GloVe
오늘은 단어 임베딩의 방법 중 하나인 GloVe에 대해 알아보고자 한다. GloVe는 2014년 스탠포드 대학에서 발표된 단어 임베딩 알고리즘으로, 당시 단어 유추, 유사도 테스트 등에서 SOTA모델을 달성했다.
1 Introduction
언어를 의미적 벡터 공간에 모델링할 때, 우리는 단어 각각을 실수 벡터에 할당해 표현한다. 이 벡터들은 정보검색, 문서분류, 개체명 인식, 구문 분석 등 다양한 분야에 사용될 수 있는데, 이러한 벡터들의 내재적 품질을 평가하기 위해서는 벡터 사이의 스칼라 거리나 벡터 사이의 각도가 이용되었다. 최근 Mikolov 외(2013c)에서 소개한 새로운 평가 방법(word2vec)에 따르면, 단어를 유추하는 방법을 통해 모델의 성능을 평가할 수 있다.
예를 들면, 왕과 남자 사이의 관계는 여왕과 여자 사이의 관계와 비슷해야 할 것이다. 따라서 이 단어들을 벡터화했을 때, 다음 식이 성립해야 한다.
여기서 woman항을 좌변으로 넘기면 다음과 같은 식이 성립한다.
따라서 앞의 3 단어 벡터의 덧셈/뺄셈을 계산한 결과가 queen벡터와 가장 가깝다면, 해당 임베딩 모델은 단어 유추를 정확하게 했다고 할 수 있다.
단어 벡터를 학습하는 주요 모델군은 크게 두 가지 종류가 있다.
-
Global matrix factorization methods
- LSA, HAL, COALS 등이 있다.
- 말뭉치의 통계 정보를 효율적으로 활용하지만, 단어 유추에서는 성능이 떨어져 단어 임베딩 모델로 쓰기에는 차선책으로 여겨진다.
-
Local context window methods
- CBOW, Skip-gram 등의 모델이 있다.
- 행렬 분해법과는 다르게, 단어 유추에서는 성능이 높지만 전체 말뭉치의 통계 정보를 효과적으로 활용하지 못한다.
저자는 위 두 모델군의 단점을 해소하는 새로운 모델로 global log-bilinear regression 모델이 적합하다고 하며, 단어-단어 동시발생빈도행렬을 이용해 훈련한 가중최소자승법 모델 GloVe를 소개한다. 이 모델은 단어 유추 테스트에서 75%의 정확률을 보이며 SOTA의 성능을 선보인다.
2 Related Work
해당 장은 위에서 나왔던 행렬분해법과 얕은 창 기반 방법에 대해 소개하는데, 이 부분은 생략하도록 하겠다.
3 The GloVe Model
말뭉치에서의 단어들의 발생에 대한 통계는 비지도학습 방법론을 통해 단어를 임베딩하는 데에 있어 가장 주가 되는 정보의 원천이다. 하지만
1. 통계에서 의미를 어떻게 생성해낼 수 있는가?
2. 결과로서 도출되는 단어 벡터가 어떻게 그 의미를 표현하는가?
에 대한 의문점이 존재하며, 저자는 이러한 의문점에 대답하는 새 모델, 즉 Global Vectors for Word Represention - GloVe모델을 소개한다. 여기서 Global의 의미는 모델이 말뭉치의 전체적인 통계를 직접적으로 잡아내기 때문에 붙여졌다.
시작하기 전에 몇 가지 표기법을 정의하고 넘어가자.
- : 단어-단어의 동시발생 횟수를 나타내는 행렬
- : 단어 의 맥락 하에서 나타나는 의 빈도수
- : 단어 의 맥락 하에서 나타나는 모든 단어의 수
- : 단어 의 맥락 아래에서 단어 가 나타날 확률
이러한 동시 발생 확률을 통해 단어의 측면을 알 수 있는 간단한 예제로 시작해 보자.
