개념정리
1.K-Means Clustering
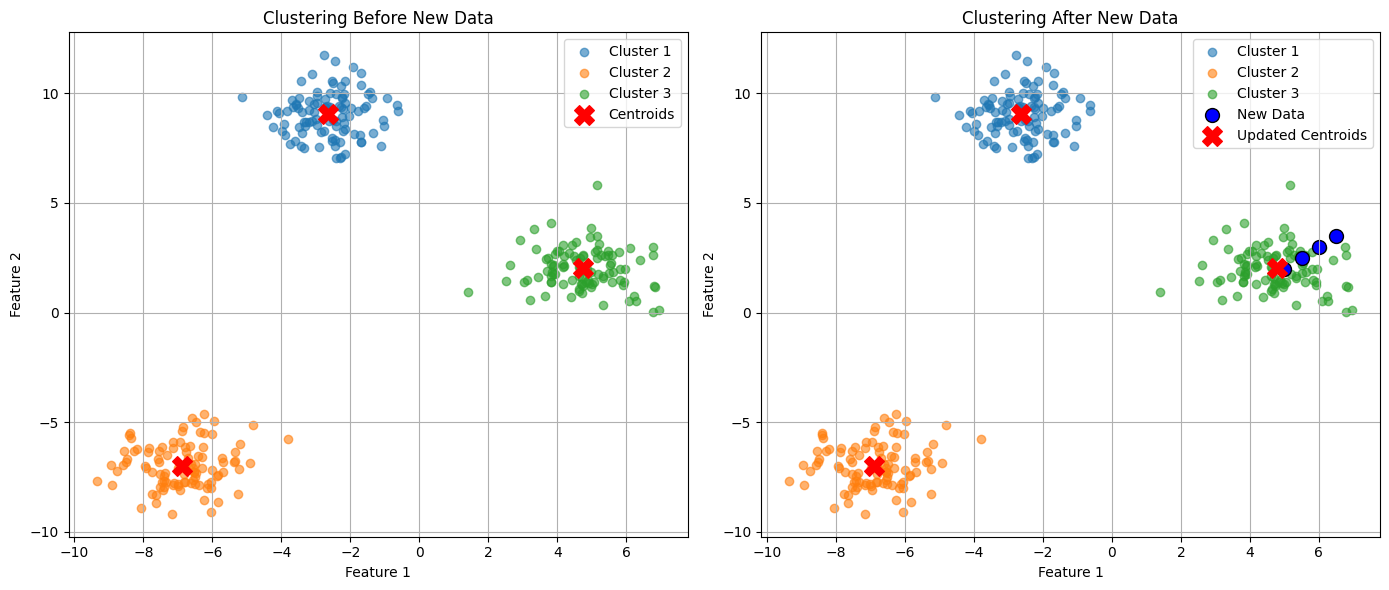
K-means clustering 이란?K 개의 데이터 중심을 기반으로 K 개의 군집(묶어진 데이터) 을 만들어주는것 답이 없는 비지도 학습에 속한다K 를 결정한다 (엘보우 방법 등 이용해서 직접 결정)평균을 기반으로 중심(Centroid) 을 결정한다 (!!중요!!)
2.군집화 평가지표-(1)실루엣 계수
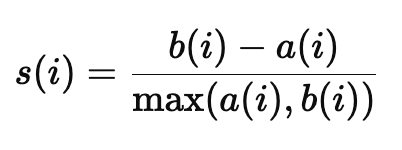
각 데이터가 같은 군집에는 얼마나 가깝게 군집화되었는지, 다른 군집에는 얼마나 멀리 있는지 나타내는 값\-1 ~ 1 사이이다\-1 : 잘못된 군집화 0 : 경계선에 위치 1 : 데이터가 잘 군집화 되어있다.범주형 변수에 대한 정보가 없을 경우 사용한다.비지도 학습이다.
