해당 C언어 시리즈는 처음 코딩을 접하는 사람들이 쉽게 이해할 수 있도록 작성되었습니다.
자료형
자료형은 메모리(RAM)을 몇 바이트 단위로 사용할 건지 컴퓨터에게 알려주는 역할을 합니다.
위 말을 보면 벌써부터 모르는 용어가 2개나 등장합니다. 메모리, 바이트. 처음 듣지만 그리 어려운 개념은 아니니 긴장 푸셔도 됩니다.
메모리(Memory)
메모리는 단순히 어떠한 데이터를 저장할 수 있는 공간이라고 보면 됩니다.
여기서 데이터라 함은 우리가 일상에서 사용하는 문자와 숫자, 특수기호 등을 의미합니다.
바이트(Byte)
바이트(Byte)는 컴퓨터가 처리하는 정보(데이터)의 단위입니다.
오늘 중점적으로 볼 내용은 바이트의 정의가 아니라 1 바이트가 표현할 수 있는 정보의 양이 얼마나 되는가입니다.
비트(Bit)
바이트(Byte)를 이해하기 전에 우리는 비트(Bit)라는 개념에 대해 알아야 합니다.
1 비트는 이진수 0 또는 1을 나타내는 단위입니다. 여기서 중요한 건 0 또는 1이라는 점입니다. 0 또는 1이기 때문에 1 비트가 표현할 수 있는 정보는 2가지입니다.
1 Byte가 표현할 수 있는 정보의 양

1 바이트는 총 8개의 비트로 이루어져 있습니다.
그렇다면 1 바이트는 몇 가지의 정보를 표현할 수 있을까요?
정답은 2^8 = 256가지입니다.
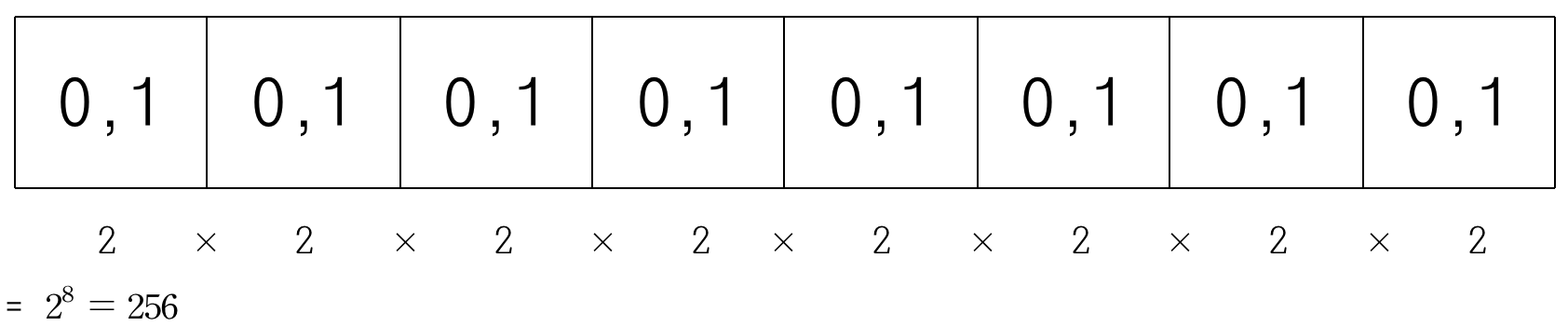
각각의 비트는 2가지의 정보를 표현할 수 있고, 1 바이트라는 그룹 안에서 동시에 어떠한 상태(0 또는 1)를 가지기 때문에 곱의 법칙에 의해 2의 8제곱, 256가지라는 답이 나오는 겁니다.
방금 1 바이트는 2의 8제곱이라는 식을 통해 256가지의 정보를 표현할 수 있다고 배웠습니다. 그러면 2 바이트와 4 바이트는 몇 가지의 정보를 표현할 수 있을까요?
1 Byte = 8 Bit
2 바이트 = 16 비트 = 2^16 = 65,536가지
4 바이트 = 32 비트 = 2^32 = 4,294,967,296가지
의 정보를 표현할 수 있다는 사실을 알 수 있습니다.
여러분은 이제 오늘의 핵심 내용 중 하나인 표현할 수 있는 정보의 양 계산 방법을 터득했습니다.
자료형의 종류
이제부터 자료형에 대해 본격적으로 살펴보겠습니다.
자료형은 크게 정수형과 실수형으로 구분됩니다.
정수형은 음의 정수, 0, 양의 정수를 표현할 수 있습니다.
실수형은 소수를 표현할 수 있습니다.