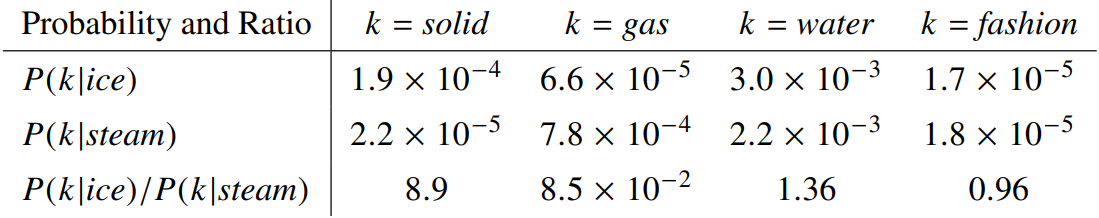
특정 측면을 나타내는 두 단어 와 에 대해 생각해 보자. 구체적으로, 우리가 열역학적 위상(고체-액체-기체)이라는 개념에 대해 관심이 있다고 하여, , 로 설정했다고 생각해 보자.
여러 후보 단어 에 대해, 우리는 단어의 측면을 각 확률의 비율로 알아볼 수 있다.
와 관련성이 높지만 과는 관련성이 낮은 단어에 대해, 우리는 가 클 것으로 기대한다. 마찬가지로, 와 관련성이 높지만 과는 관련성이 낮은 단어에 대해, 우리는 가 낮을 것으로 기대한다. 둘 모두와 관련성이 높은 단어나 둘 모두와 관련성이 낮은 단어의 경우 우리는 두 확률의 비율이 1 근처가 될 것으로 기대할 것이다.
위 표는 이러한 기대가 잘 충족되고 있음을 보여 주고 있으며, 확률 자체를 모델에 학습시키는 것이 아니라 확률 사이의 비율을 모델에 학습시키는 것이 더 적절하다는 것을 보여준다.
값은 단어 에 의존하므로, 일반적인 모델은 다음과 같은 형태를 가질 것이다.
여기서 는 단어 벡터이며, 는 문맥과 관계없는 단어 벡터이다. 위 식에서 우변은 말뭉치로부터 구할 수 있고, 는 아직 지정되지 않은 파라미터로 학습된다.
가 될 수 있는 함수는 매우 많지만, 우리가 원하는 몇 가지 특성을 만족하도록 하면 를 특정시킬 수 있다.
- 먼저, 단어 벡터 공간에 라는 정보를 보존하여 인코딩하고자 한다.
- 벡터 공간은 선형 구조를 가지므로, 벡터 사이의 차이(선형성)를 이용하는 것이 자연스럽다. 따라서 를 두 단어 벡터 사이의 차에 의존하도록 수정할 수 있다.
-
식(2)에서 의 인자는 벡터이고 우변은 스칼라값이기 때문에, 는 인 함수여야 한다. 이러한 함수는 무궁무진하게 많지만, 선형 구조를 캡처하고자 하기 때문에 인자로 들어오는 두 벡터의 내적값을 인자로 이용한다.
이렇게 하면 벡터 차원이 불필요하게 혼합되는 일을 막을 수 있다.
-
단어-단어 동시발생 행렬에서 단어와 문맥 단어의 선택은 임의적이기 때문에 두 역할이 서로 바꿀 수 있어야 한다. 이를 위해서는 사이만 교환되는 것이 아니라 도 교환되어야 한다.
-
최종 모델은 각 단어를 위처럼 다시 라벨링 하는 것에 따라 변하지 않아야 한다.
-
하지만 식(3)에서 사이의 교환을 하면 원래 식이 나오지 않는다. 즉 현재 상태에서는 는 대칭적이지 않다.
-
이를 해결하기 위해서는 가 에서 로 가는 homomorphism이어야 한다. 다시 말해,
를 만족해야 한다.
-
homomorphism이란 한 대수 구조에서 다른 대수 구조로 가는 사상으로, 해당 대수 구조의 연산을 보존하는 사상을 의미한다. 예를 들어, 자연로그 는 에서 로의 homomorphism으로, 다음 식을 만족한다.
-
식(4)는 식(3)에 의해 다음과 같이 정리할 수 있다.
-
를 에서 로 가는 homomorphism중 하나인 지수함수 로 지정하면 다음과 같이 풀 수 있다.
-
식(6)은 항으로 인해 대칭적이지 않지만, 항은 와 독립적이므로 bias 로 넣어줄 수 있고, 마지막으로 의 편향 을 넣어주면 대칭성이 생기며 다음과 같은 식이 된다.
-
-
하지만 로그함수는 보다 큰 숫자에서만 정의되고, 는 이 될 수 있기 때문에 현재 상태에서는 위 식이 제대로 정의되지 않는다.