3.분류모델 평가지표
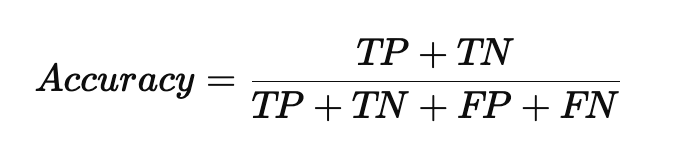
input data 를 사전에 미리 정해놓은 지도학습 중 하나이다,예시)< ML >선형모델 : 로지스틱 회귀 , SVM(소프트 벡터 머신)트리기반 : 의사결정나무, 랜덤포레스트, XGBoost, LighGBM, CatBoost거리기반 : K-nn< DL >다
4.회귀모델 성능평가
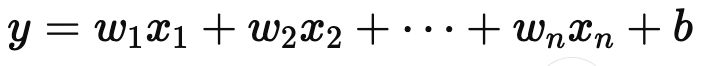
독립변수/설명변수(X)가 종속변수/목표변수(Y) 간 상관관계를 모델링해서 얼마나 영향을 미치는지 알아보기 위해 사용eg) 공부시간(X) 이 시험성적(Y) 에 얼마나 영향을 끼치는가?답(Y) 가 있으니 지도학습으로 분류된다x : 독립변수y : 종속변수w : 가중치/ 학습
5.편향과 분산
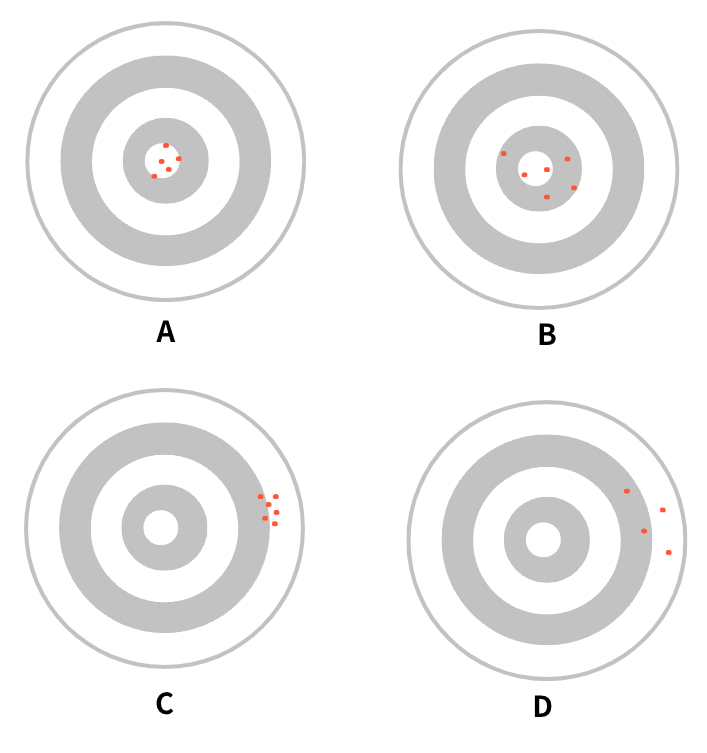
편향 : 모델이 학습데이터의 패턴을 충분하게 포참 못한경우 분산 :모델이 학습데이터에 과도하게 적합된 경우
6.파이썬 개념 다잡기

x == y 와 x is y 의 차이는? x == y : 두개의 내용 이 같은지 x is y : 두개의 주소 가 같은지 리스트 컴플리핸션 조건 없는 경우 <반환값 처리> for <변수> in <반복 가능 객체>if <반환값 처리> for <변
7.배깅과 부스팅
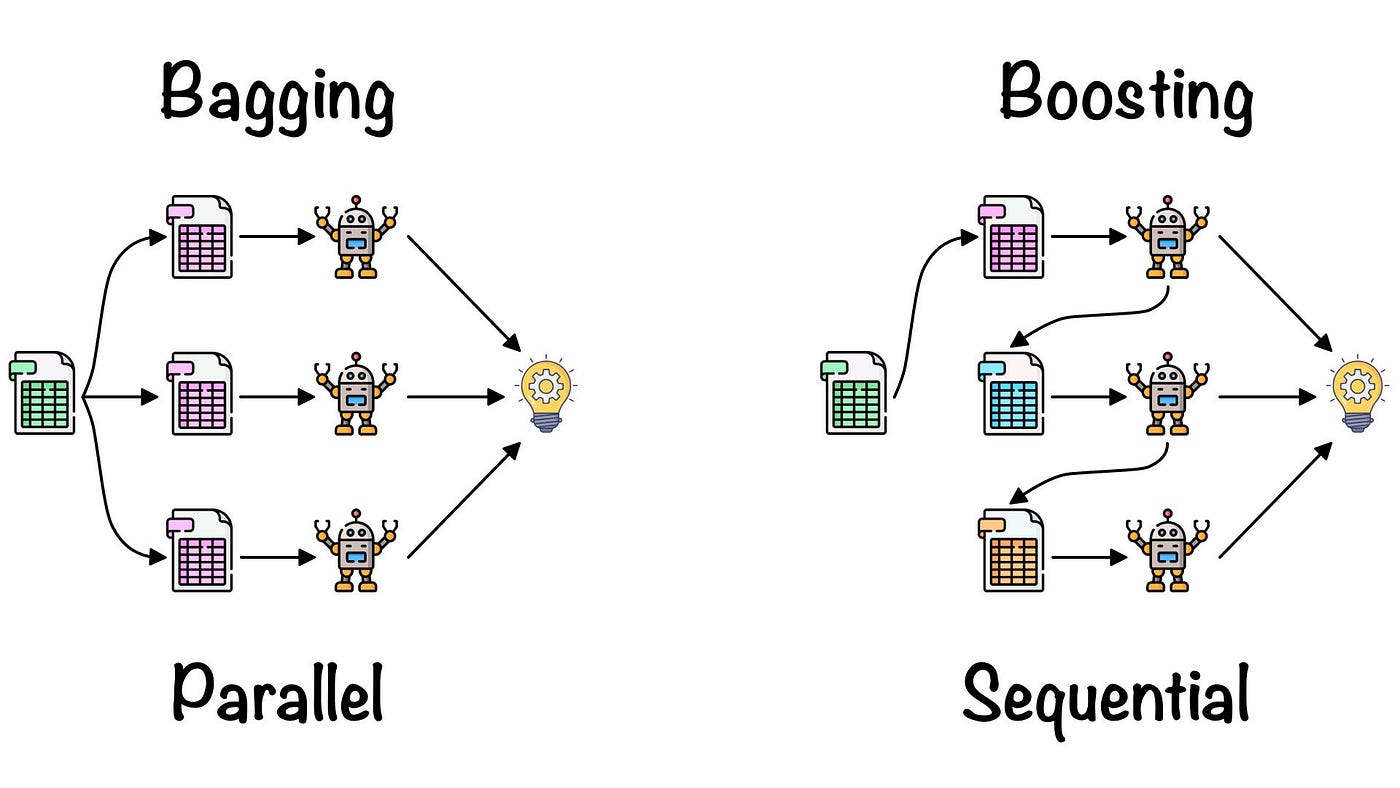
개별 모델보다 더 높은 예측성능을 위해서 여러개의 모델을 결합하는 방법 데이터 샘플을 무작위로 뽑아 모델을 학습시키고 결과를 결합해서 최종 예측값을 만드는 앙상블 기법장점 오버피팅과 모델의 분산을 줄일 수 있다병렬로 처리해서 학습속도가 빠르다 이상치나 노이즈가 많은 데
8.왜도와 첨도
