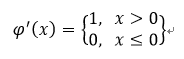링크
- https://www.tensorflow.org/datasets/catalog/overview : https://www.tensorflow.org/datasets/catalog/overview
- https://www.tensorflow.org/datasets/catalog/cats_vs_dogs : https://www.tensorflow.org/datasets/catalog/cats_vs_dogs
- 리스트에 map 함수 적용하기 : https://dojang.io/mod/page/view.php?id=2286
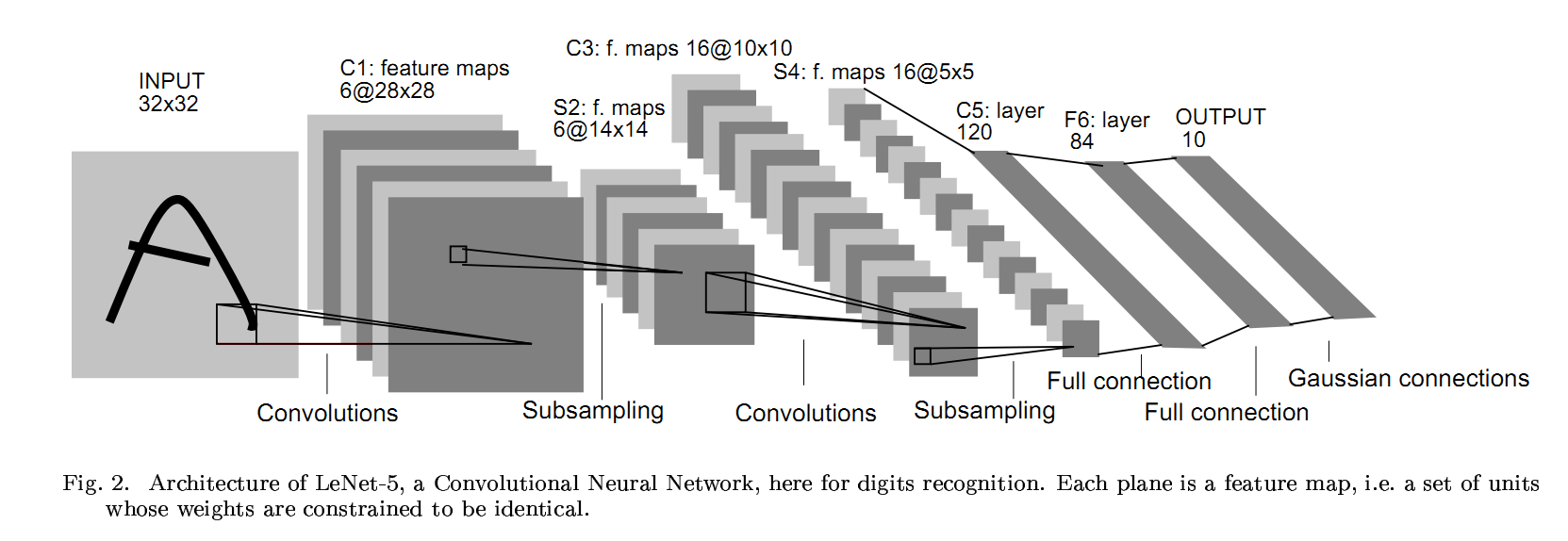
- Gradient-Based Learning Applied to Document Recognition: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
- 분류성능평가지표: https://sumniya.tistory.com/26
- ILSVRC 대회 (이미지넷 이미지 인식 대회) 역대 우승 알고리즘들: https://bskyvision.com/425
- CNN-Imagenet에 쓰인 주요 모델: https://www.sallys.space/blog/2018/01/26/cnn-imagenet/
- CNN 성능은 어떻게 평가하게 되나요?: https://89douner.tistory.com/59
- 텐서플로우 튜토리얼 - VGG16: https://www.tensorflow.org/api_docs/python/tf/keras/applications/vgg16/VGG16
- VGG16 – Convolutional Network for Classification and Detection: https://neurohive.io/en/popular-networks/vgg16/
- Global Average Pooling: https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/global-average-pooling-2d
- 활성화 함수(activation function)을 사용하는 이유: https://ganghee-lee.tistory.com/30
- [Deep Learning-딥러닝]Activation Function-활성화 함수(Sigmoid, Hyperbolic Tangent, Softmax, ReLu): https://ynebula.tistory.com/42
- https://www.tensorflow.org/datasets/catalog/tf_flowers
- Optimizer 바꾸기: https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
- 데이터셋의 기본 형태: (image, label) ex) ((None, None, 3),())
- 앞의 (None, None, 3): image shape
- 뒤의 (): label shape
- 이미지는 (height, width, channel)로 3차원 데이터임.