-
이를 해결하는 한 가지 방법은 함수를 평행이동하는 것이다. , 이렇게 함수를 평행이동하면 로그함수의 스케일은 유지하면서 정의역의 문제를 해결할 수 있다. 이러한 방식의 해결책은 LSA와 깊게 연관되어 있으며 추후 이 방식을 baseline으로 잡고 비교할 것이다.
-
이 모델의 가장 큰 문제점은 모든 동시 발생에 대해 같은 가중치를 부여한다는 점인데, 말뭉치나 사전 크기에 따라 동시발생 행렬의 75-95%의 데이터는 0으로 매우 희소한 행렬이며, 이런 희박한 동시발생들이 더 자주 생기는 케이스에 비해 더 noisy하고 담고있는 정보량도 더 적기 때문에 이러한 단점이 크게 부각된다.
-
위 문제를 해결하기 위해 새로운 가중최소제곱 회귀모델을 제안한다. 식(7)의 편차를 이용해 최소제곱법을 사용하되, 가중치 함수 를 비용함수에 곱해주어 최종적인 비용함수를 만든다.(여기서 는 사전의 크기, 즉 단어의 수이다.)
-
가중치 함수 는 다음 성질을 만족해야 한다.
- . 함수 를 연속함수로 보았을 때, 가 유한할 정도로 에 따라 빠르게 으로 수렴해야만 한다.(이는 임의의 양수 에 대해 이면 충분하다.)
- 희박한 동시발생이 과도하게 가중치가 부여되면 안되므로, 는 단조 증가하는 함수여야 한다.
- 너무 많은 동시발생 또한 과도한 가중치가 부여되면 안되므로, 는 가 큰 값일 때 상대적으로 작아야 한다.(이는 특정 를 기준으로 상수함수로 만들어버리면 조건(2)를 만족하면서 만들 수 있다.)
-
위 조건을 만족하는 함수 의 종류 또한 무궁무진하지만, 저자의 실험 결과 좋은 성능을 내는 는 다음과 같았다.
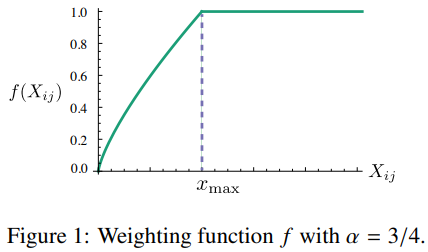
-
의 선택은 모델 성능에 크게 영향이 없었다. 저자는 모든 실험에서 으로 고정하였다.
-
가 일 때의 선형 버전 모델에 비해 더 좋은 성능을 보였다. 이론적으로 어떤 점이 더 좋은지는 나오지 않았지만, word2vec논문에서 사용된 차수와 동일한 스케일링이 적용되었다는 점이 흥미롭다고 밝혔다.
-
3.1 Relationship to Other Models
해당 절에서는 skip-gram과 ivLBL등의 window-based models에 대해 GloVe와 어떤 식으로 연관되는지를 소개한다.(추후 추가 예정)
3.2 Complexity of the model
식(8)과 저자가 정의한 가중치 함수 에 의하면 모델의 계산복잡도는 동시발생 행렬 의 이 아닌 원소의 갯수에 의존한다.(인 경우 이기 때문에 계산 과정에서 생략된다.)
-
간단히 생각해 보면, 이 숫자는 행렬의 전체 원소의 갯수보다는 작거나 같기 때문에, 모델의 계산복잡도는 보다는 작거나 같을 것이다.
-
그냥 보기에는라고 생각하기 쉽지만, 실제로 단어의 수가 10만개만 되어도 그 제곱은 100억개를 넘기 때문에 일반적으로 말뭉치의 크기 보다 크게 된다.
-
따라서 더 타이트하게 모델의 복잡도를 측정하는 작업이 필요하며, 이를 위해서 단어의 동시발생의 분포에 대한 몇 가지의 가정이 필요하다.
- 단어 의 맥락 하의 단어 에 대한 빈도 는 해당 단어 쌍에 대한 빈도 순위 (순위는 맥락 상에서가 아닌 전체 단어 쌍에 대해서 매겨진다.)에 대한 멱함수로 모델링할 수 있다.
- 단어 의 맥락 하의 단어 에 대한 빈도 는 해당 단어 쌍에 대한 빈도 순위 (순위는 맥락 상에서가 아닌 전체 단어 쌍에 대해서 매겨진다.)에 대한 멱함수로 모델링할 수 있다.
-
말뭉치의 전체 단어 수 는 동시발생 행렬 의 모든 원소의 합에 비례한다.
