NLP(자연어 처리)
1.Stemming(어간 추출) vs Lemmatization(표제어 추출) in 자연어 처리

토큰화는 NLP 처리 파이프라인의 첫 번째 단계인 경우가 많다.영어의 경우 NLTK(Natural Language Toolkit)와 Spacy가 토크나이징에 많이 쓰이는 대표적인 라이브러리로, 영어 텍스트 전처리 및 분석을 위한 도구로 많이 사용된다.모두 단어로 구분돼
2.논문 읽기 - "Based on billions of words on the internet, people = men"
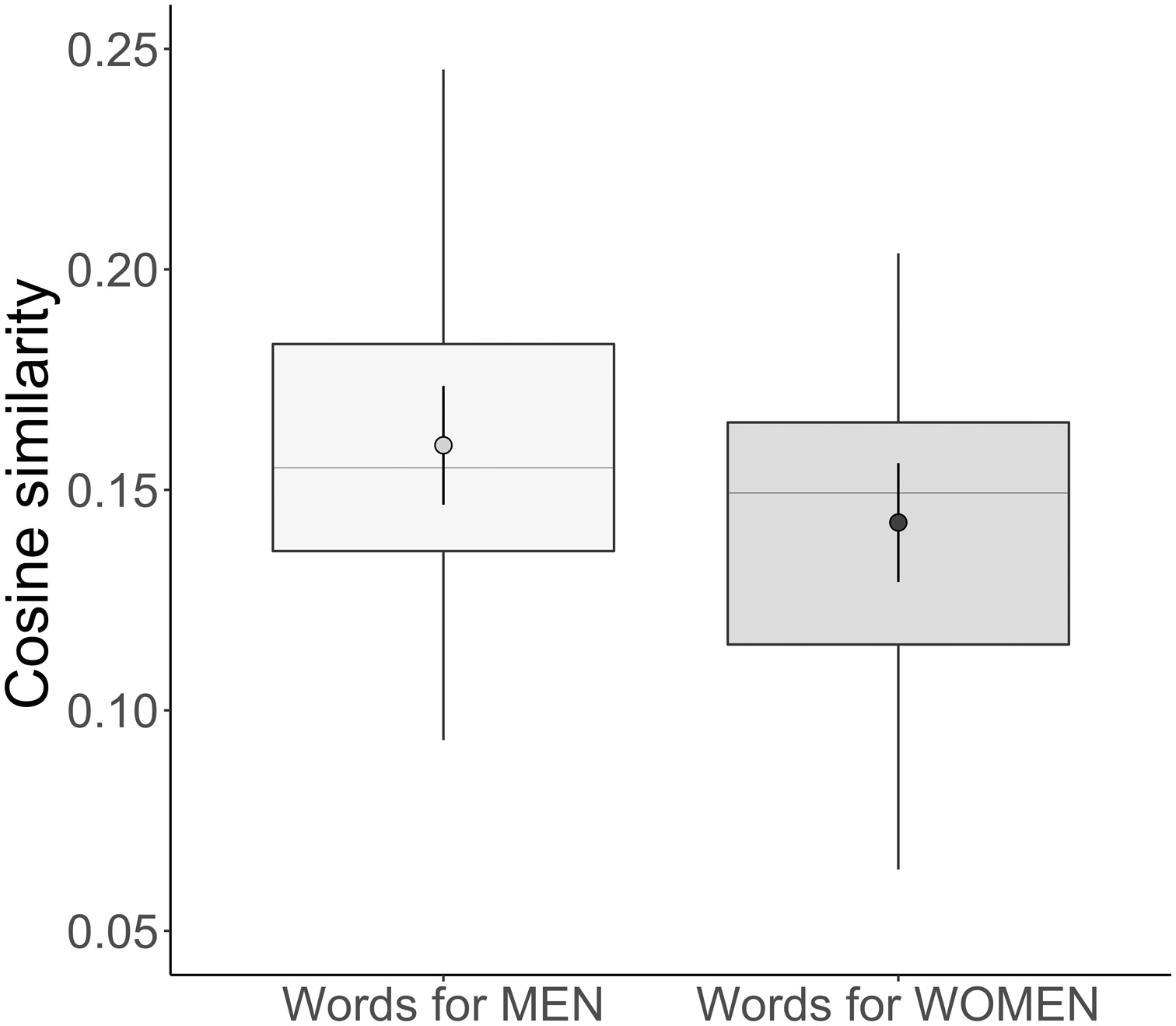
진행하고 있는 프로젝트에서 특정 키워드(keyword)가 입력으로 들어오는 문장에 포함되어 있는지 확인하는 알고리즘을 구성해봐야 한다.근데 예를 들어 keyword로 "man"이 주어졌을 때, 문장에 "men"이 있다면 포함되어 있다고 봐야하지만, 단순 일치로 알고리즘
3.자연어 처리 개요(1) - 단어 표현(Word Representation)
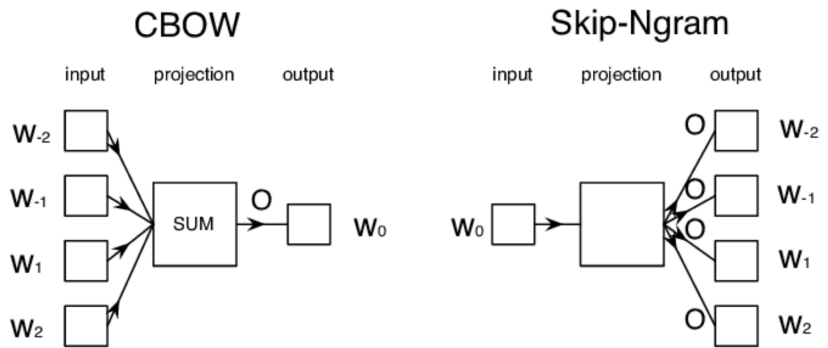
크게 💡텍스트 분류, 텍스트 유사도, 텍스트 생성, 기계 독해💡 - 4가지 문제가 있다.단어 표현은 모든 자연어 처리 문제의 기본 바탕이 되는 개념이다.자연어를 어떻게 표현할지 정하는 것이 문제를 해결하기 위한 출발점이다.데이터를 이해하는 것이 매우 중요한데, 데이
4.자연어 처리 개요(2) - 자연어 처리 대표 문제
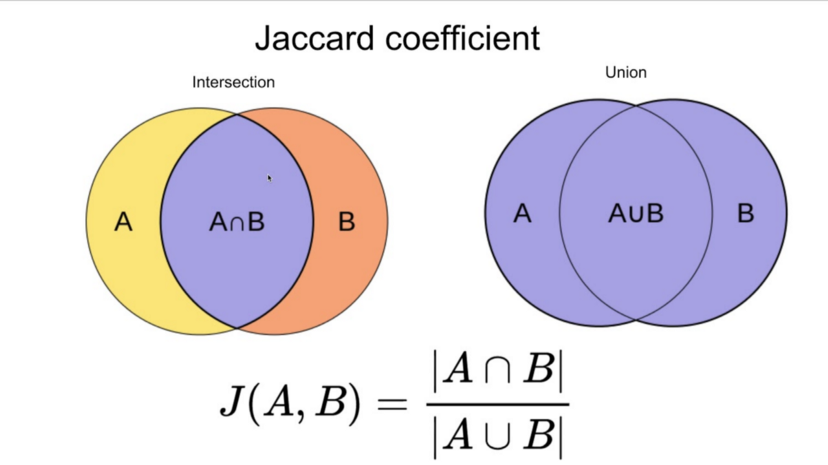
2가지 범주에 대해 구분하는 문제를 이진 분류(Binary Classification) 문제라 하고, 3개 이상의 범주에 대해 분류하는 문제를 통틀어 다중 범주 분류(Multi class Classification)라고 한다.자동으로 일반 메일과 스팸 메일을 분류하는
5.자연어 처리 개요(3) - 데이터 이해하기
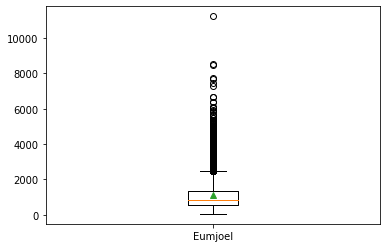
탐색적 데이터 분석(EDA:Exploratory Data Analysis), 데이터의 여러 패턴이나 잠재적인 문제점을 발견하는 등 데이터 이해를 하는 과정이다. 문제를 해결하기 위해서는 모델과 데이터의 조합, 궁합이 중요하다!! 💡탐색적 데이터 분석 과정 데이터에
6.텍스트 분류 - 영어 텍스트 분류(1)

