Activation Function
각 Layer에서 비선형 변환을 적용해, 신경망이 더 잘 학습하고 복잡한 작업을 수행할 수 있도록 한다.
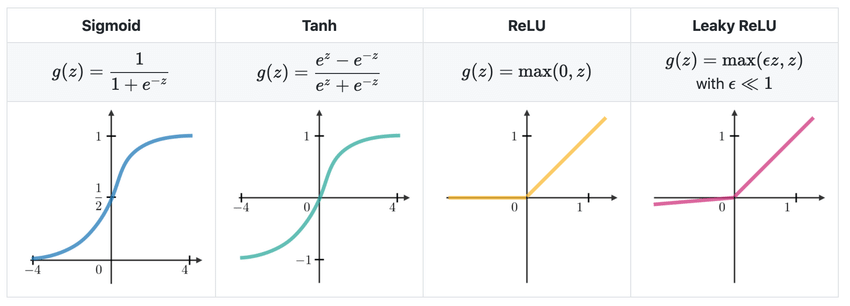
Sigmoid Function
Sigmoid 함수는 입력값을 0과 1 사이의 값으로 압축한다. Binary Classification Problem에 적합하며, 신경망의 Output Layer에서 주로 사용된다.
입력값이 극단적인 경우에도 출력값이 0 또는 1에 가까워지며, 이로 인해 Gradient Vanishing이 발생할 수 있다.
Tanh
Hyperbolic Tangent는 Sigmoid Function을 단순히 rescale 및 shift한 것이다. RNN, LSTM에서 사용한다.
Sigmoid와 유사하지만 출력값이 0 중심으로 분포되어 Gradient Vanishing 문제가 덜 발생한다.
Softmax Function
Softmax 함수는 Output을 0과 1 사이로 압축하고, 각 클래스 값이 전체 값에서 차지하는 확률을 계산한다. 여러 출력 클래스 값에 대해, 출력 확률의 합은 항상 1이 된다. 일반적으로 Multi Class Classification의 마지막 Layer에서 사용한다.
ReLU (Rectified Linear Unit)
ReLU는 단순한 비선형 함수로, 입력이 양수이면 그대로 반환하고, 음수이면 0으로 반환한다. 신경망의 Hidden Layer에서 가장 널리 사용된다.
계산이 간단하고 Gradient Vanishing 문제가 적다.
Leaky ReLU
ReLU의 개선된 버전으로, Gradient Vanishing 문제를 해결하기 위해 등장했다. 음수 입력에 대해 작은 기울기를 유지하여 Gradient가 0이 되는 것을 피할 수 있다.
Loss Function
예측값과 실제값의 차이를 어떻게 계산할지 정의하여, 신경망 모델이 정답으로부터 얼마나 멀리 벗어나 있는지 알려준다.
MSE (Mean Squared Error)
MAE (Mean Absolute Error)
Binary Cross Entropy
Binary Classification에서 사용하며, 일반적으로 마지막 Layer에 Sigmoid Activation을 추가한다.
Cross Entropy Loss
Multi-Class Problem에서 사용한다.