- window 크기, symmetric/asymmetric window인지에 따라 몇 배인지는 달라지겠지만, 단어 맥락 하의 단어 의 빈도 수 는 결국 말뭉치 안에서 결정되기 때문에 자연스럽게 빈도의 전체 합은 말뭉치의 크기에 비례할 수 밖에 없다.
- 마지막 항의 는 일반화된 조화수로, 은 차수의 번째 조화수에 해당한다. 이 때 이 무한대로 가면 리만 제타 함수에 을 넣은 값이 된다. 즉 이다.
- 는 에서 이 아닌 원소의 갯수로, 빈도 순위의 최대값과 동일하다. 또한 식(17)에서 이 아닌 의 최소값 을 넣게 되면(사실 이 아닐 수도 있지만, 적당한 상수 를 넣어도 결과는 같다.) 이 되므로 가 되며, 아래와 같은 식을 얻을 수 있다.
- window 크기, symmetric/asymmetric window인지에 따라 몇 배인지는 달라지겠지만, 단어 맥락 하의 단어 의 빈도 수 는 결국 말뭉치 안에서 결정되기 때문에 자연스럽게 빈도의 전체 합은 말뭉치의 크기에 비례할 수 밖에 없다.
-
결국 중요한 것은 와 의 크기가 클 때의 상황이기 때문에, Apostol(1976)에 따른 조화수의 근사를 이용할 수 있다.
-
이에 따르면 아래와 같은 결과를 얻는다.
-
식(21)은 의 범위에 따라 하나의 지배항을 가진다.
- 식(21)에서 인 경우 2번째 항이 지배항이 되고, 인 경우 1번째 항이 지배항이 된다.
-
저자에 따르면 일 때 가 식(17)에 의해 잘 모델링 되었다고 한다. 따라서 이 경우 이 되며, 최종적으로 보다 훨씬 좋은 복잡도를 가짐을 알 수 있다.
-
또한, 이 경우 window-based model의 보다 작기 때문에 GloVe 모델의 계산량이 skip-gram 등의 모델보다 더 적다고 말할 수 있다.
4 Experiments
4.1 Evaluation methods
Mikolov 외(2013a)의 단어 유추 과제, Luong 외(2013)에 설명된 다양한 단어 유사성 과제 및 Tjong Kim Sang and De Meulder( 2003)의 개체명 인식 과제를 위한 CoNLL-2003 공유 벤치마크 데이터셋을 활용해 측정했다고 한다.
Word analogies
단어 유추 과제는 "a와 b의 관계는 c와 _의 관계와 같다. _는 무엇인가?"와 같은 질문들로 구성되어 있다.
데이터셋에는 총 19544개의 이런 질문들이 있으며, 의미론적/구문론적 부분집합으로 나뉜다.
- 의미론적 질문
- "아테네와 그리스의 관계는 베를린과 무엇의 관계일까?" 등 사람과 장소에 대한 유추이다.
- 구문론적 질문
- "dance가 dancing일 때 fly는 무엇일까?" 등 동사시제, 형용사 형태의 유사성에 대한 유추이다.
이러한 질문에서 코사인 유사도를 이용해 벡터와 가장 유사도가 높은 벡터 를 얻을 수 있고, 이를 통해 얻은 단어 d가 실제 정답과 같은지를 확인한다.
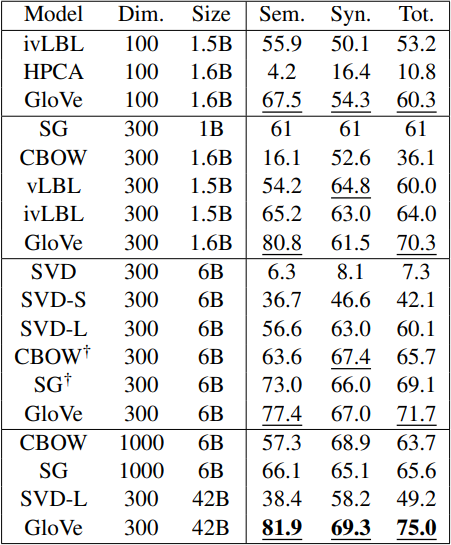
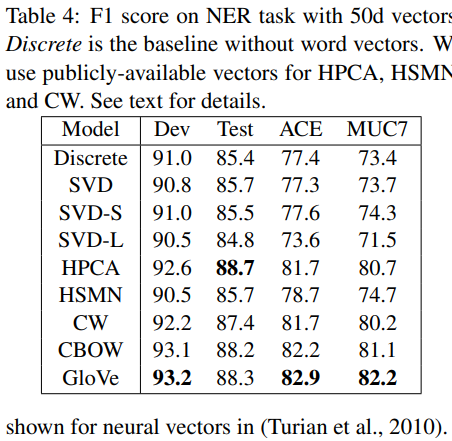
skip-gram과 CBOW모델의 경우 word2vec모델을 이용하였다고 하며, 전반적으로 GloVe의 성능이 가장 높은 모습을 볼 수 있다.