인터넷 영화 데이터베이스(IMDB)에서 나온 영화 평점 데이터를 활용한 캐글 문제다. 영화 리뷰 텍스트, 평점에 따른 감정 값(긍정/부정)으로 구성돼 있따.데이터 불러오기 + 데이터 전처리데이터 분석하기알고리즘 모델링데이터 분석은 다음과 같은 순서로 진행한다.데이터 크
7.텍스트 분류하기 - 영어 텍스트 분류(2)
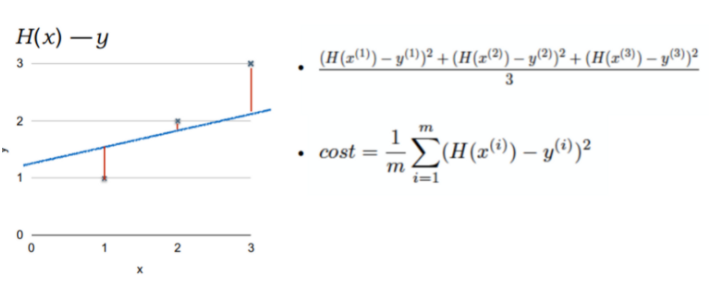
선형 회귀 모델, Random Forest 모델, 딥러닝 모델 - CNN, RNN을 살펴본다.연속적인 데이터에 대해서 변수들 사이의 모델을 구한 뒤, 특정 입력값에 대한 결과값을 예측하는 것.선형 회귀 모델은 종속변수와 독립변수 간의 상관관계를 모델링하는 방법이다.하나
8.텍스트 분류하기 - 영어 텍스트 분류(3)
머신러닝 모델 중 하나인 랜덤 포레스트 모델은 여러 개의 의사결정 트리의 결과값을 평균낸 것을 결과로 사용한다.분류 또는 회귀를 할 수 있다.🔎의사결정 트리에 대해 먼저 알아보자.의사결정 트리란 자료구조 중 하나인 트리 구조와 같은 형태로 이뤄진 알고리즘이다. 각 트
9.텍스트 분류하기 - 영어 텍스트 분류(3)
머신러닝 모델 중 하나인 랜덤 포레스트 모델은 여러 개의 의사결정 트리의 결과값을 평균낸 것을 결과로 사용한다.분류 또는 회귀를 할 수 있다.🔎의사결정 트리에 대해 먼저 알아보자.의사결정 트리란 자료구조 중 하나인 트리 구조와 같은 형태로 이뤄진 알고리즘이다. 각 트
10.텍스트 분류하기 - 한국어 토큰화(Tokenization)
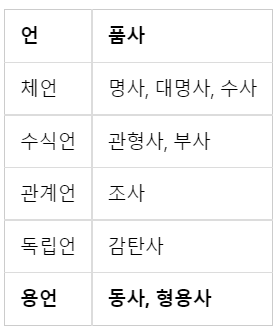
한국어의 경우 띄어쓰기 단위가 되는 단위를 '어절'이라고 하는데 어절 토큰화는 한국어 NLP 데이터에 적합한 처리가 아니다.그 이유는 한국어가 교착어, 즉 조사, 어미 등이 붙는 언어이기 때문이다.서로 다른 조사를 분리해줄 필요가 있다.조사를 분리하기 위해 영어처럼 띄
11.Natural Language Processing: NLTK Vs SpaCy 차이점

