[논문 리뷰] R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
Contents
- Introduction
- Object detection with R-CNN
- Visualization, ablation, and modes for error
- The ILSVRC2013 detection dataset
- Semantic segmentation
- Conclusion
1. Introduction
Visual recognition 분야에서, CNN 이전에는 SIFT와 HOG를 사용하거나, ensemble 효과를 통해 약간의 성능 발전을 이뤘다. 이 후, Lecun은 back propagation을 통한 SGD로 CNN을 효율적으로 학습시킬 수 있다는 것을 보여줬다.
2012년에 Krizhevsky가 ILSVRC image classification에서 CNN을 이용하여 높은 accuracy를 보여주면서, CNN에 대해 다시 관심을 갖기 시작했다. 이러한 관심은 ImageNet에 대한 CNN classification의 결과를 PASCAL VOC object detection에 일반화할 수 있는지에 대한 궁금증으로 확장되었다.
본 논문에서는, CNN이 기존의 HOG 기반의 system들에 비해 PASCAL VOC에서의 object detection 성능을 더 높게 이끌 수 있음을 보여준다. 이를 위해서, 두 가지 문제에 집중하고 있다.
- deep network를 이용하여 객체를 localizing 하는 것
- 조금의 labeled 된 detection data만을 이용하여 고성능 모델을 훈련시키는 것
image classification과 달리, object detection은 이미지 내의 객체에 대해 localizing을 필요로 한다. CNN localization 문제를 recognition using regions (object detection & semantic segmentation에서 성공적)로 해결한다.

recognition using regions의 과정은 다음과 같다.
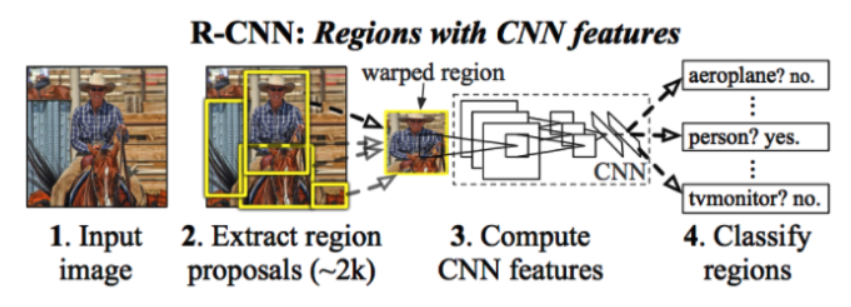
1. Selective search 알고리즘을 통해 객체가 있을 법한 위치인 region proposal을 2000개 추출
2. 추출한 proposal을 각각 227X227 크기로 warp
3. warp된 모든 region proposal을 fine tune된 AlexNet에 입력하여 2000X4096 크기의 feature vector를 추출
4. 추출된 feature vector를 linear SVM 모델과 Bounding box regressor 모델에 입력하여 각각 confidence score와 조정된 bounding box 좌료를 얻음
5. 마지막으로 Non Maximum Suppression 알고리즘을 적용하여 최소한의, 최적의 bounding box를 출력
Non Maximum Suppression (NMS)
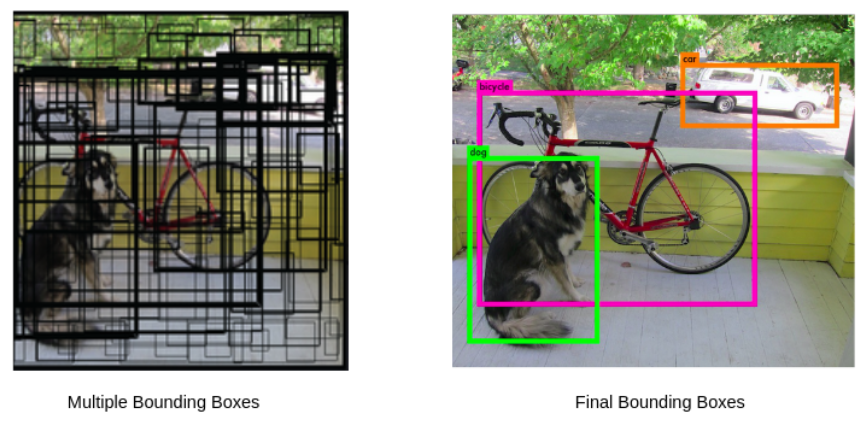
일반적으로 input image가 object detection 알고리즘을 통과하면 object에 bounding box가 그려지며 어떤 물체일 확률 score를 가지게 된다. 이때 위 그림처럼, 하나의 object에 많은 bounding box가 생긴다. 동일한 object에 여러개의 bounding box가 존재한다면, 가장 스코어가 높은 box만 남기고 나머지를 제거하는 것을 Non Maximum Suppression (NMS)라고 한다.
2. Object detection with R-CNN
객체 인식 시스템은 다음 3개의 모듈로 구성된다.
- category-independent region proposal 생성 (detector에서 사용할 수 있는 후보 영역 세트)
- 각 region에서 고정된 길이의 feature vector를 추출하기 위한 CNN 사용
- 분류로 linear SVM 사용
2.1 Module design
Region proposals
Region proposal이란, image에서 object가 있을 만한 영역을 찾는 것이다. 기존의 detection 방법에는 Sliding Window(Exhaustive search) 방식을 통하여 score를 얻었지만, 이러한 방식은 효율성 측면에서 떨어진다는 단점이 존재한다. 따라서, 본 논문에서는 영역을 생성하는 과정에서 Selective Search 알고리즘을 사용한다. Selective Search 알고리즘은, 주변의 색감과 질감의 차이, 둘러 쌓여있는지에 대한 여부 등을 파악하여 물체의 위치를 파악하는 알고리즘이다. 초반에 생성된 수많은 bounding box들을 merge하여 줄여나가면서 물체의 위치를 조금 더 정확하게 파악한다.
Frature extraction
region proposal에서 4096차원의 feature vector를 추출한다. feature는 5개의 convolutional layer들과 2개의 fully connected layer를 통해 평균을 뺀 227X227 RGB image를 forward propagating하여 계산한다.
2.2 Test-time detection
Run-time analysis
2.3 Training
Supervised pre-training
Domain-specific fine-tuning
Object category classifiers
2.4 Results on PASCAL VOC 2010-12
2.5 Results on ILSVRC2013 detection
3. Visualization, ablation, and modes of error
3.1 Visualizing learned features
3.2 Ablation studies
3.3 Network architectures
3.4 Detection error analysis
3.5 Bounding-box regression
3.6 Qualitative results
4. The ILSVRC2013 detection dataset
5. Semantic segmentation
6. Conclusion
