
1. SQL & 제약 조건 돌아보기
p.313
-
제약조건
- 무결성을 보장하기 위한 제한된 조건
- PK, FK, UNIQUE, CHECK, DEFAULT 정의, NULL 허용
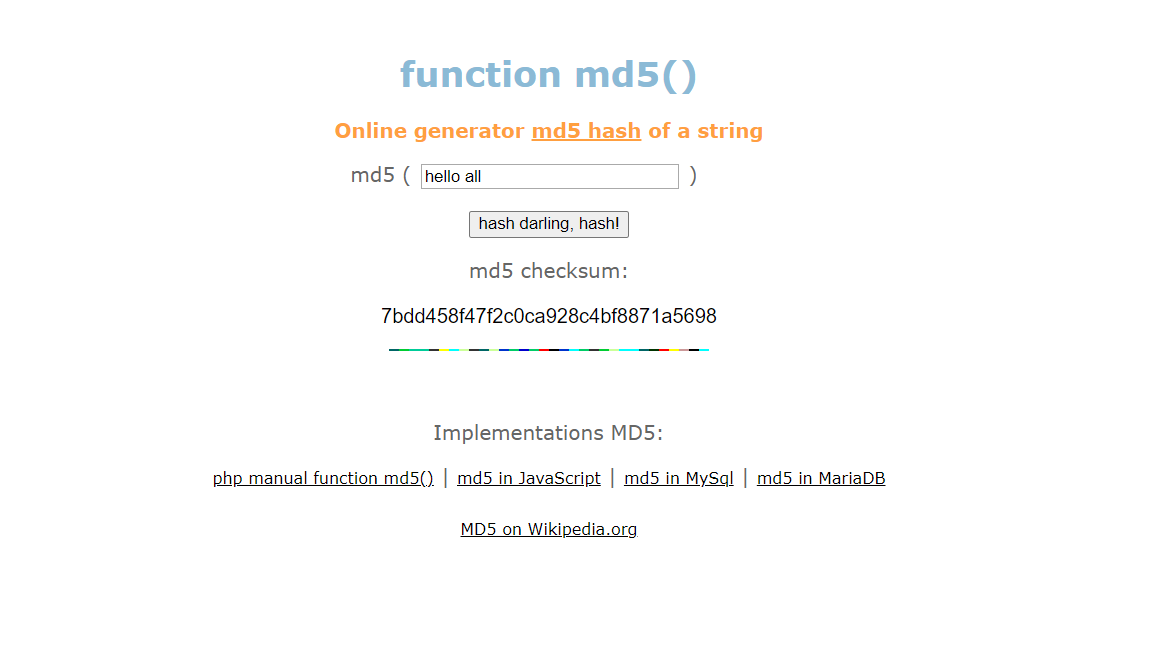
- Data 통신시 송신자는 이 md5와 같은 함수를 통해 Data를 토대로 Key 값을 만든다. Data를 받은 상대도 같은 함수를 통해 해당 Data를 토대로 Key 값을 만들어, 송신자와 수신자가 서로의 Key 값을 비교해서 Data의 위조 여부를 파악한다
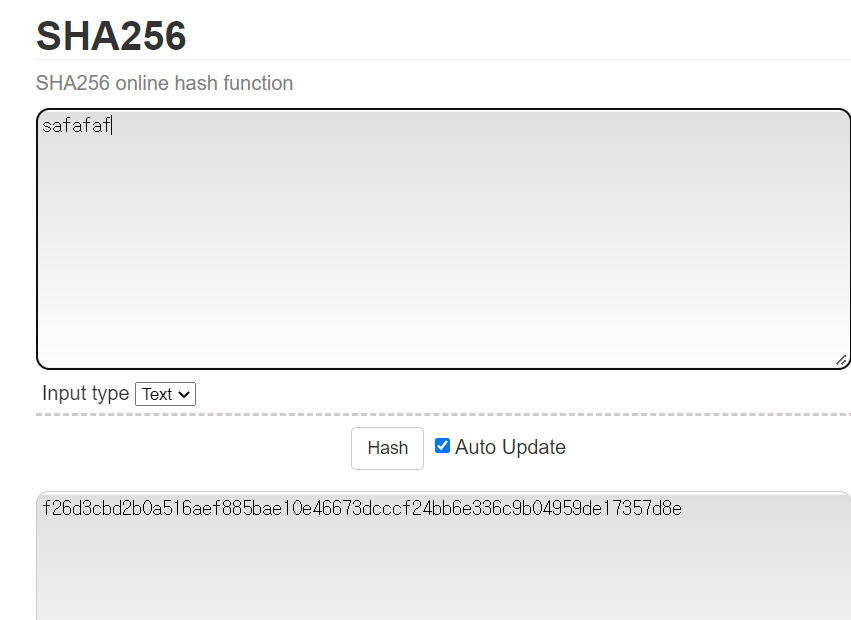
- 만약 Data가 너무 많을 경우 다수의 Data에 대해 함수를 돌렸더니 동일한 Key 값이 나와서 다수의 Data에 대해 Key 값이 중복되어 Data의 무결성이 깨질 수 있는 위험이 있다. 이를 방지하기 위해 Key 값의 길이를 늘린다. 이 md5보다 Key 값이 긴 SHA256 함수가 있다
-
기본키
- TABLE에 존재하는 많은 행의 DATA를 구분할 수 있는 유일 식별자
primary key(user id) / userid char(8) primary key - 별도로 not null을 표기할 필요가 없다
- TABLE에 존재하는 많은 행의 DATA를 구분할 수 있는 유일 식별자
-
외래키
- 두 테이블 사이의 관계를 통해 무결성을 보장 받을 수 있다. FK 를 따라가면 부모 테이블에서 유일한 값을 얻을 수 있다
