
LTV
이전 포스팅에서 LTV가 중요한 이유를 어느정도 느끼셨을거라고 생각이 듭니다!
LTV 점수가 높다면 그 만큼 기존 고객 기반이 탄탄하게 유지되고 있구나 확인할 수 있을거구요! 그런데 제가 찾아본 바로는 LTV를 산출하는식이 한두개가 아니었습니다. 각 회사마다 다른 LTV산출법을 사용하고 있고, 응용해서 사용하고 있었습니다.

그 중에서 넥슨인텔리전스랩스 테크 블로그에서 알게된 BG/NBD 와 Gamma-Gamma 모델을 이용하여 본격적으로 LTV를 산출해 보려고 합니다.
일단, 게시된 글에서 사용한 LTV 산출법을 간단하게 요약해보면 아래와 같은데요!
LTV = 고객별 미래의 예상 구매 횟수 * 예상 평균 수익
- 미래의 예상 구매 횟수를 BG/NBD 모델을 통해서 구한다.
- 미래의 예상 평균 수익을 Gamma-Gamma 모델을 통해서 구한다.
각 모델이 어떤 목적을 갖고있는지 정도만 이해한채로
주어진 데이터를 같이 보면서 BG/NBD 모형과 , Gamma- Gamma 모형을 같이 설명해드리려고 합니다!
✔️ 해당 모델에 대해서 자세히 정리가 된 넥슨 블로그와 아래의 게시글을 토대로 정리 되었습니다.😌
DATA
데이터는 kaggle의 UCI Onlie RETAIL II Data Set 을 이용합니다.
- Invoice: Invoice number. If this number starts with ‘C’, it means this transaction is cancelled.
(송장 번호 이며, C 인경우 취소를 의미한다)- StockCode: Product code (상품 코드)
- Description: Product Name (상품 이름)
- Quantity: Product counts (상품 물량)
- InvoiceDate: Transaction date (거래 날짜)
- Price: A single product price (상품 가격, 파운드)
- CustomerID: Unique customer number (유니크한 고객 번호)
- Country: Customer’s country name (고객 지역)
필요 패키지
!pip install lifetimes
!pip install openpyxl
from datetime import datetime, timedelta,date
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from lifetimes.plotting import *
from lifetimes.utils import *
from lifetimes import BetaGeoFitter
from lifetimes.fitters.gamma_gamma_fitter import GammaGammaFitter
from hyperopt import hp, fmin, tpe, rand, SparkTrials, STATUS_OK, space_eval, Trials
먼저, BG/NBD 모델을 이용해봅시다!
✔️ 잠깐! 들어가기전..
📝BG/NBD 모델이해 해보기
(바쁘시면 아래의 핵심파트만 확인!)
BG/NBD 모델은 다른말로 Buy Till You Die 모델 (BTYD)이라고도 불리는데요
" 죽을때까지 구매하라..? "
이름에서 볼 수 있듯이 한마디로 이 모델은 아래의 두가지 확률을 통해 고객의 예상 구매횟수를 측정합니다.
1. 고객이 반복적인 구매 행위를 할 가능성(Buy)
2. 고객이 구매 행위를 그만둘 가능성(Die)
그리고 위 모형은 아래의 가정들을 따르는데요. 확률분포와 연결해서 이해해야 합니다.
(BG/NBD는 확률분포의 이름에서 따온 거였군요..!)
왜 BG/NBD 인지 확률분포를 간단하게 설명하고 같이 이해해보려고 합니다. 그리고 해당 모델을 돌리기 위해서 어떤 input들이 필요한지 확인해봅시다!
① BG (Beta, Geometric) / NBD (Negative Binomial Distribution, 음이항 분포)
- "고객이 이탈하게 되는 시점, 구매를 더이상 안 하게 되는 시점"이 있다고 가정
- 마지막 구매후 돌아 오지 않을 확률(dropout rate) → 기하분포를 따른다 가정
- 이 확률은 고객마다 다르다 → 베타분포를 따른다 가정
- 고객마다 일정한 기간 동안 구매하는 횟수는 다르다 → 감마분포를 따른다 가정
- 고객마다 일정한 기간 동안 구매 횟수와 구매하지 않을 확률은 서로 독립이다.
✔️ BG 는 베타분포와 기하분포와 관련되어있고
NBD는 포아송분포 + 감마 분포의 결합으로 만들어진다. (증명과정Gamma–Poisson mixture)
확률분포 예시로 이해해보기
8월 한달동안 구매한 내역이 다음과 같다면
| 날짜 | 구매금액 |
|---|---|
| 2023-08-01 | 50,000 |
| 2023-08-23 | 70,000 |
① 포아송분포는 "단위 시간 당 어떤 사건이 발생할 횟수"에 대한 확률분포입니다.