Word similarity
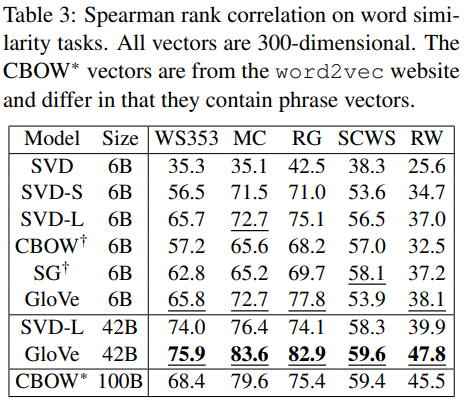
단어 유추에 대한 과제가 GloVe모델의 메인 타겟이지만, 단어 유사도에서도 높은 성능을 보이는 것을 볼 수 있다.
Named entity recognition
개체명 인식 과제를 위한 CoNLL-2003 공유 벤치마크 데이터셋을 활용하였으며, 이는 사람, 장소, 조직, 기타 등 4가지 객체 타입에 대해 표기된다. 후술생략.
4.2 Corpora and training details
- 다양한 사이즈의 5가지 종류의 말뭉치를 모델에 학습시켰다.
- a 2010 Wikipedia dump with 1 billion tokens
- a 2014 Wikipedia dump with 1.6 billion tokens
- Gigaword 5 which has 4.3 billion tokens
- the combination Gigaword5 + Wikipedia2014, which has 6 billion tokens
- 42 billion tokens of web data, from Common Crawl
- Stanford tokenizer를 이용하여 말뭉치를 소문자로 바꾸고 토큰화 한 뒤 가장 많이 등장한 40만개의 단어에 대한 사전을 이용해 동시 발생 행렬 를 구성한다.
- 의 생성 과정에서, 맥락 윈도우의 크기와 왼쪽, 오른쪽 맥락을 구분할 지에 대한 여부를 선택한다.
- 서로 거리가 먼 단어는 관련성이 적다고 볼 수 있기 때문에, d개의 단어만큼 떨어진 단어에는 1/d만큼의 가중치를 부여한다.
- 모든 실험에서 으로 설정하였으며, AdaGrad최적화를 이용해 모델을 훈련시켰다.
- 이 아닌 의 모든 원소에 대해 확률적으로 샘플링하고, 초기 학습률은 0.05이다.
- 300차원보다 낮은 벡터 모델에 대해서는 50번의 에포크, 그 이상의 벡터 모델의 경우 100회 반복을 진행했다.
- 별다른 언급이 없는 경우, 단어의
맥락은 해당 단어의 왼쪽으로 10개의 단어, 오른쪽으로 10개의 단어를 지칭한다. - 모델은 두 개의 행렬, 와 를 생성한다. 가 대칭행렬인 경우, 와 는 초기값이 랜덤으로 지정되는 부분을 제외하면 동일하다. 두 행렬의 단어벡터는 동일한 성능을 보일 것이다.
- 그런데 신경망 학습에서 bagging을 적용하는 것이 일반적으로 과적합과 노이즈를 줄이고 성능을 높인다는 증거에 따라, 두 행렬의 합 를 단어 벡터로서 사용한다. 이를 통해 약간의 성능 향상을 기대하고, 특히 단어 유추에서 많은 향상이 있었다.
- 다양한 최신 모델의 결과와 word2vec모델을 사용한 결과를 SVD베이스라인과 비교해본다.
- SVD베이스라인의 경우, 최빈 10000개의 단어에 대해 잘린행렬 을 만들어 비교한다.
- SVD-S는 SVD베이스라인에 sqrt를 취한 것이고, SVD-L은 위에서 나온 것처럼 log1p를 이용한 모델이다.
