링크
- [캐글] Pokemon with stats: https://www.kaggle.com/abcsds/pokemon
- 파이썬 차집합 함수(set difference): https://www.w3schools.com/python/ref_set_difference.asp
- 판다스 isna() 함수: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.isna.html
- pandas의 sum() 함수: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sum.html
- 파이썬 람다 문법: https://wikidocs.net/64
- pandas의 isalpha() 함수: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.isalpha.html
- 위키독스-정규표현식 시작하기: https://wikidocs.net/4308
- Counter: https://docs.python.org/3/library/collections.html#counter-objects
- pandas의 == 문법: https://pandas.pydata.org/docs/user_guide/basics.html#comparing-if-objects-are-equivalent
-
포켓몬, 그 데이터는 어디서 구할까
(1) 안녕, 포켓몬과 인사해!
- 탐색적 데이터 분석(Exploratory Data Analysis, EDA): 분류 문제를 풀기 위해 데이터를 밑바닥부터 샅샅이 뜯어보는 것
(2) 포켓몬, 그 데이터는 어디서 구할까
(3) 포켓몬 데이터 불러오기
- numpy, pandas: 1/2차원 형식의 표 데이터를 다루는 라이브러리
- seaborn, matplotlib: 데이터를 그래프 등으로 시각화. seaborn은 matplotlib의 상위 버전. -
전설의 포켓몬? 먼저 샅샅이 살펴보자
(1) 결측치와 전체 칼럼
(2) ID와 이름
(3) 포켓몬의 속성
- isna(): 데이터가 비어있는 NaN값의 개수 확인
ex) pokemon["Type 2"].isna().sum()
- countplot(): 데이터의 개수를 표시
ex) sns.countplot(data=ordinary, x="Type 1", order=types).set_xlabel('')
- sort_value: 내림차순
ex) pd.pivot_table(pokemon, index = "Type 1", values = "Legendary").sort_values(by = ["Legendary"], ascending = False)
(4) 모든 스탯의 총합
(5) 세부 스탯
(6) 세대 -
전설의 포켓몬과 일반 포켓몬, 그 차이는?
(1) 전설의 포켓몬의 Total 값
(2) 전설의 포켓몬의 이름 -
모델에 넣기 위해! 데이터 전처리하기
(1) 이름의 길이가 10 이상인가?
(2) 이름에 자주 쓰이는 토큰 추출
- 정규표현식: 문자열을 처리하는 방법의 하나. 특정한 조건을 만족하는 문자를 검색하거나 치환하는 등의 작업을 하고 싶을 때 간편하게 처리할 수 있게 해주는 도구.
- [A-Z]: A부터 Z까지의 대문자 중 한 가지로 시작.
- [a-z]: a-z까지의 소문자 중 한 가지가 그 뒤에 붙음
- * : 하나 이상인 패턴. 반복.
- Counter(): 어떤 문구가 얼마나 있는지 셈.
- str.contains(): Pandas에서 문자열 데이터셋에 특정 구문이 포함되어 있는지의 여부 파악.
- 적절한 방법을 통해서 문자열 데이터를 숫자나 부울 데이터로 변환해서 정보를 넣어주면 모델의 성능을 올리는 데에 도움을 줄 수 있다.
(3) Type 1&2! 범주형 데이터 전처리하기
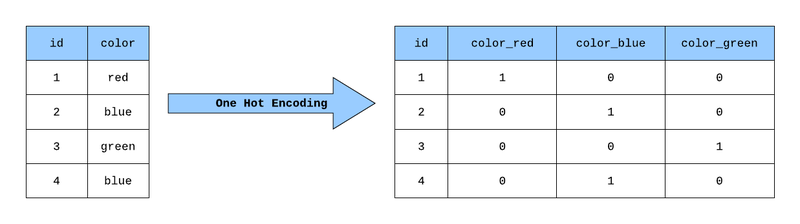
- 원-핫 인코딩: 주어진 카테고리 중 단 하나만 1(True), 나머지는 모두 0(False)로 나타나도록 인코딩 하는 방식.
- Type은 범주형 데이터.
- 범주형 데이터는 그대로 데이터를 처리하기 힘들다. 컴퓨터는 숫자를 예측하기 때문에 문자를 숫자로 바꾸어야 학습/예측이 가능하다
- 정수형 인코딩: Fire 0, Ice 1, Ground 2.... 숫자로 카운팅 되므로, 대소 관계가 있는 범주를 변형하는 데는 적합하지만 그 외에는 좋은 선택이 아님.
- 원-핫 인코딩: 모든 범주를 새로운 컬럼으로 만들고 해당 범주라면 True, 아니라면 False를 반환하게 하는 것. 컬럼이 너무 많아진다는 단점이 있으나 데이터 처리에는 적합함.
- -
가랏, 몬스터볼!
(1) 가장 기본 데이터로 만드는 베이스 라인
- 베이스라인 모델: 가장 기초적인 방법으로 만든 모델. 성능 하한선을 제공하여 새롭게 만들 모델이 맞는 방향으로 가고 있는지 확인할 수 있게 도와줌.
(2) 의사 결정 트리 모델 학습 시키기
- random_state(): 모델의 무작위성 제어. 어떤 값을 넣어도 상관없지만, 실험 단계에서는 무작위성에 의해 학습결과가 차이나는 것을 방지하기 위해 하나의 값으로 고정해서 실험하는 것이 좋음.
(3) 피처 엔지니어링 데이터로 학습시키면 얼마나 차이가 날까?
(4) 의사결정 트리 모델 다시 학습시키기
