
1. 데이터 베이스 살펴보기
p.5
-
데이터 베이스는 데이터의 집합이며, 사용자나 응용 프로그램이 공유하고 동시에 접근이 가능해야 한다
-
이를 위해서 Table을 만들어서 관리해야 한다. 이 Table은 row과 column 으로 이루어져 있으며, 릴레이션 / 엔티티 라고 부르기도 한다
-
데이터가 들어가기 위해선 column이 미리 정의되있어야 한다. 데이터는 row 단위로 작업한다
-
이 row의 column에 들어가는 요소를 Data라고 한다
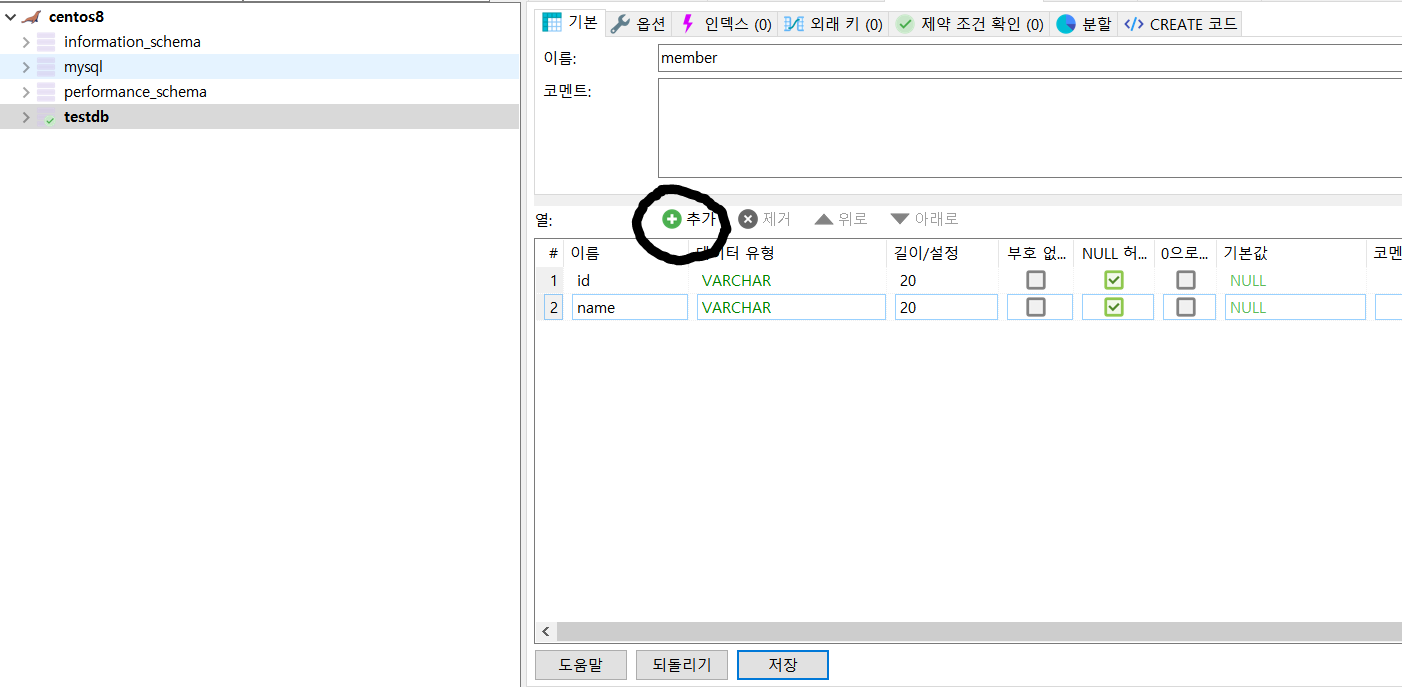
- Table을 생성하여 이름을 지정하고, 열을 다음과 같이 2개 생성해서 저장한다

- 아래 Query 문이 잘 실행된다

- 우클릭 / 행 추가 를 통해 행을 추가하여 다음과 같이 값을 바꾼다
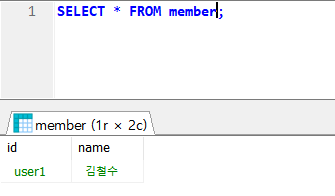
- Query 문으로 확인해보자
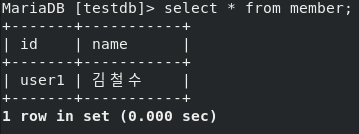
- MariaDB 내에서도 확인해보자

- 해당 Query를 보면 앞이 DB 이름이고, 뒤가 Table 이름이다. 허나, 이 방식을 꼭 지킬 필요 없이, 앞에서 USE 'DB 이름'을 썼으면, 다음에는 Table 이름만 써도 된다
- 데이터 입력 : INSERT
- 데이터 수정 : UPDATE
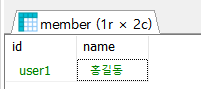
- 이름을 홍길동으로 바꿔보자

- 이름을 바꾸면 UPDATE를 사용한다. WHERE는 조건절이다

- 다음과 같이 as '사용할 이름' 을 사용하면, 출력에 column 이름이 입력한 사용할 이름으로 바뀌어서 출력된다