4.3 Results
GloVe모델은 대부분의 베이스라인 모델보다 훨씬 높은 성능을 보였으며, 더 적은 벡터 차원과 말뭉치 크기를 가지고도 더 높은 성능을 내는 일도 있었다. 단어 유추, 유사도, 개체명 인식 과제에서 CoNLL의 HPCA를 제외하면 모든 평가에서 다른 방법들보다 우수한 성능을 보였다. GloVe벡터가 다운스트림 NLP 작업에서 유용하게 쓰일 수 있다는 결론을 내릴 수 있다.
4.4 Model Analysis: Vector Length and Context Size
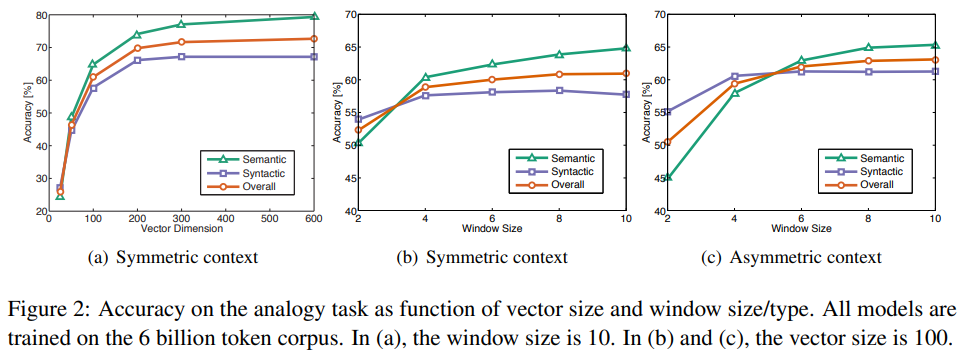
- (a)에서, 벡터 차원이 200을 넘어서면 별다른 차이가 없는 모습을 볼 수 있다.
- (b)와 (c)에서 윈도우 사이즈와 대칭성을 비교해본 결과를 볼 수 있다. 비대칭적 맥락을 사용했을 때 작은 윈도우 크기에서 구문론적 과제가 높은 점수를 보이는 것을 볼 수 있는데, 문법적인 정보는 대부분 단어의 순서와 직전의 맥락에 의존한다는 직관을 생각해 보면 그럴듯하게 볼 수 있다.
- 하지만 의미론적 정보는 국지적이지 않은 경우가 많으며, 윈도우 사이즈가 커질수록 더 많은 정보를 가져온다.
4.5 Model Analysis: Corpus Size
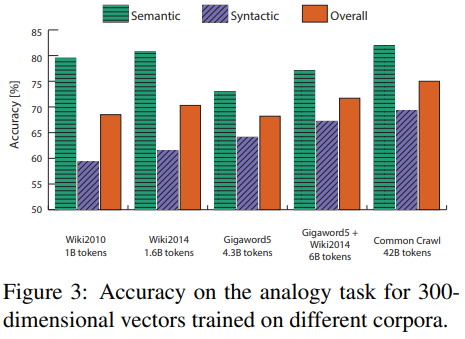
그림(3)에서, 300차원의 벡터 임베딩을 각각 다른 말뭉치에 대해 수행한 결과를 볼 수 있다.
- 구문론적 과제의 경우 말뭉치 크기가 커질수록 같이 단조롭게 커지는 모습을 볼 수 있다. 이는 더 많은 데이터가 더 정확한 통계를 생산할 것이라는 점에서 합리적이다.
- 하지만 의미론적 과제의 경우 더 적은 말뭉치인 Wikipedia의 모델이 Gigaword5보다 높은 성능을 보였는데, 데이터 유추 과제가 장소에 대한 문제가 많은데 위키피디아에 장소에 대한 포괄적인 글이 많다는 점, 오래되고 틀릴 수도 있는 Gigaword에 비해 더 최신 정보와 언제든지 수정 가능한 정보를 가지고 있다는 점에서 이해해 볼 수 있다.
Model Analysis: Run-time
윈도우 사이즈 10, 40만개의 단어 어휘, 60억개의 말뭉치 토큰으로 동시발생행렬 를 구성하는데 85분이 소요되었다. 가 주어졌을 때 모델 훈련에 걸리는 시간은 벡터 크기와 반복 횟수에 따라 달라지는데, 300차원 벡터의 경우 1회의 에포크에 14분이 소요되었다.