"사건/성공 = 고객의 구매" 이 이루어졌는지에 대한 정보
ex) 한달 동안 2번 구매
② 지수분포는 "어떤 사건이 한 번 발생하는데 걸리는 시간"에 대한 확률분포
그리고 지수분포의 합은 감마분포이며 "n번 발생하는데 걸리는 시간"에 대한 확률분포입니다.
"n번 구매하는데 걸린 시간"
ex) 2번 구매하는데 걸린 시간 = 한달
③ 기하분포는 "어떤 사건이 1회 발생할 때까지 걸리는 시행횟수"에 대한 확률분포 입니다
"여기서 사건은 이탈!" 고객이 구매를 중단했는지
④ 베타분포는 확률에 대한 분포 (0~1)
이탈률 구매를 중단할 확률
📝 BG/NBD 핵심정리
- BG/NBD 는 확률분포의 이름에서 따온 것
- 고객별 구매정보를 갖고 위 분포를 따른다 가정하에 BG/NBD 모형을 이용하면 고객별로 예상 구매 횟수를 구할 수 있다. 예상 구매횟수는 아래의 확률을 통해 계산된다.
- 고객이 반복적인 구매 행위를 할 가능성(Buy)
- 고객이 구매 행위를 그만둘 가능성(Die)
고객들의 데이터를 통해 Buy 와 Die를 측정해야한다. 이를 위해 아래의 변수들이 필요하다. 즉, BG/NBD 모델에 필요한 input은 다음과 같다.
- Recency : 최신성, 첫 구매일과 마지막 구매일의 차이. 1번만 구매한 경우 최신성은 0
- Frequency : 얼마나 자주 구매했는지
- T : 첫구매 이후 집계기준까지 지난시간
📝Gamma Gamma 이해해보기
✔️ 고객의 예상 구매 금액을 계산하는 모형이며 고객별 평균 금액 정보 (Monetary)들이 필요합니다.
Gamma Gamma 모형 또한 아래의 가정하에 진행 됩니다.
가정
- 고객별 구매 금액은 평균 구매 금액 중심으로 랜덤하게분포
- 고객마다 평균 구매 금액이 다르고, 한 고객의 평균 구매 금액은 시간에 따라 불변 -> 감마분포를 따른다고 가정한다.
- 평균 구매 금액(Monetary)은 frequency와 독립이어야한다.
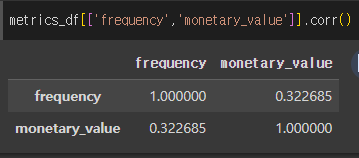
→ 실제로 이 모델을 사용하려면 두 벡터 간의 Pearson 상관 관계가 0에 가까운지 확인해야 합니다.

data[['monetary_value', 'frequency']].corr()평균 구매 금액에 Gamma 분포를 가정하는 이유???
많은 분포중에 왜 Gamma 분포인가!!
고객별 금액 정보가 데이터를 생각해보자.
돈을 쓴다 = 구매 금액이 0원 이상이며, 무엇을 사느냐에 따라 가격이 차이가 크다.
즉, 금액의 분포가 0이상이고 오른쪽으로 치우쳐져 있는 형태를 띄게 된다.
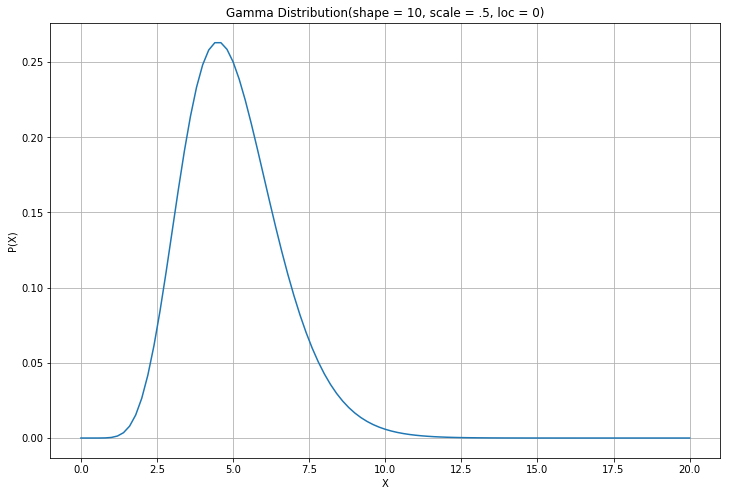
이렇듯 감마분포는, 비대칭적인 분포를 갖을때 모델링하기 좋은 분포이다!
모델 적용해보기
lifetimes 패키지
lifetimes 패키지를 이용하여 LTV를 산출하는 전체적인 흐름은 다음과 같습니다!
