
현재 진행 중인 프로젝트의 막바지 단계에 투입되어 시나리오별 테스트를 수행하고, API 생성 및 수정, 모니터링 시스템 구축 등의 업무를 수행하고 있다.
프로젝트를 간단하게 요약하자면, 메세지 발송 플랫폼이다. 이 얘기를 하는 이유는 오늘 주제인 RabbitMQ를 설명하기 위함이다.
테스트를 하면서, 메세지를 1명부터 50만건까지 보냈을 때, 이 많은 데이터를 어떻게 안정적으로 보낼 수 있지? 라는 궁금증이 생겼고, 프로젝트 문서를 봤을 때 RabbitMQ를 사용하고 있었다.
먼저, 대량 메세지가 어떤 프로세스를 통해 전송이 되는지 알아보자.
50만건의 대량 메세지를 보냈을 경우 다음과 같은 플로우가 진행된다.
FRONTEND -> BACKEND(API) -> RabbitMQ -> BACKEND(EGN) -> 메세지 관련 외부 API
여기서 RabbitMQ가 하는 역할은 50만건의 대량 메세지를 Queue에 넣고, 순차적으로 발송을 할 수 있게 해준다.
이제 RabbitMQ가 무엇이고, 어떤 역할을 하는지 알아보자.
RabbitMQ란?
RabbitMQ는 메시지 브로커(Message Broker) 이다. 메시지를 보내는 쪽(Producer)과 받는 쪽(Consumer) 사이에서 메시지를 안전하게 전달해주는 중간 매개체 역할을 한다.
쉽게 말하면, 택배 물류센터와 같다. 보내는 사람이 물류센터에 택배를 맡기면, 물류센터가 분류해서 배달원에게 전달하는 것처럼, Producer가 RabbitMQ에 메시지를 넣으면, RabbitMQ가 알맞은 Queue로 분류해서 Consumer에게 전달한다.
AMQP란?
RabbitMQ는 AMQP(Advanced Message Queuing Protocol) 프로토콜을 사용한다.
AMQP는 메시지 지향 미들웨어를 위한 오픈 표준 프로토콜로, 클라이언트와 메시지 브로커 간의 통신 규약이다. HTTP가 웹 통신의 표준인 것처럼, AMQP는 메시지 큐 통신의 표준이라고 보면 된다.
AMQP의 주요 특징은 다음과 같다.
- 신뢰성: 메시지가 유실되지 않도록 보장 (ACK 메커니즘)
- 라우팅: Exchange와 Binding을 통한 유연한 메시지 분류
- 큐잉: 메시지를 큐에 저장하고 순서대로 처리
- 플랫폼 독립적: Java, Python, Node.js 등 언어에 상관없이 사용 가능
전체 통신 흐름은 다음과 같다.
Producer → (AMQP 프로토콜) → Broker(RabbitMQ) → (AMQP 프로토콜) → ConsumerRabbitMQ의 핵심 구성 요소
RabbitMQ는 5가지 핵심 구성 요소로 이루어져 있다.
Producer → Exchange → Binding → Queue → Consumer하나씩 알아보자.
1. Producer (생산자)
메시지를 만들어서 보내는 쪽이다. Producer는 메시지를 Queue에 직접 넣는 것이 아니라, Exchange에게 전달한다.
Producer: "이메일 50만건 보내줘"
↓ 메시지 전달 (routing key 포함)
Exchange이 프로젝트에서는 채널별 QueueSender 클래스들이 Producer 역할을 한다.
2. Exchange (교환기)
Producer로부터 메시지를 받아서 어떤 Queue에 보낼지 결정하는 라우터 역할을 한다. 우체국의 분류센터와 같다. 편지를 받으면 주소를 보고 어느 배달함에 넣을지 결정하는 것처럼, Exchange는 Routing Key를 보고 어느 Queue에 넣을지 결정한다.
Exchange에는 4가지 타입이 있다.
| 타입 | 설명 | 라우팅 방식 |
|---|---|---|
| Direct | Routing Key가 정확히 일치하는 Queue에 전달 | 1:1 매칭 |
| Topic | Routing Key의 패턴이 일치하는 Queue에 전달 | 와일드카드 매칭 (*, #) |
| Fanout | 연결된 모든 Queue에 전달 (Routing Key 무시) | 브로드캐스트 |
| Headers | 메시지 헤더 속성을 기준으로 전달 | 헤더 매칭 |
이 프로젝트에서는 Topic Exchange를 사용한다. Topic 타입에서 사용하는 와일드카드는 다음과 같다.
*: 단어 1개를 대체 (예:email.*.send→email.system1.send매칭)#: 0개 이상의 단어를 대체 (예:message.#→message.email.system1.send매칭)
3. Binding (바인딩)
Exchange와 Queue를 연결해주는 규칙이다. "이 패턴의 메시지는 이 Queue로 보내라"라는 라우팅 규칙을 정의한다.
예를 들어, 메시지 발송 플랫폼에서 채널별로 Binding을 설정하면 다음과 같다.
| Routing Key 패턴 | → 연결된 Queue |
|---|---|
email.*.send | email.send.queue |
sms.*.send | sms.send.queue |
push.*.send | push.send.queue |
Producer가 Routing Key를 email.system1.send로 보내면, Exchange가 Binding 규칙을 확인하고 email.*.send 패턴에 매칭되는 email.send.queue에 메시지를 넣는다.