Model Analysis: Comparison with word2vec
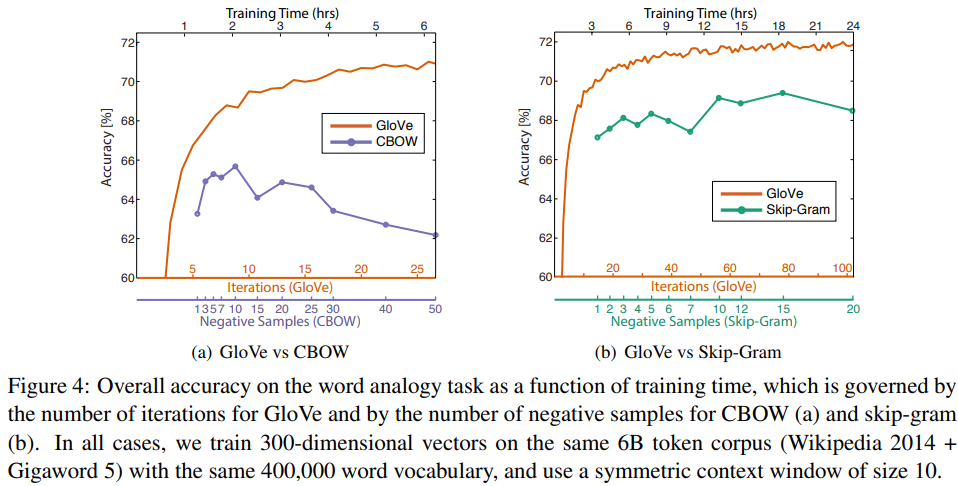
- GloVe와 word2vec을 비교하는 것은 성능에 매우 많은 영향을 미치는 변수가 많기 때문에 정량적으로 측정하기 쉽지 않다.
- 벡터 차원의 크기, 윈도우 사이즈, 말뭉치, 단어 어휘 등의 변인을 모두 맞췄을 때, 남은 중요한 변수로 훈련 시간이 있다.
- GloVe의 경우 훈련의 반복 횟수가 훈련 시간에 가장 적절한 변수가 될 것이다.
- 하지만 word2vec의 경우, 마찬가지로 훈련 반복 횟수를 변수로 잡기가 어렵다.
- 코드가 단일 에포크에 맞게 설계되어 있어 수정하기가 쉽지 않다.(?..)
- 다른 방법으로, 네거티브 샘플링의 수를 추가하면 모델이 훈련시에 봐야 할 단어의 수가 늘어나므로 어떤 면에서는 에포크를 추가하는 것과 비슷한 효과를 볼 수 있다.
- 사족) 사실 이런 상황에서 비교를 하는 것이 맞나? 싶기는 하다. 저자도 논문에서의 분석은 단순화된 분석으로, 제대로 된 분석을 위해서는 이렇게 비교하지 말아야 할 것이라고 언급했다.
- 아무튼 이렇게 네거티브 샘플링에 따른 word2vec모델과 훈련 반복 횟수에 따른 GloVe모델을 비교해 보면, 같은 말뭉치, 어휘, 윈도우 사이즈, 훈련 시간, 벡터 차원의 크기에 대해 GloVe 모델이 word2vec모델보다 지속적으로 높은 성능을 보이는 것을 볼 수 있다.
5 Conclusion
분산 단어 표현을 학습시키는 방법이 갯수 기반과 예측 기반 방법 중 어떤 방법이 더 좋은지에 대한 관심이 높아지고 있다. 현재로서는 예측 기반 방법이 더 지지를 얻고 있는데, 이번 논문에서 갯수 기반 데이터의 주요 이점을 활용하는 동시에 word2vec과 같은 의미있는 선형 하부구조를 포착하는 log-bilinear 예측 기반 모델의 장점도 흡수하는 GloVe모델을 소개하였다. 그 결과로 여러 다양한 분야에서 매우 높은 성능을 보이는 모델을 소개할 수 있었다.
질의응답
-
3에서 가 들어가는 이유
- 최종 모델에서 각 단어를 다시 라벨링 하는 것()에 따라 결과가 변하지 않는 를 만들고 싶었기 때문이다.
-
는 대칭행렬이 아닐 수도 있다.
- 맞다. context window를 asymmetric window를 쓰는 경우나 왼쪽 맥락과 오른쪽 맥락의 가중치를 다르게 주는 경우 이 성립하지 않을 수도 있다. 실제로 논문에서도 asymmetric window를 쓰는 경우를 소개하고 있으며, 이 경우 와 는 서로 다른 벡터가 된다.