- CASCADE : 원본 테이블 PK의 Data가 변경된 경우, 연결된 FK의 Data도 함께 변경되거나 삭제되도록 할 수 있다 ( p.320 )
- 두 테이블 사이의 관계를 통해 무결성을 보장 받을 수 있다. FK 를 따라가면 부모 테이블에서 유일한 값을 얻을 수 있다
-
UNIQUE
- PK와 동일하지만, NULL 값을 허용한다. 보통 ID가 PK라면, 휴대폰 번호는 UNIQUE로 지정할 수 있다
-
CHECK
- CHECK 제약 조건은 FRONT에서 DATA 유효성 검사와 같이, DB에 등록 전 범위나 조건등을 제시하여, 해당 조건에 부합하는 경우에만 DATA INSERT가 가능하도록 할 때 사용할 수 있다
-
DEFAULT 정의
- 특정 NOT NULL 에서 Data를 입력하지 않으면, 자동으로 입력되도록 하는 기본 값을 지정한다. 예를 들면, 지역을 입력하지 않으면 자동으로 '서울' 로 입력되도록 하여 NOT NULL 조건에 부합하도록 한다
-
NULL 허용
- NULL 을 허용하여 값이 입력되지 않아도, DB에 다른 열 정보가 입력되도록 할 수 있다
-
3 TIER 구조
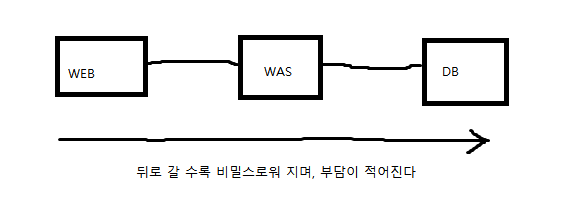
- 3 TIER 구조 : DB 쪽을 향해 갈 수록, 은밀해지며, 부담이 적어진다
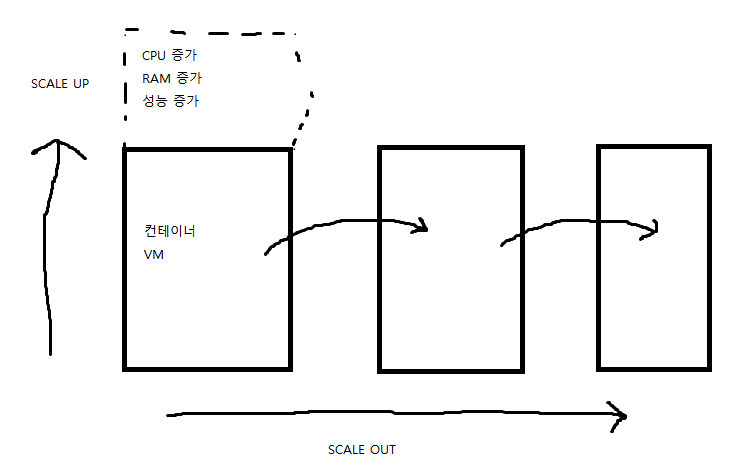