4. Queue (큐)
메시지가 순서대로 쌓여서 대기하는 공간이다. Consumer가 처리할 때까지 메시지를 안전하게 보관한다. FIFO(First In, First Out) 구조로, 먼저 들어온 메시지가 먼저 처리된다.
이 프로젝트에서는 채널별로 Queue가 분리되어 있다. 채널별로 Queue를 분리한 이유는 독립성 때문이다. 만약 Queue가 하나라면, 이메일 발송이 밀릴 때 SMS 발송도 같이 밀린다. Queue를 분리하면 각 채널이 서로 영향을 주지 않고 독립적으로 처리할 수 있다.
5. Consumer (소비자)
Queue에서 메시지를 꺼내서 실제로 처리하는 쪽이다.
이 프로젝트에서는 채널별 Consumer 클래스들이 각 Queue를 감시하고 있다가, 메시지가 들어오면 꺼내서 외부 API를 통해 실제 발송을 실행한다.
6. 전체적인 구조
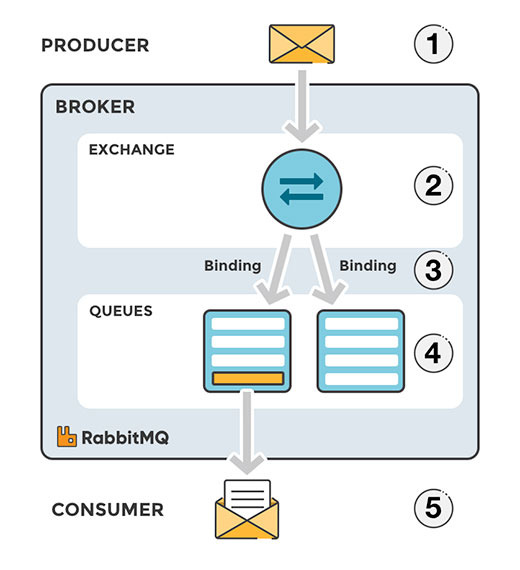
ACK (Acknowledgment)
Consumer가 메시지를 성공적으로 처리했는지 RabbitMQ에게 알려주는 메커니즘이다.
- ACK (Acknowledgment): "처리 완료했어" → Queue에서 메시지 제거
- NACK (Negative Acknowledgment): "처리 실패했어" → Dead Letter Queue로 이동
Queue에서 메시지 꺼냄
↓
Consumer가 처리 시도
↓
성공 → ACK 전송 → Queue에서 메시지 삭제
실패 → NACK 전송 → Dead Letter Queue로 이동ACK 모드에는 두 가지가 있다.
| 모드 | 설명 |
|---|---|
| Auto ACK | Consumer가 메시지를 받으면 자동으로 ACK 전송. 처리 도중 서버가 죽으면 메시지 유실 |
| Manual ACK | 코드에서 명시적으로 ACK/NACK를 전송. 처리 완료 후에만 ACK를 보내므로 메시지 유실 방지 |
이 프로젝트에서는 Manual ACK 모드를 사용한다. Consumer가 메시지를 꺼냈지만 처리 도중 서버가 죽어도, ACK를 보내지 않았기 때문에 메시지가 Queue에 남아있어서 유실되지 않는다.
Dead Letter Queue (DLQ)
처리에 실패한 메시지가 모이는 실패 전용 Queue이다.
메시지가 DLQ로 가는 경우는 다음과 같다.
- Consumer가 NACK를 보낸 경우 (처리 실패)
- 메시지 TTL(Time-To-Live)이 만료된 경우
- Queue가 가득 찬 경우
DLQ에 쌓인 메시지는 나중에 확인하고 원인을 분석하거나, 재처리할 수 있다.
정상 흐름: Exchange → Queue → Consumer → ACK → 완료
실패 흐름: Exchange → Queue → Consumer → NACK → Dead Letter Exchange → DLQ전체 흐름 정리
이메일 50만건을 발송하는 경우의 전체 흐름을 정리하면 다음과 같다.
1. Producer
"이메일 발송해줘" (routing key: email.*.send)
↓
2. Exchange (Topic Exchange)
routing key 확인 → email.*.send 패턴 매칭
↓
3. Binding
email.*.send → email.send.queue 규칙 적용
↓
4. Queue (email.send.queue)
메시지 대기 (FIFO)
↓
5. Consumer
Queue에서 메시지를 꺼내서 처리
↓
6. 외부 API
실제 이메일 발송
↓
7. 결과 처리
성공 → ACK → Queue에서 제거
실패 → NACK → DLQ로 이동RabbitMQ를 사용하는 이유
그렇다면 RabbitMQ 없이 API에서 바로 발송하면 안될까?
| RabbitMQ 없이 | RabbitMQ 사용 | |
|---|---|---|
| 대량 발송 | 50만건 요청 시 API 서버 과부하 | Queue에 넣어두고 순차적으로 처리 |
| 서버 장애 | 발송 중 서버가 죽으면 데이터 유실 | Queue에 남아있어서 복구 후 재처리 |
| 속도 조절 | 한번에 몰려서 외부 API 차단 위험 | 속도를 조절하며 순차 처리 |
| 채널 분리 | 이메일이 밀리면 SMS도 같이 밀림 | 채널별 Queue가 독립적으로 동작 |
| 재시도 | 실패 시 재시도 로직을 직접 구현 | DLQ에 쌓아두고 나중에 재처리 |
결국 RabbitMQ는 "지금 당장 처리할 수 없는 대량의 작업을 안전하게 쌓아두고, 유실 없이 순서대로 처리할 수 있게 해주는 시스템" 이다.
