
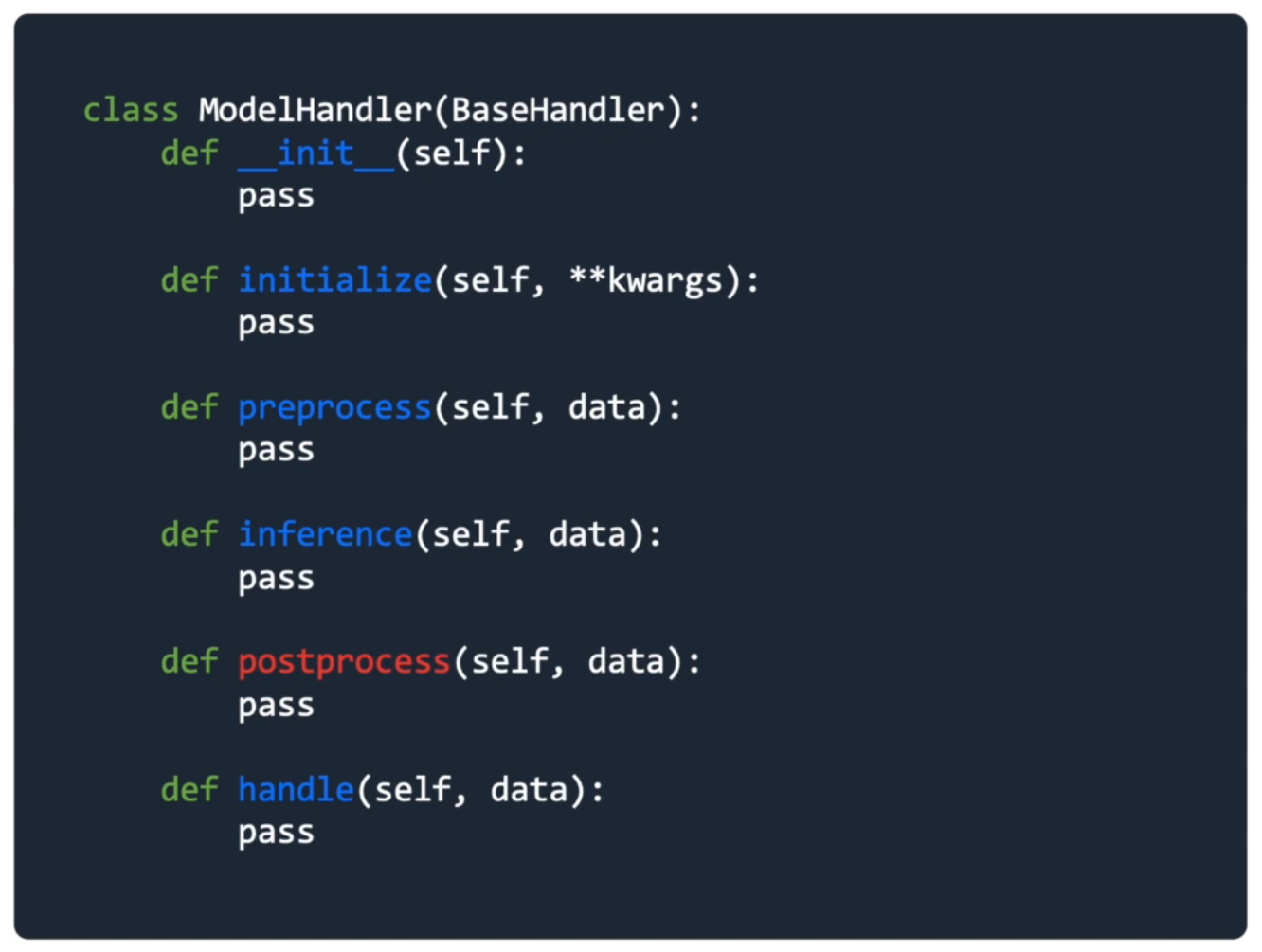
Inference를 위한 model handler 개발
Handle
- 요청 정보를 받아 적절한 응답을 반환
- 정의된 양식으로 데이터가 입력됐는지 확인
- 입력 값에 대한 전처리 및 모델에 입력하기 위한 형태로 변환
- 모델 추론
- 모델 반환값의 후처리 작업
- 결과 반환
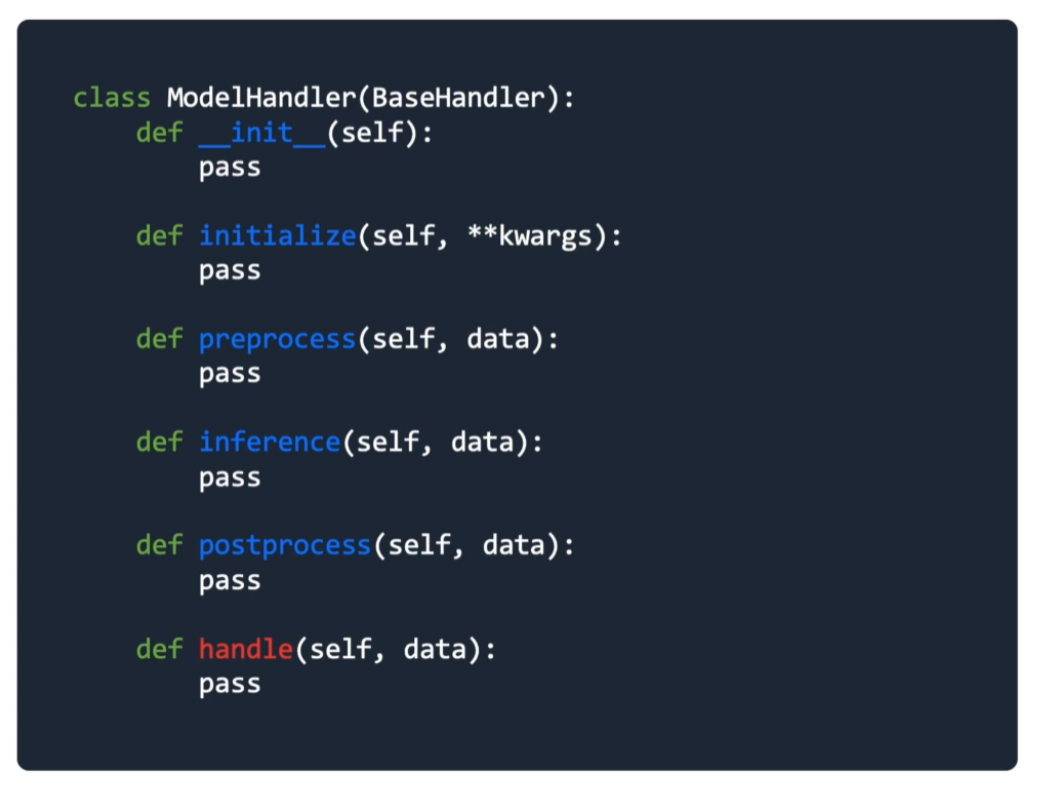
def handle(self, data):
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)Initialization
- 데이터 처리나 모델, configuration 등 초기화