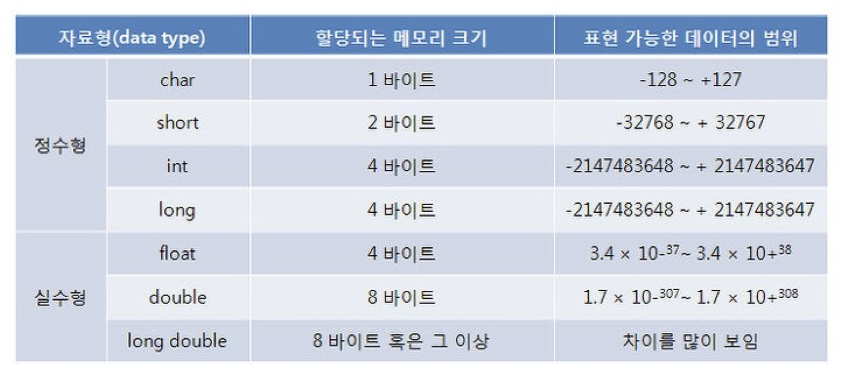
정수형 자료형의 종류는 크게 char, short, int가 있습니다.
(int와 long은 같다고 봐도 무관합니다)
정수형 자료형
정수형 자료형의 표현 가능한 데이터의 범위
1 바이트 자료형 char
char는 1 바이트의 크기를 가지고 있고 위에서 배운 대로 총 256가지의 정보를 표현할 수 있습니다. 그런데 위의 표를 보면 표현 가능한 데이터의 범위에 -128 ~ +127이라고 적혀있는 걸 볼 수 있습니다. 컴퓨터는 음의 정수부터 양의 정수까지의 값을 모두 표현할 수 있어야 되기 때문입니다.
256을 둘로 나누면 128입니다.
128개는 음의 정수를 표현하기 위해, 나머지 128개는 0을 포함한 양의 정수를 표현하기 위해 사용합니다. 때문에 1 바이트 자료형 char의 데이터의 표현 범위가 -128 ~ 127이라는 계산이 나오게 되는 거죠.
2 바이트 자료형 short
2 바이트 자료형 short와 4바이트 자료형 int 역시 마찬가지입니다.
short는 65,536가지의 정보를 표현할 수 있고 32,768개씩 둘로 나눠 음수 정수, 0, 양의 정수를 표현하여 -32,768 ~ 32,767이라는 데이터 표현 범위가 나옵니다.
4 바이트 자료형 int
4바이트의 크기를 갖는 자료형 int는 4,294,967,296가지의 정보를 표현할 수 있습니다. char, short와 동일하게 계산하면 -2,147,483,648 ~ 2,147,483,647이라는 데이터 표현 범위가 나옵니다.
사실 정확하게 알 필요 없다
저 같은 전공 변태들이나 저 범위들을 다 외우고 다니지 외울 필요 없습니다.
데이터 표현 범위 계산 방법과 아래 대강 나타낸 자료형별 범위만 기억해 주시면 됩니다.
char는 간단하니까 -128 ~ 127이라고 외워주시고,
short는 -3만 ~ 3만,
int는 -21억 ~ 21억
이라고 알고 계셔도 됩니다.
unsigned ___
컴퓨터에게 음의 정수와 0, 양의 정수로 구분하지 않고 0과 양의 정수만을 표현하도록 지시할 수도 있습니다. 자료형의 이름 앞에 unsigned를 붙이면 됩니다. 예를 들면 unsigned char와 같이 말이죠.
unsigned char는 256가지의 표현을 0과 양의 정수만으로 나누기 때문에 0 ~ 255라는 데이터 표현 범위를 갖습니다.
unsigned short와 unsigned int 역시 마찬가지로 0과 양의 정수만을 표현해 각각 0 ~ 65,535, 0 ~ 4,294,967,296의 데이터 표현 범위를 갖습니다.
signed ___
unsigned와 반대로 signed도 존재합니다.
signed는 signed char와 같이 명시하지 않고 자료형의 이름만 있을 경우 자동으로 처리되어 음의 정수 ~ 양의 정수의 데이터 표현 범위를 갖게 됩니다.
생략이 가능하다는 의미입니다.
char는 왜 char일까?
아스키 코드(ASCII CODE)는 0 ~ 127의 숫자를 문자와 매칭해 표현합니다. 1 바이트는 기본적으로 -128 ~ 127의 표현 범위를 가지는데 표현 범위를 봤을 때 1 바이트와 일치합니다. 문자를 저장하기에 가장 적합한 크기가 1 바이트라는 것을 강조하기 위해 1 바이트 자료형의 이름을 char(character)라고 정했습니다.
실수형 자료형
실수형 자료형은 크게 float과 double이 있습니다.
실수형 자료형은 정수형 자료형과 다르게 부동 소수점 방식을 따르기 때문에 데이터 표현 범위의 계산 방법이 다릅니다. 이는 지금 단계에서 알지 않아도 되는 내용이기 때문에 넘어가겠습니다.
float과 double은 정수형 자료형과 달리 엄청나게 광범위한 데이터 표현 범위를 가집니다. 따라서 따로 알아둘 필요는 없습니다.
float과 double의 차이점과
double의 이름이 double인 이유
그러면 float과 double은 어떻게 다를까요?
double이 float보다 크기가 2배 큰 것도 있지만, 정밀도(오차 없이 표현) 역시 2배 더 높습니다.
float은 소수점 아래 7번째 자리까지 정밀도가 보장이 되고,
double은 소수점 아래 15번째 자리까지 정밀도가 보장이 됩니다.
double의 이름이 double인 이유도 정밀도가 2배이기 때문이죠.
