
💡 scikit-learn, 사이킷런
파이썬용 머신러닝 라이브러리.
딥러닝 모델을 tensorflow, keras, pytorch 등 이용해서 생성할 수 있는 것처럼 머신러닝 모델은 주로 사이킷런 라이브러리를 통해 만들어낼 수 있다.
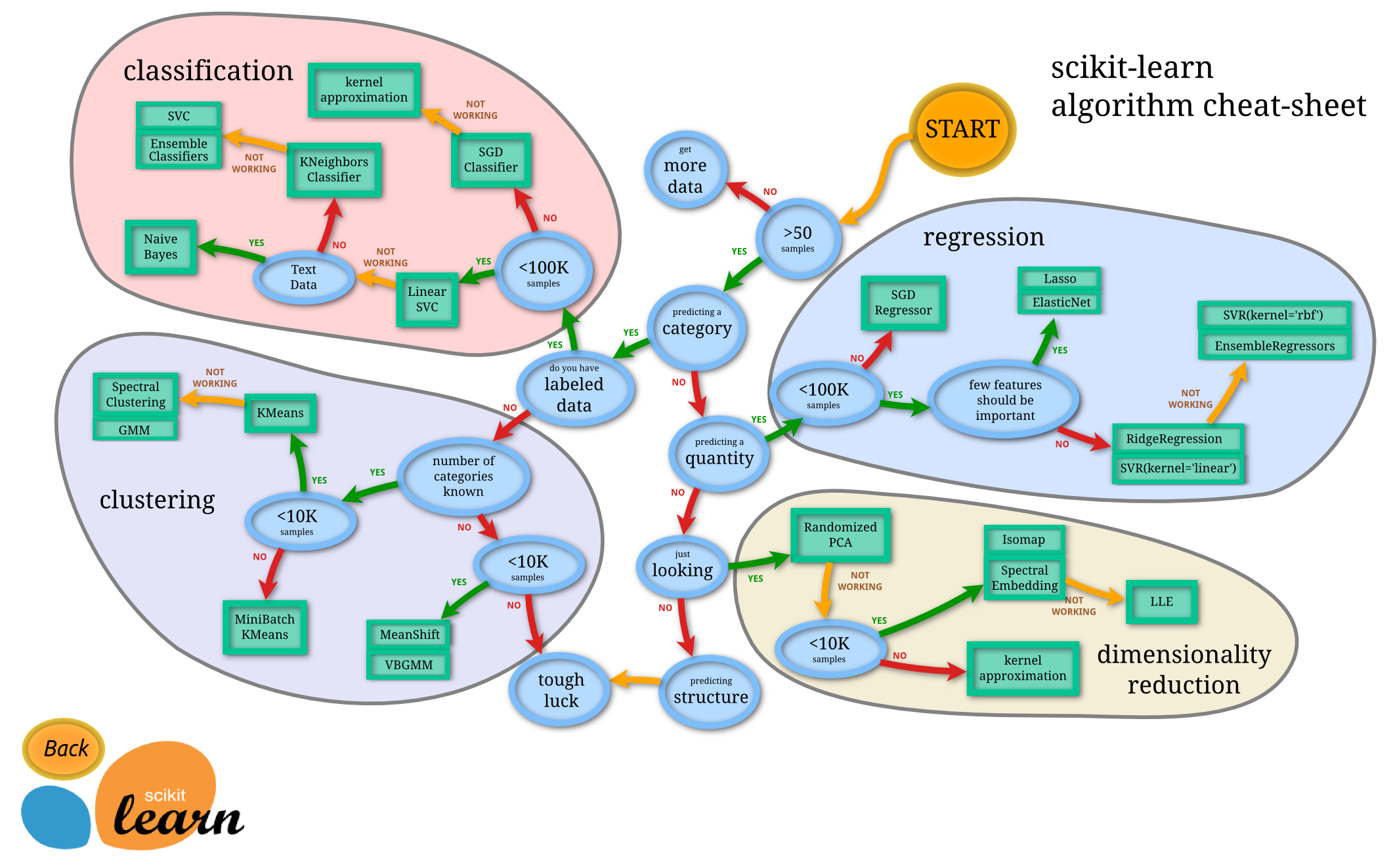
- 지도 학습을 위한 모듈
Naive BAyes, Decision Trees, Support Vector Machines, 등- 비지도 학습을 위한 모듈
Clustering, Gaussian mixture models 등- 모델 선택 및 평가를 위한 모듈
교차 검증(Cross validation), 모델 평가(Model evaluation), 모델의 지속성을 위해 모델 저장 및 불러오기 기능 등 제공- 데이터 변환 및 데이터를 불러오기 위한 모듈
파이프라인(Pipeline), 특징 추출(Feature extraction), 데이터 전처리(preprocessing data), 차원 축소(dimensionality reduction) 등 기능 제공- 계산 성능 향상을 위한 모듈
자체적으로 포함하고 있는 데이터셋: 당뇨병 데이터, 아이리스 데이터, 유방암 데이터 등
📌 사이킷런을 이용한 데이터 분리
from sklearn.model_selection import train_test_split
train_input, test_input, train_label, test_label = train_test_split(iris_dataset['data'], iris_dataset['target'], test_size=0.25, random_state=42)random_state는 random seed값이라고 생각하면 된다.