- Configuration 등 초기화
- (Optional) 신경망을 구성하고 초기화
- 사전 학습한 모델이나 전처리기 불러오기(De-serialization)
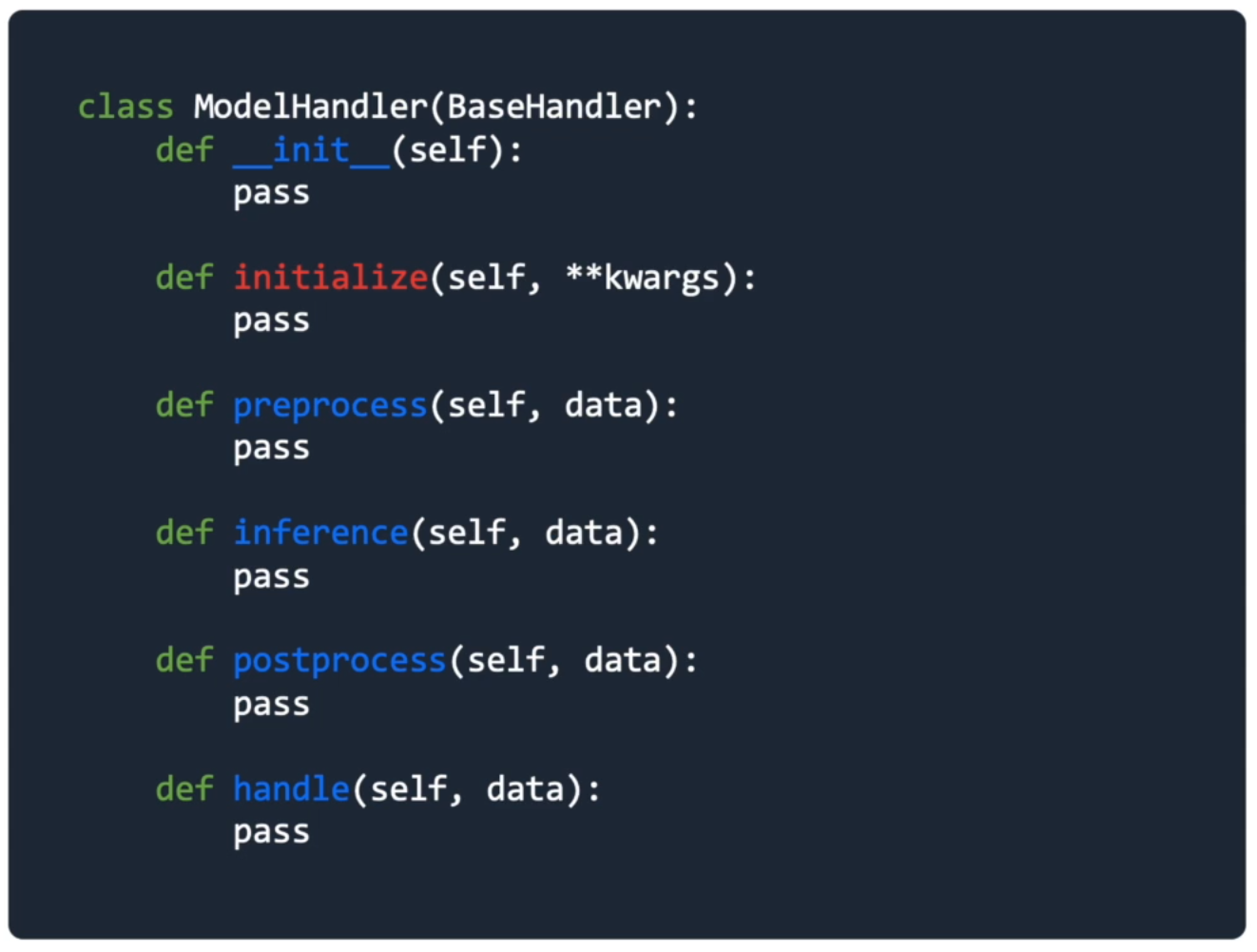
def initialize(self, ):
#De-serializing model and loading vectorizer
import joblib
self.model = joblib.load('model/ml_model.pkl')
self.vectorizer = joblib.load('model/ml_vectorizer.pkl')PreProcess
- Raw input을 전처리 및 모델 입력 가능 형태로 변환