- 각 계층별로 오토 스케일링을 적용하여, 트래픽이 많아졌을 때 수평적 확장이 가능하다. 이는, 자원 사용 최대 % 를 지정하여, 만약 이 % 를 넘게 사용하면 오토 스케일링을 통해 수평적 확장을 한다. 최소 % 도 지정하여, 이 % 보다 작으면 축소를 한다
- 수직 스케일링 : SCALE UP으로 서버의 성능을 증가시킨다
- 수평 스케일링 : SCALE OUT으로 동일한 성능의 서버를 늘린다
- 3 TIER 구조 : DB 쪽을 향해 갈 수록, 은밀해지며, 부담이 적어진다
p.171
- SQL 문
- SELECT
SELCET 열이름 / 열이름 AS ' 표기되는 이름 ' / 집계 함수 ( 열이름 )
FROM 테이블 이름
WHERE 조건
GROUP BY 그룹화를 할 기준이 되는 열이름 ( 주로 집계 함수와 함께 사용 )
HAVING ' GROUP BY ' 뒤에 작성 해야되고, ' 집계 함수 ' 와 함께 사용되며 조건을 부여한다
ORDER BY 정렬 조건이 되는 열이름 + ASC ( 오름차순 ) / DESC ( 내림차순 ) - 서브 쿼리
- 쿼리 내에 또 다른 쿼리를 두는 방식으로, 예를 들어 " 이승기와 동일한 지역에 거주하는 사람들의 리스트 " 를 보고 싶다면, 주 쿼리의 where에 이승기의 거주 지역을 찾는 서브 쿼리를 넣어서 서브 쿼리 결과를 이용해 비교해야한다
