
웹 크롤링과 웹 스크레핑
- 자주 혼용되는 두 단어, 차이는 무었일까?
웹 스크레핑
- 웹 페이지들로부터 우리가 원하는 정보를 추출

웹 크롤링
- 크롤러(Crowler)를 이용하여 웹 페이지의 정보를 인덱싱

정리
- 웹 스크레핑 : 특정한 목적으로 특정 웹 페이지에서 데이터를 추출하는 것 - 데이터 추출
- e.g : 날씨 데이터 가져오기, 주식 데이터 가져오기, ...
- 웹 크롤링 : URL을 타고 다니며 반복적으로 데이터를 가져오는 과정 - 데이터 색인
- e.g : 검색 엔진의 웹 크롤러
올바르게 HTTP 요청하기
- 웹 스크래핑 / 크롤링을 통해 어떤 목적을 달성하고자 하는가?
- 나의 웹 스크레핑 / 크롤링이 서버에 영향을 미치지는 않는가?
로봇 배제 프로토콜 (REP)
-
웹 브라우징은 사람이 아닌, 로봇이 진행할 수 있다.
그렇다면 무턱대고 모든 사이트에 대해 모든 정보를 취득하는 것이 정당한가? -
이에 대한 해결책으로 1994년, REP(Robot Exclusion Protocol)이 탄생하였다.
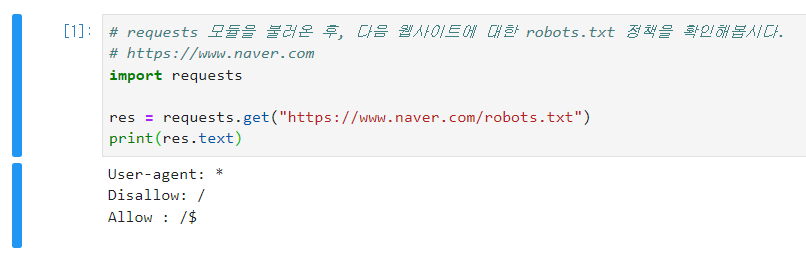
robots.txt
- User-agent, Disallow, Allow 등의 키워드를 통해 사용
- 웹 크롤러 들은 이 규칙을 지키면서 크롤링을 진행
예시

User Agent
- 사용자 에이전트는 요청을 보내는 것의 주체를 나타내는 프로그램 입니다.
- 웹서버에 요청할 때 사용자 에이전트 HTTP 헤더에 나의 브라우저 정보를 전달하면 웹서버가 나를 진짜 사용자로 인식할 수 있게 됩니다.
- 나의 User Agent 정보 확인하기
https://www.whatismybrowser.com/detect/what-is-my-user-agent/
robots.txt 가져오기
- robots.txt는 웹 페이지의 메인 주소에 '/robots.txt'를 입력하면 확인 할 수 있습니다.


AI Tensorflow Python