2. Snapshot 생성
-
Snapshot이란? 특정 시간에 데이터 저장 장치의 상태를 별도의 파일이나 이미지로 저장하는 기술로, 스냅샷 기능을 이용하여 데이터를 저장하면 유실된 데이터 복원과 일정 시점의 상태로 데이터를 복원할 수 있다
-
여기까지 진행했으면, 일단 CentOS에서 스냅샷을 찍어주자
-
현재 상태를 그대로 저장해서, 나중에 문제가 생길때 다시 현재 상태로 돌아올 수 있게 한다
-
Manager에 들어가면, 생성한 Snapshot을 확인할 수 있다
3. 관계형 DBMS
p.11
-
RDBMS의 핵심 개념은 "데이터 베이스는 테이블이라 불리는 최소 단위로 구성되어 있고, 하나의 테이블은 하나 이상의 열로 구성되어 있다" 이다
-
RDBMS의 Table
- 테이블 이라는 구조가 RDMS의 가장 기본적이고 중요한 구성이다
- 테이블의 관계를 기본 키와 외래 키를 사용해서 맺어줄 수 있으며, 관계가 맺어진 두 테이블을 조합해서 결과를 얻을려면 조인 기능을 이용하면 된다
- 테이블은 데이터를 효율적으로 저장하기 위한 구조이다
-
RDBMS의 장점
- 다른 DBMS에 비해 업무가 변화될 경우에 쉽게 변화에 순응할 수 있는 구조, 유지보수 측면에서도 편리한 특징을 가진다
- 대용량 데이터의 관리와 데이터 무결성의 보장을 잘 해주기에 동시에 데이터에 접근하는 응용 프로그램을 사용할 경우 RDBMS를 사용하는 것이 좋다
-
RDBMS는 데이터의 무결성을 보장받기 위하여 제약조건을 사용한다
p.105
- 해당 테이블에는 개인 기록을 반복해서 기록하기에 중복되는 데이터가 너무 많다. 또한, 빈 공간으로 인해 데이터 공간을 쓸데없이 차지하고 있다
- 이를 해결하기 위해 L자 구조를 사용했다
