
브로드캐스팅
-
Numpy에서는 같은 모양의 배열이 아니더라도 연산이 가능합니다.- 상수를 배열에 더하거나
- 모양이 다른 배열끼리 덧셈 연산이 가능합니다(단, 특정 조건을 갖춘 배열이여야 합니다).
- 이와 같이 Numpy에서 배열의 모양이 다르더라도 자동으로 맞춰 연산하는 것을 브로드캐스팅이라고 합니다.
>>> A = [ [10, 10, 10, 20, 20], [21, 87, 31, 25, 64], [16, 39, 10, 23, 30], [88, 13, 52, 12, 47], [53, 23, 41, 16, 73] ] >>> A = np.array(A) >>> result1 = A + 13 >>> print(result1) [[23 23 23 23 23] [33 33 33 33 33] [43 43 43 43 43] [53 53 53 53 53] [63 63 63 63 63]] >>> B = np.array([1, 2, 3, 4, 5]) >>> result2 = A + B >>> print(result2) [[11 12 13 14 15] [21 22 23 24 25] [31 32 33 34 35] [41 42 43 44 45] [51 52 53 54 55]]
Numpy dot 메소드
Numpy의dot()메소드를 이용하여 2차원 배열(행렬) 곱을 연산합니다.
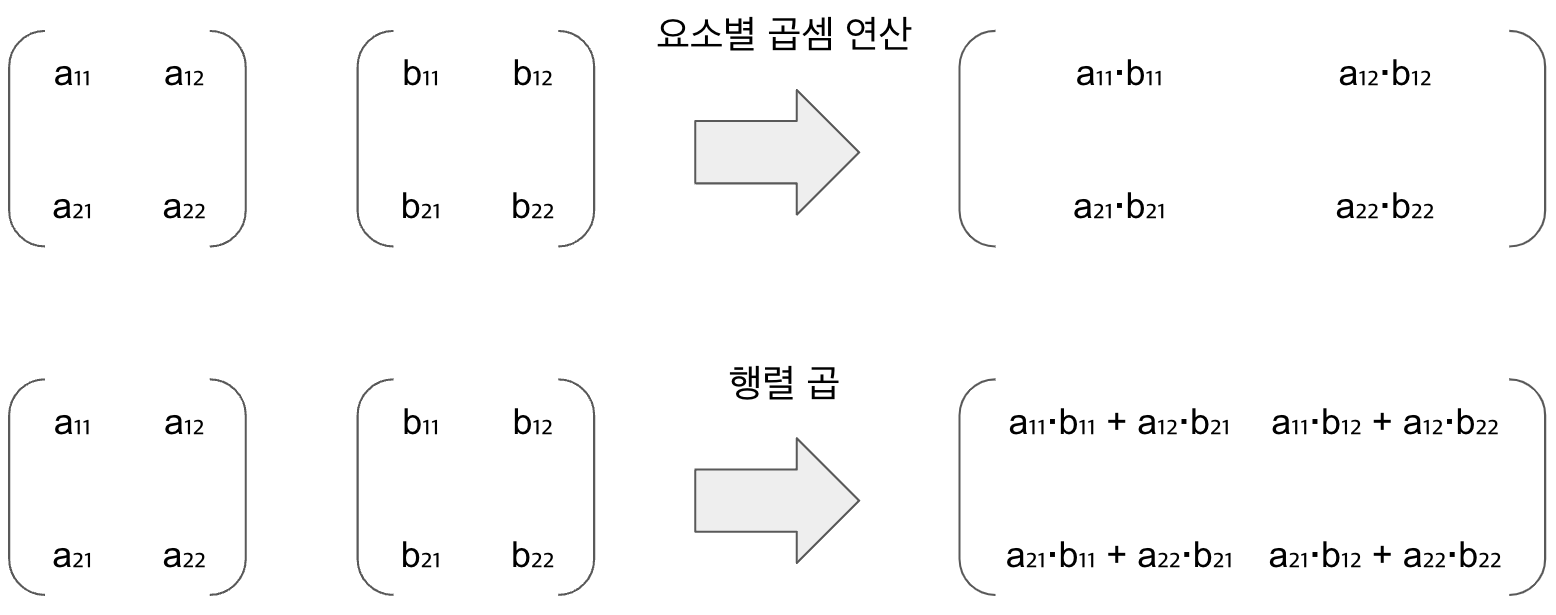
행렬 곱셈 연산과 행렬 곱 차이
*연산자를 사용하여 행렬 간 같은 위치(인덱스)의 요소별로 곱셈 연산과 행렬 곱 연산은 아래 그림과 같이 다르게 연산합니다.
dot 메소드
- dot 연산은 다음과 같이 구현할 수 있습니다.