- Raw input 전처리
데이터 클렌징의 목적과 학습된 모델의 학습 당시 scaling이나 처리방식과 맞춰주는 것이 필요 - 모델에 입력가능한 형태로 변환
vectorization, converting to id 등의 작업
- Raw input 전처리
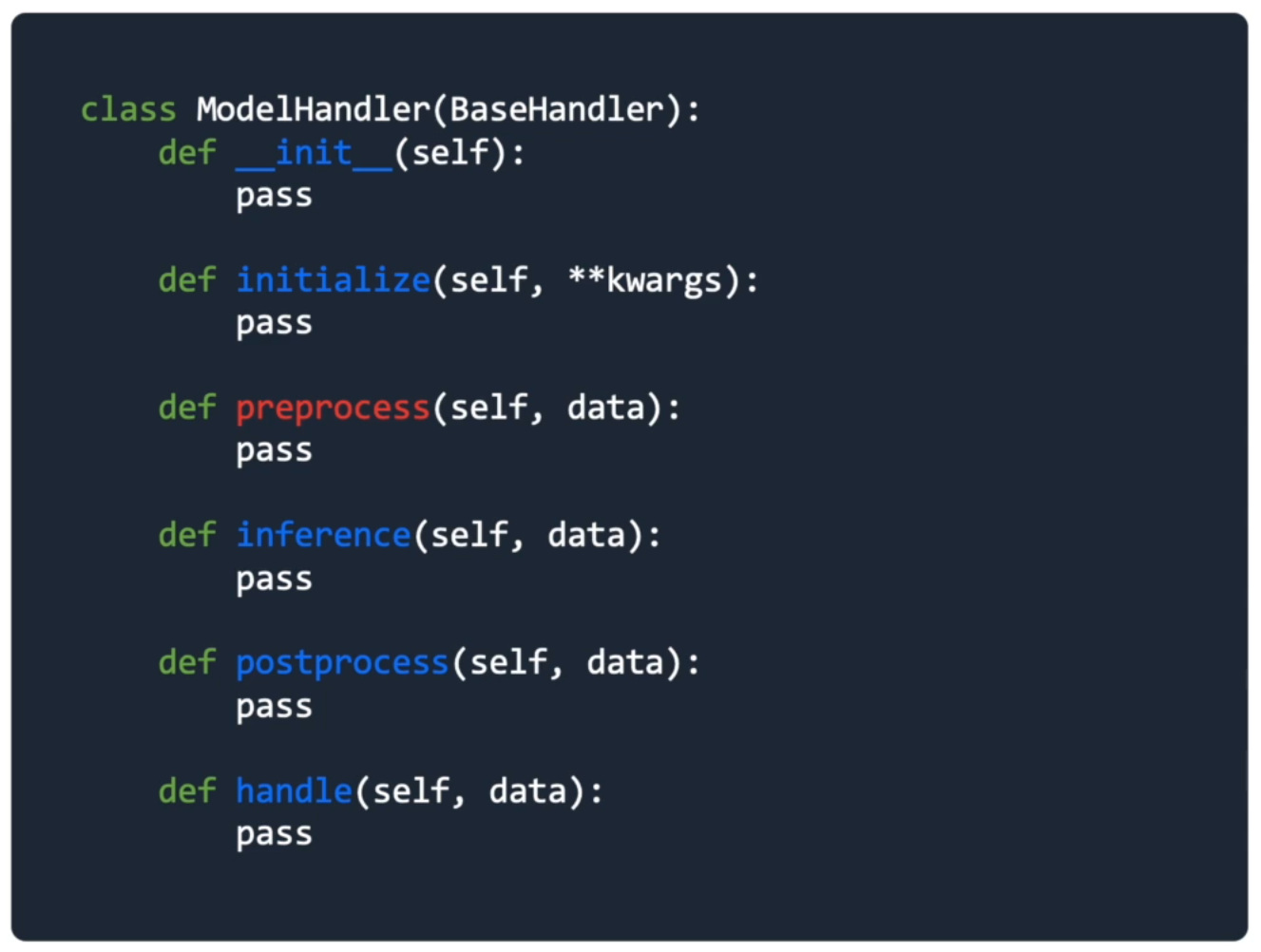
def preprocess(self, data):
# clearnsing raw text
model_input = self._clean_text(text)
# vectorize cleaned text
model_input = self.vectorize.transform(model_input)