- 만약, 서브 쿼리 결과 값이 다수라면 오류가 발생한다. 이를 해결하기 위해, 다수의 값을 각각 비교하는 하나의 조건이라도 만족하면 되는(OR) ANY 나, 다수의 값을 모두 비교해야하여 모든 조건을 만족해야 하는(AND) ALL 을 사용할 수 있다
- ORDER BY A DESC , B ASC
- 먼저, A에 대해 내림차순으로 정렬하고, 이때 동일한 A 값을 가진 경우, B에 대해 오름차순으로 정렬한다
- DISTINCT : 중복 제거
- LIMIT : 출력 갯수 제한
- GROUP BY
- 그룹화를 통해 지정한 Column을 묶어서 그룹을 형성해준다. 이때, 집계 함수를 사용해서, 이 그룹을 지정한 집계 함수를 통해 계산된 값을 출력해준다
- GROUP BY 에 조건을 건 Column은 Select절에서 반드시 명시해야 한다
- SELECT
2. SQL
p.201
-
HAVING
- Group By를 사용해서 그룹을 형성할 때 조건을 걸어준다
- 집계 함수를 사용할 때, where를 사용하면 오류가 난다
- 즉, 집계 함수에 조건을 제한하는 것
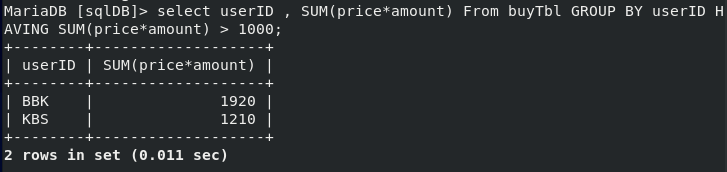
-
ROLL UP
- 총합 또는 중간 합계가 필요할 때 사용
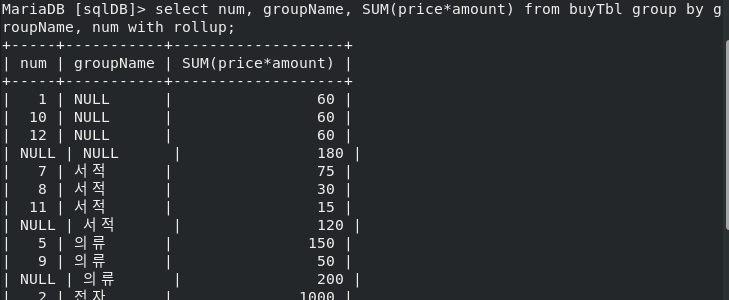
- 소합계와 총합계, 즉 , 중간 계산과 총 계산이 같이 출력된다
- NUM을 GROUP BY의 기준으로 추가했기에, 각 항목들이 묶이지 않고 표시된다. NUM은 PK이므로, PK로 묶일 수 없기 때문이다