Performance, 성능 및 속도 NLTK는 spaCy보다 While NLTK returns results much slower than spaCy (spaCy is a memory hog!), spaCy’s performance is attributed to
12.딥러닝 프레임워크, Tensorflow로 모델 구축하기

구글에서 2015년에 오픈소스로 발표한 머신러닝 라이브러리이다.Python을 기반으로 한 라이브러리로, 상용 서비스까지 고려해서 최적화되어 있다. "Tensorflow"에서 Tensor(텐서)는 N차원 매트릭스를 의미하고,Tensor을 flow한다는 것은 Data fl
13.딥러닝 프레임워크, Tensorflow로 모델 학습하기

Tensorflow 2.0 공식 가이드에서 권장하는 방법은 아래 두 가지이다.keras 모델의 내장 API를 활용(model.fit(), model.evaluate(), model.predict())학습, 검증, 예측 등 모든 과정을 GradientTape 객체를 활용
14.scikit-learn, 사이킷런 머신러닝 라이브러리 - 지도학습 및 비지도 학습 모델

파이썬용 머신러닝 라이브러리.딥러닝 모델을 tensorflow, keras, pytorch 등 이용해서 생성할 수 있는 것처럼 머신러닝 모델은 주로 사이킷런 라이브러리를 통해 만들어낼 수 있다.지도 학습을 위한 모듈Naive BAyes, Decision Trees, S
15.scikit-learn, 사이킷런 머신러닝 라이브러리 - 특징 추출

scikit-learn 모듈 중 특징 추출 모듈에 대해 알아보자.자연어 처리에서 특징 추출이란, 👉텍스트 데이터에서 단어나 문장들을 어떤 특징 값으로 바꿔주는 것을 의미한다.즉, 기존의 문자를 모델에 데이터로서 적용할 수 있도록 📌수치화하는 것이다.사이킷런을 사용해