p.106
- 해당 페이지를 보면 빈 공간이 존재하는 기록들을 위로 모았다
- 하지만 데이터 공간 낭비는 존재하므로, Table을 나눴다
p.107
- 고객과 구매 테이블로 나눴다
- 허나, 고객 테이블에 중복된 데이터가 아직 존재한다
p.108
- 고객 테이블의 중복을 없앴다. 고객을 구분하기 위해 고객 이름을 구분자( 기본 키 / PK )로 설정했다
- 이 나눠진 테이블을 서로 관계를 맺게 해야한다
- 관계를 맺기 위한 매개체를 고객 이름 ( PK )으로 한다
- 구매 테이블이 고객 테이블을 참조해야 한다
- 구매 테이블에서 관계를 맺을때 참조하는 매개체를 참조 키( FK )라고 한다
4. 정보 시스템
p.43~54
-
정보 시스템 구축을 위한 5가지 단계
- 분석
- 설계
- 구현
- 시험
- 유지보수
-
데이터베이스 모델링과 필수 용어
- 기본 키 열 : 각 행을 구분하는 유일한 열로 중복되어서도, 비어 있어서도 안된다 ( not null )
-
데이터베이스 구축 절차
DB 생성 - TABLE 생성 - 입력 - 조회 / 활용
5. 데이터 활용 실습
P.60
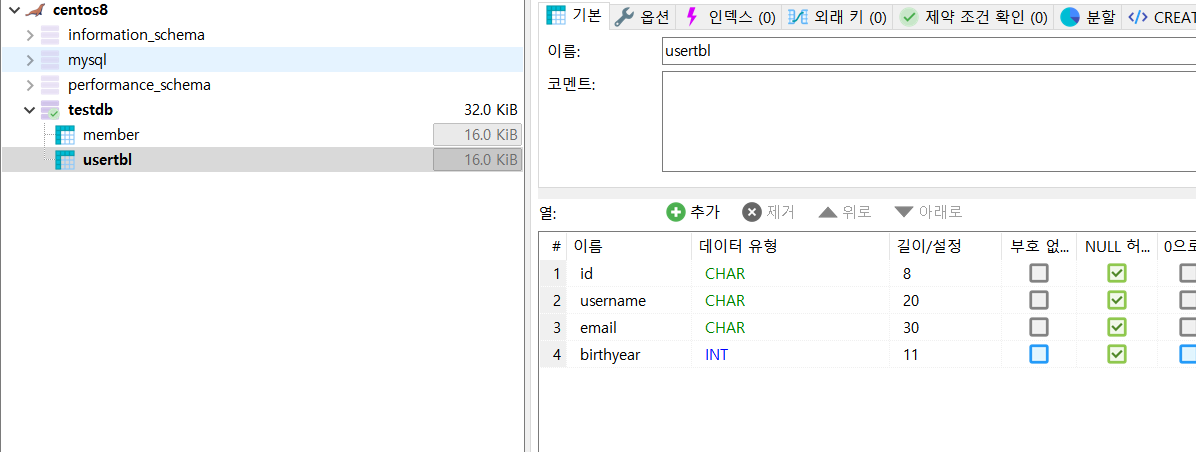
- usertbl의 정보를 확인하자
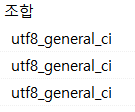
- 문자열 타입이 utf8로 설정됬음을 확인할 수 있다
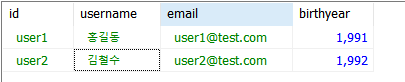
- username을 한글로 바꿔주자
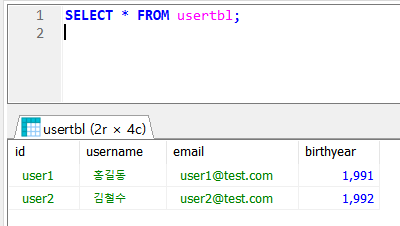
- Query로 확인하면 잘 변경된 것을 확인할 수 있다