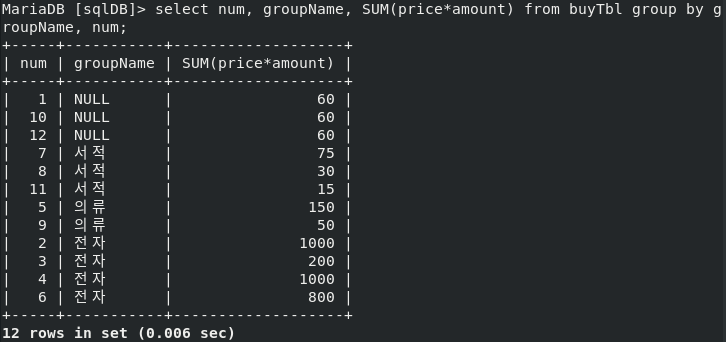
- ROLL UP이 없으면 다음과 같이 나온다
- 총합 또는 중간 합계가 필요할 때 사용
3. JOIN
p.263
JOIN이란?
- 두 개 이상의 TABLE을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것이다. 즉, 두 개 이상의 테이블을 연결하여 두 테이블에서 동시에 필요한 열 정보를 한 번에 출력할 수 있도록 해주는 방법이다
- 데이터 베이스의 테이블은 중복과 공간 낭비를 피하고, 데이터의 무결성을 위해서 여러 개의 테이블로 분리하여 저장한다. 이때, 이 분리된 테이블들은 서로 관계를 맺고 있다. 이 관계를 이용해 테이블들을 JOIN 할 수 있다
종류
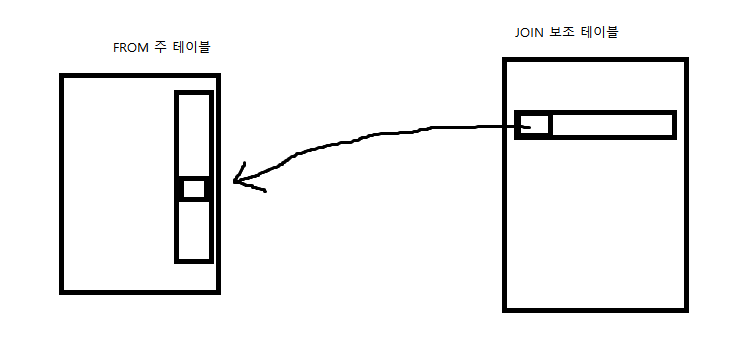
INNER JOIN ( 가장 널리 사용하는 방법 )
SELECT 열
FROM 주 테이블
INNER JOIN 보조 테이블
ON 조인될 조건
- 예제를 입력해보자
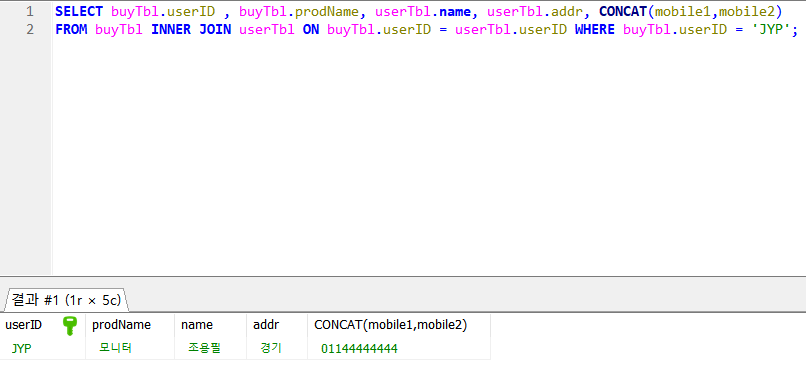
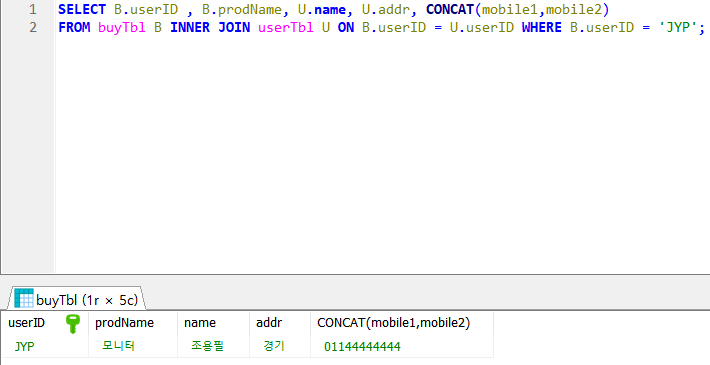