return model_inputInference
- 입력된 값에 대한 예측 / 추론
- 각 모델의 predict 방식으로 예측 확률분포 값 반환
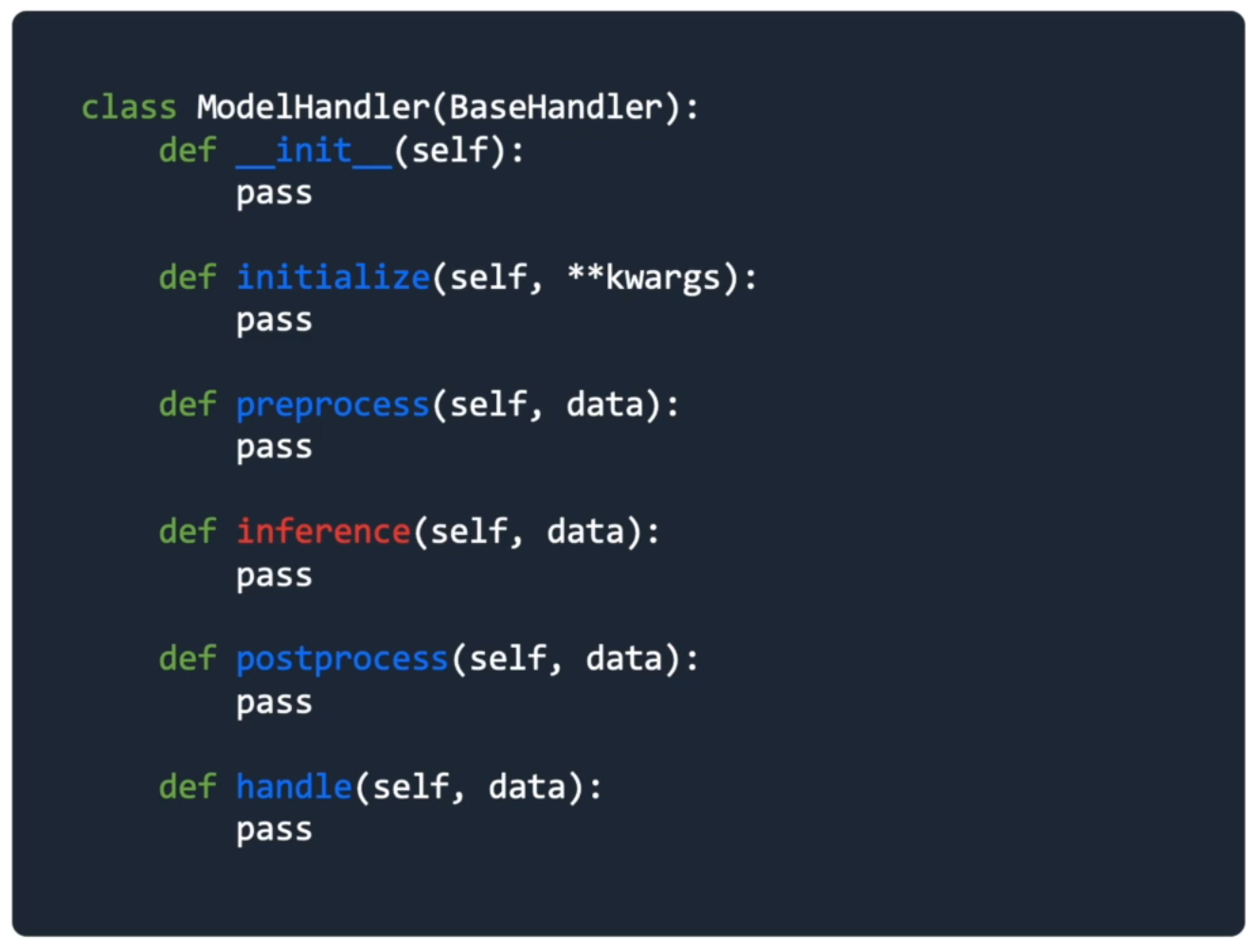
def inference(self, model_input):
model_output = self.model.predict_proba(model_input)
return model_outputPostprocess
- 모델의 예측값을 response에 맞게 후처리 작업
- 예측된 결과에 대한 후처리 작업
- 보통 모델이 반환하는 건 확률분포와 같은 값이기 때문에 response에서 받아야 하는 정보로 처리하는 역할을 많이 함
def postprocess(self, data):
# process predictions to predicted label and output format
predicted_probabilities = model_output.max(axis = 1)
predicted_ids = model_output.argmax(axis = 1)
predicted_labels = [self.id2label[id_] for id_ in predicted_ids]
return predicted_labels, predicted_probabilitiesTesting ML model handler



AI Tensorflow Python