[TIL] Array vs Linked List
Array
Array란?
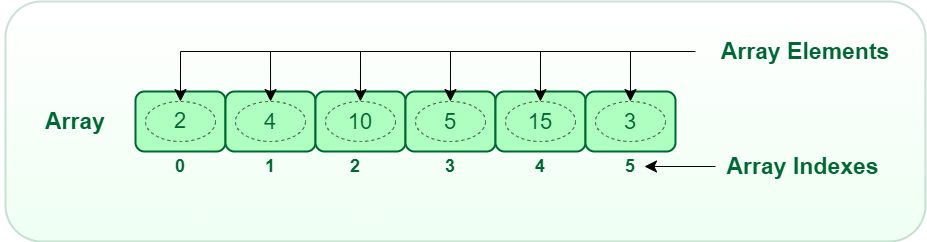
Array는 프로그래밍에서 일련의 요소들을 순차적으로 저장하는 데이터 구조입니다. 이러한 요소들은 같은 데이터 타입을 가지며, 각 요소는 배열 안에서 인덱스(index)라고 불리는 숫자로 접근할 수 있습니다. 인덱스는 보통 0부터 시작하여 배열의 크기보다 하나 작은 값을 가집니다.
예를 들어, 5개의 정수를 저장하는 배열은 다음과 같이 표현할 수 있습니다:
[10, 20, 30, 40, 50]Array 장점
요소에 빠르게 접근할 수 있다.
가장 기본적인 자료구조인 Array는 논리적 저장 순서와 물리적 저장 순서가 일치한다.
따라서 인덱스로 해당 원소에 Big-O(1)에 해당 원소로 접근할 수 있다. 즉 random access가 가능하다.
Array 단점
삽입이나 삭제가 비효율적이다.
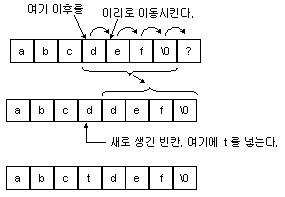
삽입 또는 삭제 과정에서는 해당 원소에 접근하여 작업을 완료한 뒤(O(1)), 또 한 가지의 작업을 추가적으로 해줘야 하기 때문에, 시간이 더 걸린다.
만약 삭제라고 한다면, 중간에 원소를 삭제하고 그 뒤부터 요소들을 shift해줘야 하기 때문에 시간 복잡도는 O(n)이 된다.
삽입 또한 마찬가지 이다.
크기가 고정적이다.
Array는 생성할 때 크기를 지정하고 이후에 크기를 동적으로 변경할 수 없습니다. 만약 배열의 크기를 초과하여 데이터를 추가하려면, 새로운 배열을 생성하고 기존의 데이터를 복사해야 합니다. 이로 인해 삽입과 삭제가 비효율적이며, 크기를 자주 변경해야 하는 경우에는 다른 자료구조를 고려해야 합니다.
Linked List
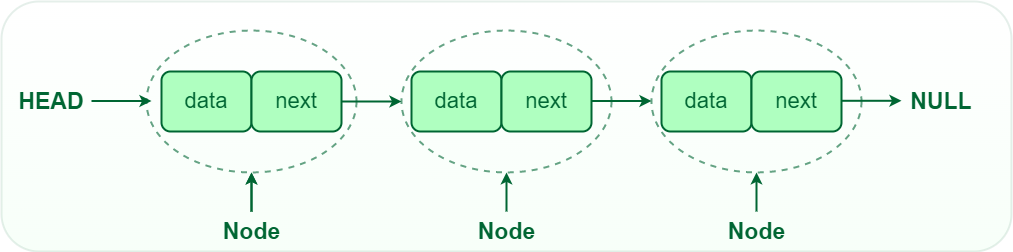
Linked List(연결 리스트)는 배열의 삽입과 삭제가 비효율적인 문제를 해결하기 위한 자료구조입니다. Linked List는 각 노드(Node)들이 데이터와 다음 노드를 가리키는 포인터(주소)로 구성됩니다. 각 노드들이 연결되어 있기 때문에 순차적으로 데이터를 저장하지 않고, 논리적으로 연결되어 있는 형태로 데이터를 관리합니다.
Linked List 장점
삽입이나 삭제가 빠르다.

각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있다.
삽입이나 삭제를 할 때 해당 부분만 다른 값으로 변경하면 되기 때문에 삽입과 삭제를 O(1)만에 해결할 수 있다.
동적 크기
배열과 달리 동적으로 크기를 조정할 수 있습니다. 필요에 따라 노드를 추가하거나 제거할 수 있습니다.
Linked List 단점
결국 삽입이나 삭제가 O(n)시간이 필요하다.
원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 한다는 것이다. Array 와는 달리 논리적 저장 순서와 물리적 저장 순서가 일치하지 않기 때문이다. 이것은 일단 삽입하고 정렬하는 것과 마찬가지이다. 이 과정 때문에, 어떠한 원소를 삭제 또는 추가하고자 했을 때, 그 원소를 찾기 위해서 O(n)의 시간이 추가적으로 발생하게 된다.
Linked List의 종류
단일 연결 리스트 (Singly Linked List)
단일 연결 리스트는 각 노드가 데이터와 다음 노드를 가리키는 하나의 포인터로 구성됩니다. 리스트의 시작 노드를 가리키는 특별한 포인터인 헤드(Head)가 있으며, 리스트의 끝은 NULL로 표시됩니다.
이중 연결 리스트 (Doubly Linked List)
이중 연결 리스트는 단일 연결 리스트와 비슷하지만, 각 노드가 데이터와 이전 노드와 다음 노드를 가리키는 두 개의 포인터로 구성됩니다. 이전 노드를 가리키는 포인터를 추가함으로써, 뒤에서부터도 리스트를 순회할 수 있습니다. 이중 연결 리스트는 메모리 공간을 더 많이 사용한다는 단점이 있습니다.
원형 연결 리스트 (Circular Linked List)
원형 연결 리스트는 단일 연결 리스트와 유사하지만, 마지막 노드가 첫 번째 노드를 가리키게 됩니다. 이렇게 함으로써, 끝과 시작이 연결되어 순환하는 구조가 됩니다. 원형 연결 리스트는 특정 작업을 순환적으로 처리해야 할 때 유용합니다.
언제 Array와 Linked List를 사용할까?
Array
데이터의 크기가 미리 정해져 있고, 빠른 인덱스 접근이 필요한 경우에 적합합니다.
Linked List
데이터의 크기가 동적으로 변경되거나 삽입과 삭제가 빈번한 경우에 적합합니다. 또한 메모리 사용에 유연성이 필요한 경우에도 유용합니다.

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.