-
A.dot(B) -
np.dot(A, B)>>> import numpy as np >>> A = np.array([[1, 2], [2, 3]]) >>> B = np.array([[4, 1], [6, 7]]) >>> print(A * B) [[4 2] [12 21]] >>> print(A.dot(B)) [[16 15] [26 23]] >>> print(np.dot(A, B)) [[16 15] [26 23]]
- 직접 계산하여 구한 행렬 곱 연산 결과와 코드에서 출력된 연산 결과가 동일합니다. 그리고 앞서 언급했던
*연산자를 사용한 연산 결과와dot함수를 사용한 연산 결과가 다른 것도 알 수 있습니다.
-
1차원 행렬 슬라이싱 1
Numpy의 슬라이싱을 이용하면 1차원 배열의 특정 구간의 요소들을 읽어올 수 있습니다.
1차원 리스트 및 배열의 슬라이싱
- 1차원 리스트 슬라이싱을 할 때
li[start:end]와 같이 작성하면list인li에서start이상end미만의 요소들을 선택합니다. 1차원 배열 슬라이싱도 마찬가지로arr[start:end]와 같이 작성하면numpy.ndarray인arr에서start이상end미만의 요소들을 선택합니다. 아래 코드를 보며 확인해보도록 하겠습니다.-
1차원 리스트 슬라이싱
-
크기가 10인 1차원 리스트를 생성한다.
-
세 번째부터 여섯 번째까지 요소들을 선택하여 리스트를 출력한다.
>>> li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> print(li[3:7]) [4, 5, 6, 7] -
-
1차원 배열 슬라이싱
-
크기가 10인 1차원 배열을 선언한다.
-
세 번째부터 여섯 번째까지 요소들을 선택하여 배열을 출력한다.
>>> import numpy as np >>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) >>> print(arr[3:7]) [4 5 6 7]
-
-
1차원 리스트 및 배열은 타입만
list,numpy.ndarray로 다를 뿐, 둘 다 동일한 방식으로 코드를 작성하여 슬라이싱을 할 수 있습니다.
-
1차원 행렬 슬라이싱 2
Numpy의 슬라이싱을 이용하면 1차원 배열의 특정 구간의 요소들을 변경할 수 있습니다.
1차원 리스트의 슬라이싱을 이용한 값 변경
- 리스트는 슬라이싱을 한 구간의 크기와 상관없이 임의의
list를 대입하여도 에러가 발생하지 않고 변경됩니다.
>>> import numpy as np
>>> arr= np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> arr[3:7] = np.array([100, 45, 60, 75])
>>> print(arr)
[ 1 2 3 100 45 60 75 8 9 10]
>>> arr[3:7] = np.array([1, 1, 1, 1, 1])
ValueError: could not broadcast input array from shape (5,) into shape (4,)1차원 배열의 슬라이싱을 이용한 값 변경
list의 리스트와 달리numpy.ndarray의 배열을 슬라이싱하여 값을 변경할 때, 크기 또는 모양이 맞지 않으면 에러를 발생합니다. 즉, 슬라이싱을 이용하여 값을 변경할 때는 대입할 배열의 모양이 슬라이싱을 한 구간과 일치해야 합니다.
>>> import numpy as np
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> arr[3:7] = 100
>>> print(arr)
[ 1 2 3 100 100 100 100 8 9 10]브로드캐스팅, 슬라이싱을 이용한 값 변경
>>> import numpy as np
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> arr[3:7] = 100
>>> print(arr)
[ 1 2 3 100 100 100 100 8 9 10]- 브로드캐스팅이 적용되어 100을 크기가 4인 1차원 배열로 확장시킨 후
arr에 대입하였습니다. 그 결과 3번 인덱스부터 6번 인덱스까지 100으로 변경된 것을 확인할 수 있습니다.
