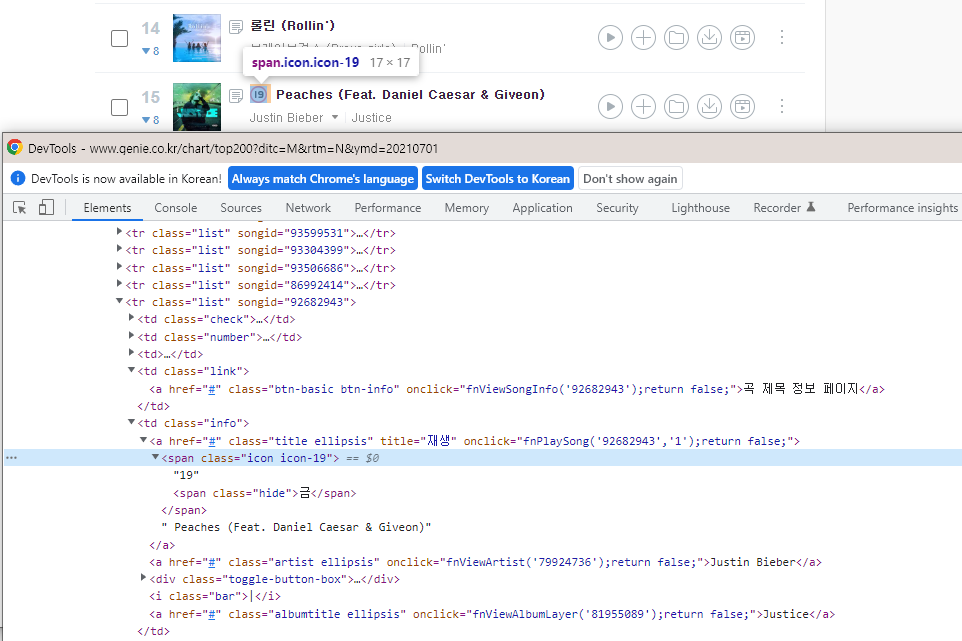
데브툴에서 19버튼의 주소는 span.icon.icon-19
19금 중 금의 주소는 span.hide
둘은 a.title.ellipsis의 하위 트리이긴 한데,
a.title.ellipsis.span. 으로 들어가진 않는다. 근데 데브툴에서는 하위그룹.
......㫈㫈㫈㫈(엉엉엉엉) 㫈㫈㫈㫈(엉엉엉엉) 😭😭😭😭 😭😭😭😭
class Ingri:
name = '조정석'
track = '무야호'
ranking = '35위'
delattr(Ingri, 'name')
print(Ingri.name)
#이것의 결과는 제대로 나온다!
AttributeError: type object 'Ingri' has no attribute 'name'이건 작동이 되고, delattr(title, 'span')은 작동이 안 된다라... 우선 이건 왜 작동이 되는걸까?
여기서 쓰인 delattr(Ingri, 'name') 은, Ingri 라는 class의 name 이라는 attribute를 삭제해달라는 작업이었다.
->이 클래스의 저 속성을 가진 게 있으면 삭제해줘.
가설(?)
▶span class를 쓰고 있으니 'span' 하면 getattr()에 걸리긴 하는데,
a.title.ellipsis.span이 아니라서 delattr()가 안되는 거 아닐까?🤔
->이것에 대한 답은 잘 모르겠다.
▶아, 이건 html 파일이고 JS를 쓰는데 나는 python으로 끌어와서 그런거 아닌가?
->그렇다기엔 getattr()가 먹히는 것을 설명하기 어려워. 어차피 이렇게 사용하려고 bs4와 requests를 이용한 것! 반드시 확장자 문제인 것 같진 않다.
음...
음......
음.........
이건 아무래도 안 되겠구먼. 나중에 stack overflow를 좀더 찾아보거나 물어봐야겠다.🤔
튜터님의 답변이 왔다.
긁어온 자료형이 전부 String이라 안되는고만! okok.