- 다음과 같이 두 TABLE을 합쳐서, 한 TABLE에 대해 조건을 걸어도 userID로 묶인 두 TABLE의 정보를 함께 출력한다. TABLE을 합쳤으므로, 두 TABLE의 컬럼명을 모두 사용할 수 있지만, 앞에 ' TABLE명 . 컬럼명 ' 을 통해 TABLE 명을 명시해야 한다
- 주 테이블과 보조 테이블은 서로 위치를 바꿔도 결과는 똑같고, 순서만 바뀐다. 보조 테이블의 조건이 되는 컬럼을 기준으로 주 테이블과 비교해서 합친다고 생각하면 된다
- 다음과 같이 출력한다. COMCAT은 안에 요소들을 한 줄로 합쳐서 출력해준다
- 위와 같이 FROM에서 TABLE 뒤에 대신 사용할 이름을 적어서 AS와 같이 이름을 변경해서 사용할 수 있다
- 전체 회원 정보를 출력해보자. 허나, 이는 전체 회원 정보가 아닌 구매한 기록이 있는 회원 정보이다. 구매 테이블에 데이터가 없으면 출력이 안되기 때문이다. 이를 해결할 수 있는게 OUTER JOIN이다
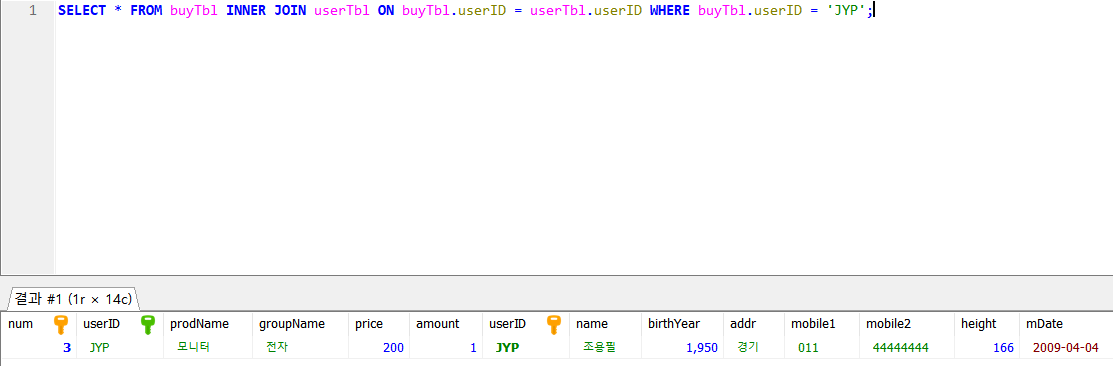
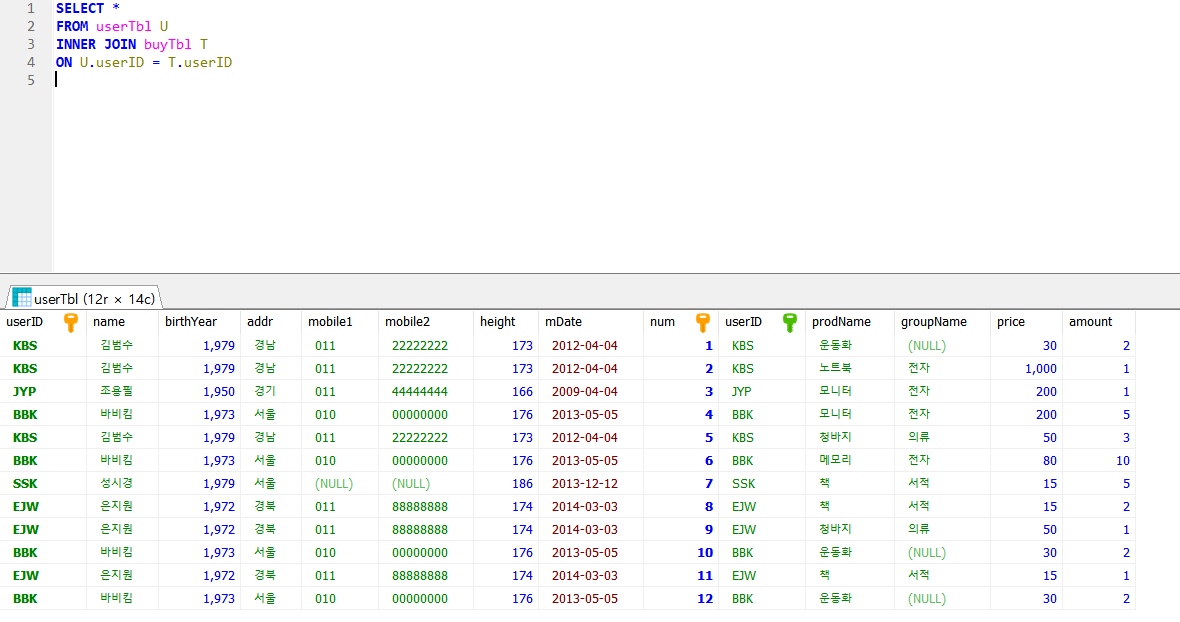
QUIZ. instance 테이블을 기준으로 host 테이블을 inner join 하여 여러분께서 생성하신 인스턴스 이름을 조건에 부여하여 전체 정보를 출력해보자
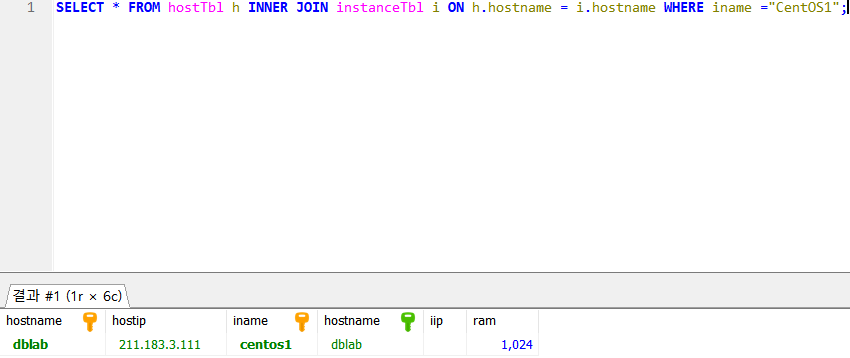
- 이렇게 작성하면 된다
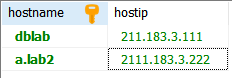
- Host를 하나 더 추가하자

멋진 엔지니어가 될 때까지