-
Figure 4에서 CBOW가 training time이 늘어날 수록 정확도가 낮아지는 이유? 비교 그래프에 대한 해석
-
위에서 설명한 것처럼, GloVe모델은 훈련 반복 횟수에 따른 훈련 시간, CBOW는 네거티브 샘플링의 샘플 숫자(학습할 때 이용할 네거티브 샘플의 갯수)에 따른 훈련시간을 나타내었다.
-
네거티브 샘플링의 샘플 숫자가 늘어날 때 훈련 시간이 늘어나는 이유는 모델이 업데이트해야 할 파라미터의 숫자가 늘어나기 때문이다.(포지티브 샘플 수 + 네거티브 샘플 수에 비례)
-
따라서 두 모델의 아래축은 비교할 수 없으며, 실제로 비교해야 할 부분은 훈련 시간이다.
-
같은 훈련 시간을 투자했을 때, GloVe의 성능이 CBOW나 skip-grams보다 항상 높다는 점을 보면 좋을 것 같다.
-
+사족) 네거티브 샘플이 10보다 커졌을 때 성능이 떨어지는 이유를 논문에서는 네거티브 샘플링 기법이 타겟 확률분포를 제대로 근사하지 못했기 때문이라고 추측하고 있다. noise-contrastive estimation에서는 샘플링을 더 많이 할 수록 성능이 올라갔는데, 여기서는 왜 그렇게 되는지 잘 모르겠다.
-
-
라는 행렬을 만드는데 필요한 연산이 제곱이 되니까 word2vec보다 복잡한 것이 아닌가?
- word2vec의 계산복잡도는 말뭉치의 크기에 비례한다. 즉 이다.
- 행렬 를 구성하는데 필요한 계산복잡도 또한 말뭉치의 크기에 비례하지만, 의 경우 1번만 계산하면 fix되기 때문에 더 이상 학습과정에서 추가적인 계산이 필요하지 않다. 따라서 모델의 전체 계산복잡도의 지배항이 될 수 없다.
- 모델 학습에 필요한 계산복잡도
- 제곱이 된다는 부분을 보면, 일단 와 는 크기가 다르다. 의 경우 말뭉치 토큰으로 구성되어 각 문서에서 나타나는 단어의 총 횟수(중복포함)이지만, 의 경우 중복을 포함하지 않고, 빈도가 높은 단어에 한해서 사전을 구성하기 때문에 일반적으로 두 집합의 크기는 가 된다.
- 하지만 의 전체 요소를 사용하면 횟수의 연산이 필요하기 때문에, 0인 요소를 제외하고 계산했을 때의 계산복잡도가 이 되는 것이다.
- 0인 요소를 제외해도 되는 이유는, 우리의 목적함수 에 붙어있는 가중치 함수 가 을 만족하기 때문이다.(따라서 0인 경우는 계산할 필요가 없다.)
-
GloVe 는 단어를 가지고 단어를 추측(predict)하면서 학습하는 방식이 아닌가?(X matrix 가 있는데)
- 학습 과정을 보면 알겠지만, GloVe의 학습은 두 단계로 구성되어있다.
- 행렬을 구성한다.
- 구성한 행렬 를 바탕으로 와 를 학습시킨다.
- 1번 항목에서 볼 수 있듯이, 는 학습하는 행렬이 아니라 구하는 행렬이다.(즉, 말뭉치, 벡터 차원, 윈도우 사이즈, 단어 가중치가 고정되었을 때 구해지는 는 반드시 하나로 정해져 있다.)
- 다른 말로, 1번 과정은 단어와 단어쌍의 관계를 이용하기는 하지만, skip-gram이나 CBOW처럼 학습에 이용하는 것이 아니라 두 단어의 맥락 관계에 따라 단순히 행렬에 값을 더해주는 것이다.
- 2번 항목에서도 마찬가지로, 단어 벡터 와 가 존재하기는 하지만 한 벡터를 가지고 다른 벡터를 예측하는 것이 아닌 독립적인 두 벡터를 경사하강법을 이용해 업데이트 하는 것이다.
- 따라서 두 모델은 학습하는 과정이 완전히 다르다.
- 학습 과정을 보면 알겠지만, GloVe의 학습은 두 단계로 구성되어있다.