- height, width가 None인 이유: 모든 이미지의 크기가 전부 다르기 때문. 정해져있지 않은 사이즈라는 말.
- 채널: 컬러는 3, 흑백은 1, 컬러에 투명도 포함하면 4.
(3) 데이터 전처리
- take(): 인수로 받은 개수만큼의 데이터를 추출하여 새로운 데이터셋 인스턴스를 생성
- format_example(): 이미지를 같은 포맷으로 통일.
- 타입 캐스팅(Type casting): 형변환이라고도 함. 다른 데이터 타입으로 바꿔줌. ex) 정수형을 실수형으로 바꾸기 위해 float()를 사용.
- map(): 형변환. ex) map(int, a) : a라는 객체(예시에서는 리스트)의 형을 정수로 바꿔 반환한다.
- Transfer Learning|학습된 모델을 새로운 프로젝트에 적용하기: https://jeinalog.tistory.com/13
(4) 모델 만들기
- model: 모델 그 자체를 구축하기 위한 함수들을 포함함.
- layers: 레이어. 층.
- Sequential: 연속적인 모델을 쌓기 위한 함수.
- Summary(): 모델의 전체 구조를 보여줌.
(None, 160, 160, 16) 에서
- 첫 번째 차원: 데이터의 개수. None은 배치 사이즈에 따라 모델에 다른 수의 입력이 들어올 수 잇음.
- 6개의 레이어를 지나며 height, width는 점점 작아지고 channel은 점점 커짐. flatten 계층을 만나 25600(20x20x64)라는 하나의 숫자로 shape이 줄어듬.
(5) 모델 학습시키기
- compile을 하기 위해서는 optimizer, loss, metrics가 필요함.
- optimizer: 학습을 어떤 방식으로 시킬 것인지 결정. 최적화 함수.
- loss: 모델이 학습해 나가야 하는 방향을 결정. ex) 고양이(Label = 0)일 경우 [1,0]에 가깝게, 강아지(Label = 1)일 경우 [0,1]에 가깝게.
- metrics: 모델의 성능을 평가
- 예측에서의 loss: 손실. 모델이 얼마나 틀렸는지. 낮을수록 좋다.
- 예측에서의 accuracy: 몇 퍼센트의 정확도를 보이는가.
(6) 학습결과 확인
- 훈련 후 나온 accuracy: 훈련 데이터셋에 대한 정확도. 학습하고 있는 데이터에 대한 정확도.
- val_accuracy: 검증 데이터셋에 대한 정확도. 학습단계에서 보지 않은 데이터에 대한 정확도.
- model_predict(): 모델의 예측결과를 확인한다.
(8) 가져다쓰는 멍냥 분류기
- ILSVRC: Imagenet Large Scale Visual Recognition Challenge
- 2017년 이후 대회에서 활약하는 모델들의 성능이 사실상 사람을 뛰어 넘었다고 판단되었기 때문에 종료되었다.
- 전이학습: 밑바닥부터 모델을 쌓아올리는 대신에 이미 학습되어 있는 패턴들을 활용해서 적용시킴.
- CNN은 convolutional base(feature extraction)와 Classifier, 두 가지 파트로 구성되어 있다.