왜도(Skewness)란? 분포의 비대칭정도를 나타내는 지표 평균을 기준으로 어느방향으로 얼마나 치우쳐져있는가를 나타낸다 왜도 0 : 양의 왜도(오른쪽) 장점 데이터의 비대칭, 이상치,편향을 탐지하게 좋다 데이터가 치우쳐져있을때 처리방법 로그변환 : 데이터값이
9.중심극한정리(CLT)
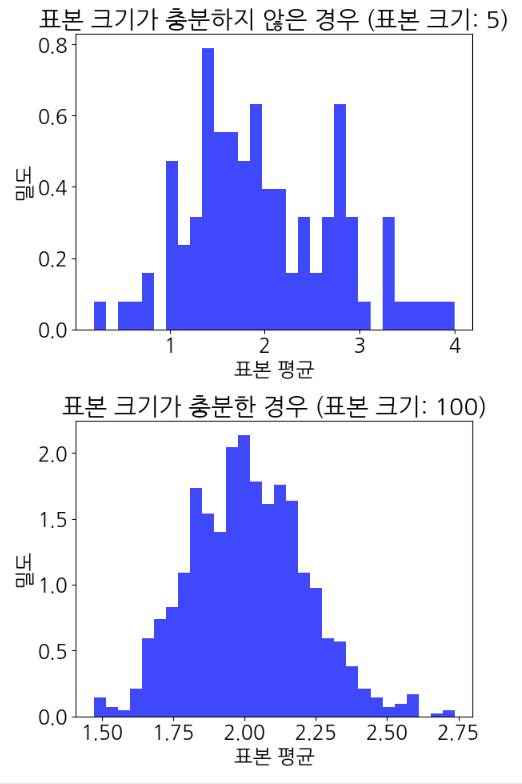
모집단에서 표본을 뽑을경우 모집단에 분포와 상관없이 표본의 크기가 커질수록 표본평균의 분포가 정규분포에 가까워진다는 정리 장점정규분포를 기반으로 설계된 z검정 , t검정을 가능하게 한다 신뢰구간을 계산할 수 있다 모수가 실제로 있을것이라 예측되는 범위 샘플이 얼마나
10.Feature(피처,변수,특징)

데이터의 특성을 나타내는 부분.표에서는 열이 해당된다 나이는 하나의 특성을 나타내는 예시머신러닝의 지도학습의 경우 타겟을 잘 예측할 수 있게 경우 다른 정보와 중복되지 않은 정보를 가질 경우 해석이 쉽고 직관적인 경우 값이 치우치지 않고 이상치가 적은 경우일관적인 패턴
11.교차검증(Cross Validation)

데이터셋을 여러개로 나눠 모델을 반복적으로 학습 및 평가를 해서 모델의 일반화 성능을 측정하는 방법모델의 과적합을 확인하고, 일반화된 성능 평가를 위해 사용한다데이터를 k개로 나누어 k개중 하나만 test 데이터로 잡고 K번 반복해서 학습을 진행하는 방법데이터의 불균형
12.ROC 곡선과 AUC
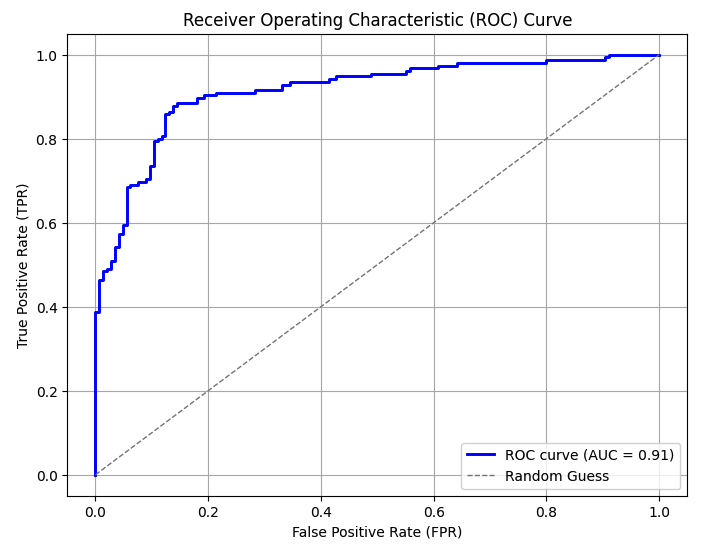
머신러닝의 이진분류 모델의 예측성능 판단하는 중요한 평가지표 위양성률(FPR)이 변할때 재현율(TPR)이 어떻게 변하는지를 나타내는 곡선이다 직선에 가까울수록 성능이 떨어지고 멀수록 성능이 좋다 임계값을 1부터 0까지 변화시켜가면서 FPR을 구해 FPR변화에 따른 TP