학습 데이터, 평가 데이터, 검증 데이터로 총 3 개의 데이터를 사용한다.
학습 데이터를 사용해서 모델을 학습시키고 검증 데이터를 사용해 모델 검증을 진행한다. 그결과로 모델의 하이퍼파라미터를 수정하는데, 이 과정을 반복적으로 진행하여 모델이 최종적으로 나오고, 이 모델에 평가 데이터를 넣어 평가한다.
📌 사이킷런을 이용한 지도학습
지도 학습이란 각 데이터에 대해 정답 레이블 값이 있는 경우로, 각 데이터의 정답을 예측할 수 있게 학습시킨다.
즉, 모델이 예측하는 결과를 각 데이터의 정답과 비교해서 모델을 반복적으로 학습시킨다.
🪵 k-최근접 이웃 분류기
예측하고자 하는 데이터에 대해 가장 가까운 거리에 있는 데이터의 라벨과 같다고 예측하는 방법이다.
💡데이터에 대한 사전 지식이 없는 경우의 분류에 많이 사용한다.
k: 참고할 가까운 몇 개의 데이터를 참고할 것인가
예를 들어 k=1일 경우, 가장 가까운 데이터의 라벨값이 Class1이면 Class1으로 예측한다.
특징
- 데이터에 대한 가정이 없어 단순함
- 다목적 분류와 회귀에 좋음
- 높은 메모리 요구
- k값이 커지면 계산이 느려질 수 있음
- 관련 없는 기능의 데이터 규모에 민감
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=1, p=2, weights='uniform')
knn.fit(train_input, train_label)📌 사이킷런을 이용한 비지도학습
데이터에 대한 정답, 즉 라벨을 사용하지 않고 만들 수 있는 모델이다.
💡데이터에 대한 정답이 없는 경우에 적용하기 적합한 모델이다.
🪵 k-means Clustring
군집화(clustering)이란 데이터를 특성에 따라 여러 집단으로 나누는 방법이다.
가장 간단하고 널리 사용되는 군집화 방법으로, 💡데이터 안에서 대표하는 군집의 중심을 찾는 알고리즘이다.
우선 k개만큼의 중심을 임의로 설정.
모든 데이터를 가장 가까운 중심에 할당.(같은 중심에 할당된 데이터드를 하나의 군집으로 판단)
각 군집 내 데이터를 가지고 군집의 중심을 새로 구해서 업데이트.
또 다시 가까운 중심에 할당, 이후 계속 반복.
데이터에 변화가 없을 때까지 반복한다.
from sklearn.cluster import KMeans
k_means=KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=3, n_init=10, random_state=None, tol=0.0001, verbose=0)
# n_jobs, precompute_distances 없어짐# 학습하기
k_means.fit(train_input)# 라벨 분포 확인하기
print("0 Cluster:", train_label[k_means.labels_==0])
print("1 Cluster:", train_label[k_means.labels_==1])
print("2 Cluster:", train_label[k_means.labels_==2])0 Cluster: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
1 Cluster: [2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 1 2 2 2 2]
2 Cluster: [2 1 1 1 2 1 1 1 1 1 2 1 1 1 2 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1 1 1 1 1
1 1 1 1 1 1 2 2 1 2 1]즉, 0 번째 클러스터에는 0 라벨이,
1 번째 클러스터에는 2 라벨이,
2 번째 클러스터에는 1 라벨이 분포돼 있음을 확인할 수 있다.
predict_cluster=k_means.predict(test_input)
np_arr = np.array(predict_cluster)
np_arr[np_arr==1],np_arr[np_arr==2]=3,4
np_arr[np_arr==3]=2
np_arr[np_arr==4]=1
predict_label=np_arr.tolist()
print("test accuracy: {:.2f}".format(np.mean(predict_label==test_label)))출처: 텐서플로2와 머신러닝으로 시작하는 자연어 처리