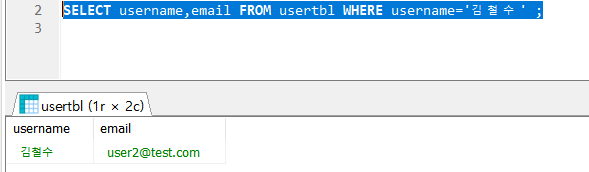
- username , email만 출력하는데, 조건문 ( where )을 통해 username이 김철수인 row의 Data를 출력한다
- '현재 쿼리 실행' 을 통해 해당 Query문을 실행하면 잘 실행된다
6. 테이블 외의 데이터베이스 개체의 활용
p.63
- 인덱스 : 처리 속도를 향상시킬 수 있는 튜닝 기법 중 하나이며, 특정 Row에 대하여 인덱스를 부여하면, 책의 뒷장에 특정 단어에 대한 페이지가 표시되는 것과 비슷한 원리를 이용하는 것이다
p.68
- 즉, 인덱스를 생성하기 전보다 생성한 것이 조회하는 것에 대한 성능이 훨씬 좋다
- 인덱스 생성에는 조심하자
7. 뷰
p.68
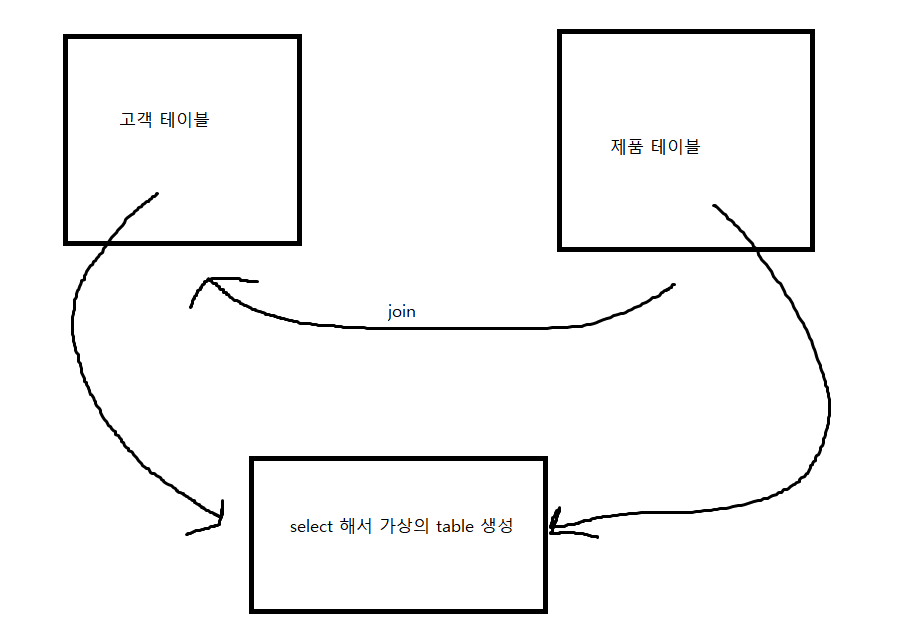
- 뷰를 select하면 실제 테이블의 데이터를 조회하는 것과 동일한 결과가 나온다
- 이는 테이블을 조회할때 테이블의 필요한 column들만 select해서 가상의 테이블을 만드는 것이다. 이 테이블은 실제하는 것이 아니며, 실체는 select다. 이 테이블이 바로 ' 뷰 ' 다
- 뷰는 하나의 테이블 처럼 작동하기에 권한을 줄 수 있으며, 공개 하고 싶지 않는 정보를 출력하지 않아서 보안상 결함을 해결할 수 있다!!!
- 뷰에는 보안상 select만 가능하게 한다
8. 뷰 실습
p.70
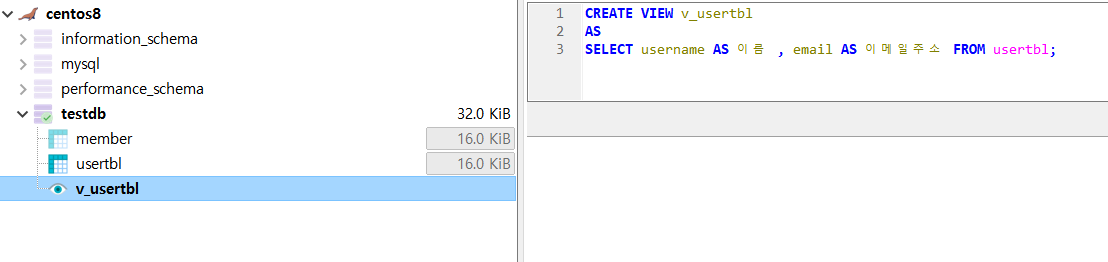
- view를 하나 생성한다
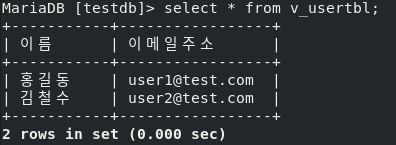
- DB에서 잘 확인된다

멋진 엔지니어가 될 때까지
Wow 정리 잘하셨네요 수업 안들어도 될정도... ;