13.앙상블(Ensemble)
여러개의 약한 분류기를 생성하고 분류기로부터 나온 예측들을 결합해서 최종 예측을 도출하는 방법정형데이터 분류에서 뛰어난 성능을 보인다 투표를 통해 최종 예측 결과 결정 다른 알고리즘(모델) 을 사용한다 투표를 통해 최종 예측 결과 결정 같은 알고리즘(모델) 을 사용한
14.Lasso(L1 정규화) 와 Ridge(L2 정규화)
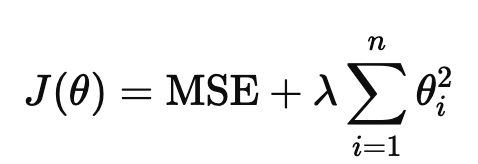
다중회귀를 하다보면 각 변수에 가중치들이 존재하게 되는데 그 가중치들에 대한 규제이다 w : 가중치 b : 편향 회귀에서 적절한 가중치와 편향을 찾는게 왜 중요하다 편향은 예측값을 조정해서 데이터의 평균적인 오차를 줄이고 가중치는 x 들의 중요도를 나타낸다 그 중 가중
15.POS Tagging
주어진 문장에서 각 단어에 적절한 품사를 붙여주는것 POS 단어, 구를 문법에 따라 구분하는 것 예시코드한국어 예시코드 자연어 처리를 수행할때 문장의 의미를 정확하게 분석할 수 있다
16.LSA, LDA, SVD

단어의 빈도수를 이용해 문장의 주제를 찾는 대신 문서의 잠재된 의미를 찾아내는 의미분석 방법SVD 를 사용한다토픽모델링에 자주 사용단어-문서 행렬을 SVD로 분해하여 주요 의미 축만 남기고 불필요한 노이즈를 제거중요한 정보만 유지하고 차원 축소를 하기위해 사용된다 크기
17.고유값과 고유벡터
고유값과 고유벡터n차원 실수 공간에서 n차원의점을 n차원으로 보내는 함수 = 선형 변환 함수고유값과 고유벡터가 중요한 이유?직교좌표계에서의 현상들이 다른 좌표계에서 변환되었을때 해석을할때 계산하기 쉽게 바뀔수 있다. 이때 변환시 필요한것 = 고유값, 고유벡터 고유값 =