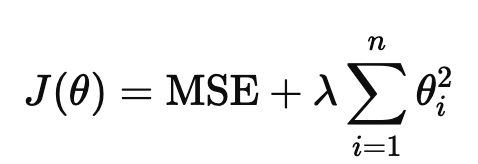
다중회귀를 하다보면 각 변수에 가중치들이 존재하게 되는데 그 가중치들에 대한 규제이다
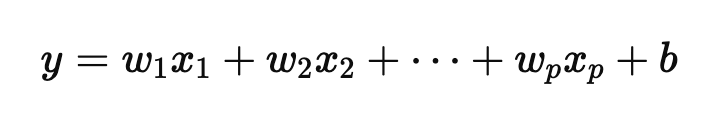
w : 가중치 b : 편향
왜 규제를 해주는데?
회귀에서 적절한 가중치와 편향을 찾는게 왜 중요하다
편향은 예측값을 조정해서 데이터의 평균적인 오차를 줄이고 가중치는 x 들의 중요도를 나타낸다
그 중 가중치에 대한 규제는 모델의 일반화 및 과적합 방지를 위해서 해준다
Lasso(L1 정규화)
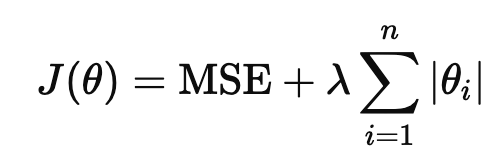
가중치의 절대값의 합이 특정 값 이하가 되도록 규제하는 것
- 장점
불필요한 변수를 제거할 수 있다 - 단점
변수간 상관관계가 높을때 선택한 변수가 불안정할 수 있다 - 사용예시
변수가 많은 고차원 데이터셋에 유용(불필요한 변수 제거 가능)
Ridge(L2 정규화)
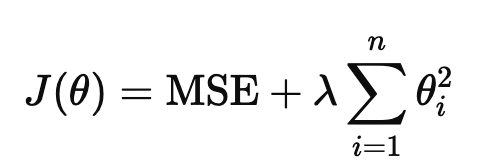
가중치의 제곱의 합이 특정 값 이하가 되도록 규제하는 것
가중치 값이 커지는 것을 방지해 모델 복잡도를 줄이고, 과적합을 완화할 수 있다
- 장점
과적합을 완화할 수 있다(가중치 값이 커지는것을 막을 수 있기 때문)
다중공선성 문제를 해결할 수 있다(다중공선성으로 인한 역핼렬 계산을 쉽게 만들어준다) - 단점
불필요한 변수는 제거할 수 없다 - 사용예시
다중공선성이 있는 데이터 셋
모든 변수를 고려해야 할 때
from sklearn.linear_model import Ridge, Lasso
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 데이터 생성
X, y = make_regression(n_samples=100, n_features=10, noise=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 릿지 회귀
ridge = Ridge(alpha=1.0)
ridge.fit(X_train, y_train)
ridge_pred = ridge.predict(X_test)
print("Ridge MSE:", mean_squared_error(y_test, ridge_pred))
# 라쏘 회귀
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
lasso_pred = lasso.predict(X_test)
print("Lasso MSE:", mean_squared_error(y_test, lasso_pred))
# 가중치 비교
print("Ridge Coefficients:", ridge.coef_)
print("Lasso Coefficients:", lasso.coef_)
------------------------------------------------------
Ridge MSE: 127.6001307094424
Lasso MSE: 104.93221988874525
Ridge Coefficients: [19.18928993 54.03791934 3.58580842 62.75934219 91.36596764 68.66297355
83.5355643 8.17128047 3.08538397 69.92804885]
Lasso Coefficients: [18.96025415 54.8553183 3.43132401 63.6082866 92.65442432 69.48209529
84.42789762 8.49332936 2.90087787 71.0628166 ]10개의 변수들에 대한 릿지/라쏘 가중치 값의 결과
두 가중치가 비슷하게 나옴을 확인

hi!