EXP4. 작사가 인공지능
링크
- https://talktotransformer.com/
- 뛰어난 '문장 생성 인공지능'을 숨겨야만 하는 이유는?: https://decenter.kr/NewsView/1VFGQMBBXZ/GZ02
- 파이썬 프로그래밍 시퀀스 자료형: https://kukuta.tistory.com/310
- Tensor란 무엇인가?: https://rekt77.tistory.com/102
- https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer
- https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/sequence/pad_sequences
- https://www.tensorflow.org/api_docs/python/tf/data/Dataset
- https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
- https://www.tensorflow.org/api_docs/python/tf/keras/losses
- I 다음 am을 쓰면 반 이상 맞는다
- Recursive neural network(RNN)
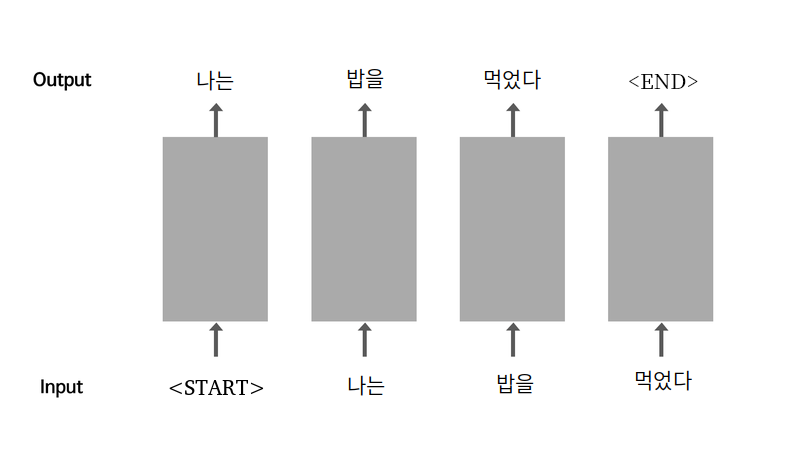
- '나는 밥을' 다음에 '먹었다'가 나올 확률: p(먹었다|나는, 밥을)이라고 하자.
- 이는 p(밥을|나는) 보다 높게 나온다.
- 어떤 문구 뒤에 다음 단어가 나올 확률이 높다는 것은 그 단어가 나오는 것이 보다 자연스럽다는 뜻이 된다.
- 언어 모델(Language Model): n-1개의 단어 시퀀스 W1, W2, ..., Wn-1가 주어졌을 때, n번째 단어 Wn으로 무엇이 올지를 예측하는 확률 모델
-파라미터 θ로 모델링하는 언어모델은 다음과 같이 표현할 수 있다.
P(Wn|W1, ... , Wn-1;θ)
- Recursive neural network(RNN)
- 데이터 다듬기(전처리)
- Tokenize(토큰화): 문장을 일정한 기준으로 쪼개는 것.
- 소스 문장(Source sentence): 모델의 입력이 되는 문장
- 타겟 문장(Target sentence): 정답역할을 하게될 모델의 출력 문장.
< 데이터셋을 생성하기 위해 거치는 과정> - 정규 표현식을 이용한 corpus 생성
- tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환.
- tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset 객체로 변환.
- 인공지능 학습
- 모델의 구조도
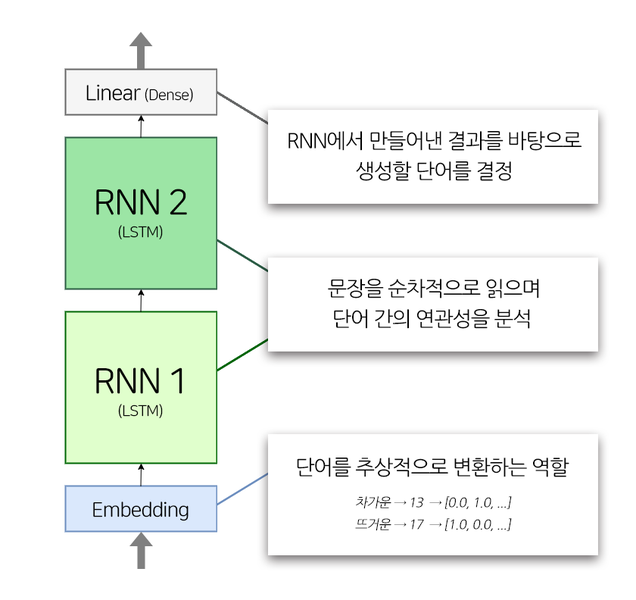
- 입력 텐서에는 단어 사전의 인덱스가 들어 있음. Embedding layer는 이 인덱스 값을 해당 인덱스 번째의 워드 벡터로 바꿔준다. 이 워드 벡터는 의미 벡터 공간에서 단어의 추상적 표현으로 사용된다.
- 예) 차갑다: [0.0 1.0], 뜨겁다 [1.0 0.0], 미지근하다: [0.5 0.5]
- 모델의 최종출력텐서 shape: 256, 20, 7001.
- 7001: Dense layer의 출력 차원 수. 7001개의 단어 중 어느 단어의 확률이 가장 높을지를 모델링해야 하기 때문.
- 256: 이전 스텝에서 지정한 배치 사이즈. dataset.take(1)을 통해 1개의 배치, 즉 256개의 문장 데이터를 가져옴.
- 20: LSTM은 자신에게 입력된 시퀀스의 길이만큼 동일한 길이의 시퀀스를 출력.
- tf.keras.layers.LSTM(hidden_size, return_sequences = True). 만약 return_sequences False였다면 LSTM 레이어는 1개의 벡터만 출력했을 것.
- 우리의 모델은 입력 데이터의 시퀀스 길이가 얼마인지는 모름. 입력받으면서 max_len: 20으로 맞춰져 있어 알게 됨.
- 모델의 구조도
- 평가하기

microCT_applications