2차원 행렬 슬라이싱 1
Numpy를 사용하여 2차원 배열의 슬라이싱을 해봅시다.
2차원 리스트 및 배열의 슬라이싱
- 2차원 리스트 및 배열의 슬라이싱에 대해서
list와numpy.ndarray는 다른 방식으로 코드를 작성합니다. 둘의 차이점에 대해서 비교하고 고차원 배열을 슬라이싱할 때 간단하게 작성할 수 있는Numpy의 슬라이싱 기능을 살펴봅시다.
2차원 리스트 슬라이싱
>>> li = [
[1, 2, 3, 4, 5],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9],
[10, 11, 14, 15, 17]
]
>>> li2 = []
>>> for i in range(1, 3):
... li2.append(li[i][2:4])
...
>>> print(li2)
[[6, 7], [7, 8]]
>>> print([x[2:4] for x in li[1:3]])
[[6, 7], [7, 8]]- 새로운 리스트
li2을 생성하고for문과 1차원 리스트 슬라이싱을 이용하여 2차원 리스트 슬라이싱을 했습니다. 이처럼 2차원 리스트의 슬라이싱 코드는 앞서 1차원 리스트 슬라이싱보다 비교적 간단하지 않습니다.
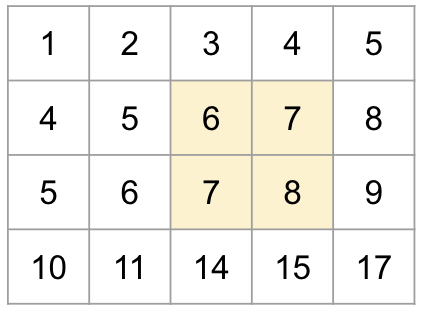
2차원 배열 슬라이싱
- 특정 요소 읽어오기에서 우리는
,를 기준으로 차원을 구별하여 인덱싱을 한 적이 있습니다. 슬라이싱도 마찬가지로,를 기준으로 차원을 구별하고, 각 차원마다 특정 구간을 슬라이싱하여 요소들을 선택할 수 있습니다. 그럼Numpy의 2차원 배열 슬라이싱 방식을 살펴보겠습니다.
>>> import numpy as np
>>> arr = np.array([
[1, 2, 3, 4, 5],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9],
[10, 11, 14, 15, 17]
])
>>> print(arr[1:3, 2:4])
[[6 7]
[7 8]]- 이처럼 Numpy의 슬라이싱 기능을 사용하면 2차원 이상의 고차원 배열일지라도 쉽게 특정 구간을 선택할 수 있습니다.
2차원 배열 슬라이싱 2
Numpy를 이용하여 2차원 배열의 슬라이싱을 이용한 값 변경을 해봅시다.
2차원 배열의 슬라이싱을 이용한 값 변경
일반적인 슬라이싱을 이용한 값 변경
- 2차원 슬라이싱도 1차원 슬라이싱과 마찬가지로 값을 변경할 때는 동일한 모양의 배열로 대입해야 합니다.
>>> import numpy as np
>>> arr = np.array([
[1, 2, 3, 4, 5],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9],
[10, 11, 14, 15, 17]
])
>>> arr[1:3, 1:3] = np.array([[10, 20], [30, 40]])
>>> print(arr)
[[ 1 2 3 4 5]
[ 4 10 20 7 8]
[ 5 30 40 8 9]
[10 11 14 15 17]]브로드캐스팅 슬라이싱을 이용한 값 변경
- 브로드캐스팅을 통해 선택한 구간 내 요소들의 값을 10으로 변경했습니다.
>>> import numpy as np
>>> arr = np.array([
[1, 2, 3, 4, 5],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9],
[10, 11, 14, 15, 17]
])
>>> arr[1:3, 1:3] = 10
>>> print(arr)
[[ 1 2 3 4 5]
[ 4 10 10 7 8]
[ 5 10 10 8 9]
[10 11 14 15 17]]
n × n

AI Tensorflow Python