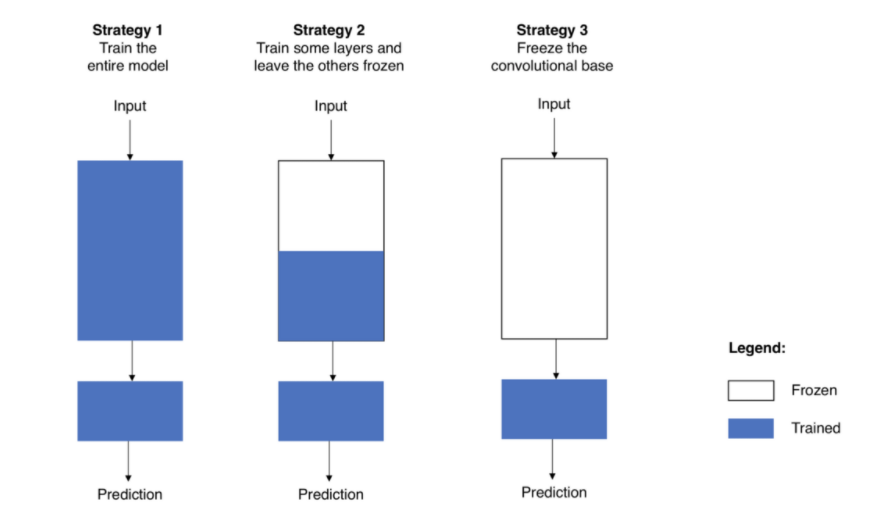
- 전이 학습 fine-tuning 3가지 전략
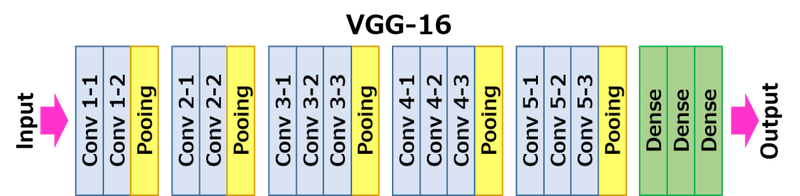
- VGG 16 모델 구조
(10) 모델 마지막 부분만 내 입맛대로 재구성하기
- Fully connected layer
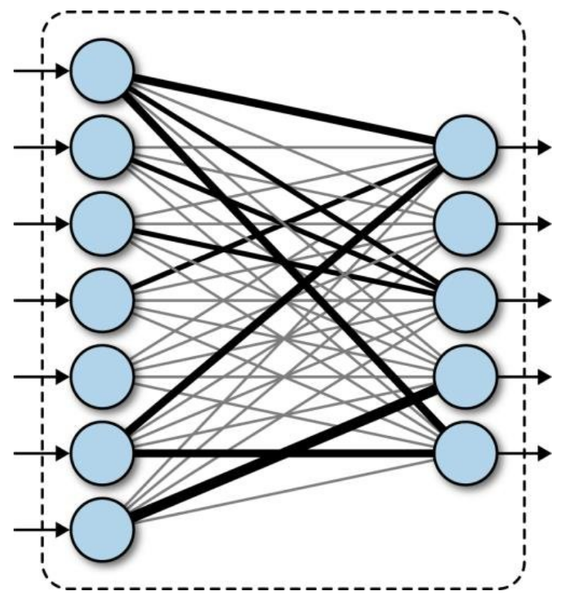
- Fully connected layer에 입력될 수 있는 벡터는 반드시 1차원이어야 함.
- VGG16 출력 벡터는 3차원이므로, classifier 구성 전 1차원으로 변환해주어야 한다.
- Global Average Pooling: 3차원 벡터가 있을 때, 겹겹이 쌓여있는 2차원 배열의 평균을 구한 후 하나의 값으로 축소하는 기법.
- activation: 활성화 함수. 입력값을 non-linear 방식의 출력값으로 얻기 위해 사용.
- Sigmoid function
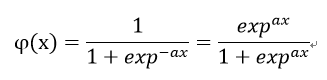
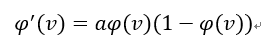
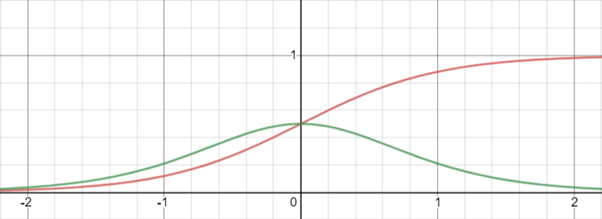
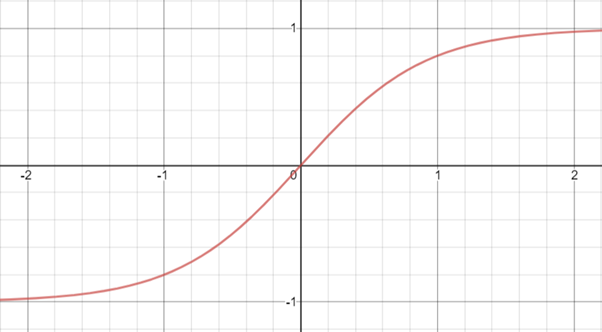
- Hyperbolic tangent function
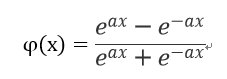
- Softmax function: 자신의 가중 합 뿐만 아니라, 다른 출력 노드들의 가중 합도 고려.
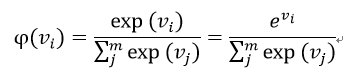
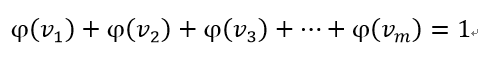
- Vi: i번째 출력 노드의 가중합
- m: 출력 노드의 개수
- softmax 출력의 각 원소는 0이상 1이하의 실수. 노드의 출력을 모두 합하면 항상 1이다.
- 소프트맥스는 모든 출력 값의 상대적인 크기를 고려한 값을 출력하기 때문에, 다범주 분류 신경망에 적합함.
- 소프트맥스 함수는 두 개의 주요 단계로 이루어짐.
- 1) 이미지가 어떤 레이블에 속하는지 근거(evidence)를 계산
- 2) 근거들을 각 레이블에 대한 확률로 변환.
- 벡터의 각 원소를 정규화 하기 위해 소프트맥스 함수는 입력값을 모두 지수값으로 바꾼다. 이렇게 하면 가중치를 더 커지게 하는 효과를 얻는다.
- 또한 한 클래스의 근거가 작을 때 이 클래스의 확률도 더 낮아지게 된다.
- 가중치의 합이 1이 되도록 정규화하여 확률분포를 만들어준다.
- 예측이 잘 되면 1에 가까운 출력은 하나만 있고 다른 출력은 0에 가까워진다. 예측이 잘 안되면 여러 레이블이 비슷한 확률을 가진다.
- ReLu: Rectified Linear Unit
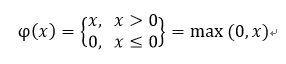
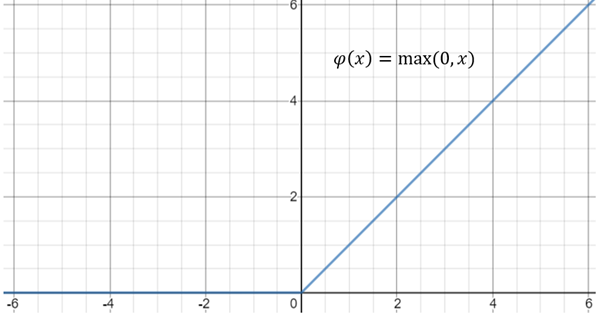
- Sigmoid 함수의 경우에는 입력값이 아무리 커도 신경망 노드의 출력은 1을 넘지 못함. ReLu는 이런 제한이 없음.
- ReLu 함수의 역전파 알고리즘을 구현하려면 이의 도함수가 필요.