① 데이터 불러오기
② 일부 전처리
③ Frequency Recency T Monetary 변수 생성
④ 데이터셋 분리
⑤ L2 페널티 파라미터 구하기
⑥ 모델 적용
전처리
- Invoice 가 C 인 경우 취소된 물품 이므로 해당 데이터 제외
- GammaGamma 모델에서 이용할 monetary 값 측정을 위한 구매개수와 가격이 집계된 고객별 'TotalPrice' 컬럼을 추가 해주었습니다.
- 일자별로 바꾸기위해 datetime -> date 형으로
- 주문 1개 이상한 고객
- 결측값 제거
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']).dt.date
# C 인경우 반품으로 제거
df = df[~df["Invoice"].str.contains("C", na=False)] # na값 채우는 기능이다. na값을 False로
df = df[df["Quantity"] > 0]
df['TotalPrice'] = df['Price'] * df['Quantity']
df.dropna(inplace=True)
변수 생성
다시 데이터로 돌아가서!! LTV를 산출하기 위해서 필요한 컬럼은 아래와 같습니다.
- Frequency 고객별로 구매 빈도
- Recency 첫 구매 - 마지막 구매
- T 첫 구매하고 몇일이 지났는지
- Monetary 구매 금액
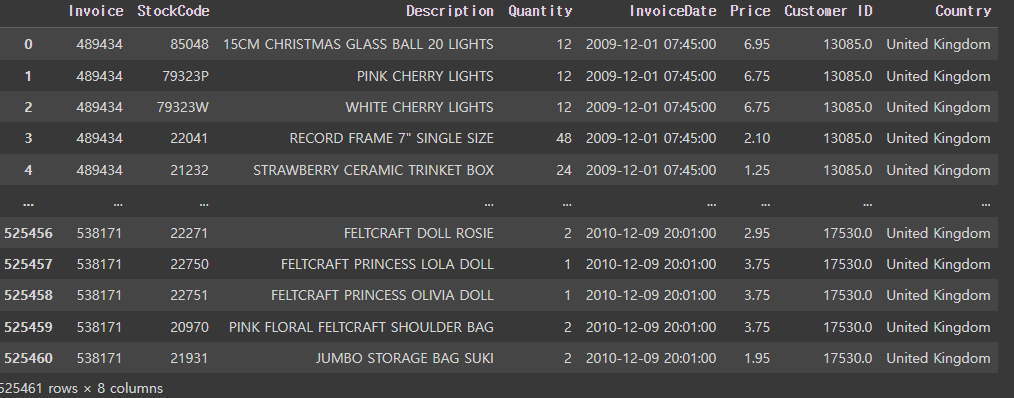
제공하는 lifetimes 패키지 함수에서 편하게 구할수 있었습니다. 집계일 기준이 되는 가장 마지막 날짜를 current_date로 설정해주고 summary_data_from_transaction_data 함수를 이용합니다.
current_date = df['InvoiceDate'].max()
metrics_df = summary_data_from_transaction_data(df
, customer_id_col = 'Customer ID'
, datetime_col = 'InvoiceDate'
, monetary_value_col='TotalPrice'
, observation_period_end=current_date)
metrics_df.head()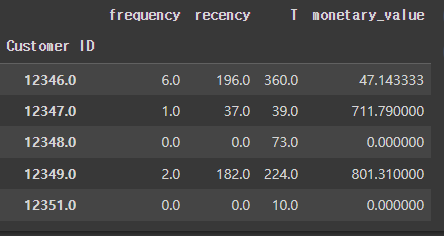
'12346' 고객은 총6번 구매하였고, 첫 구매와 마지막 구매일 차이가 196일. 평균 구매액은 약 47파운드. 그리고 첫 구매이후 360일이 지난 고객이군요🤔 (첫 구매일수를 제외해서 계산 됩니다.)
데이터셋 분리
재료가 준비되었으니 모델적용을 위해 데이터를 분리해야합니다.
lifestyle에서는train data를calibration data,test data를holdout data라고 표현합니다. 차이점은 랜덤하게 분리하는것이 아닌 특정 시점을 기준으로 분리하기 때문에 몇일을 기준으로 분리할지holdout_days를 정해주어야합니다.
몇일로 분리해야할지 따로 정해진건 없다고하는데요! 해당 데이터의 경우,
(2009-12-01) ~ (2010-12-09) 약 1년치(360일) 데이터 입니다. 예제와 같이 90일로 나누었습니다.
calibration_period_end= (train 데이터) calibration data의 끝 부분
observation_period_end= (test 데이터) holdout data 의 끝 부분
# define a notebook parameter making holdout days configurable (90-days default)
# 어느 시점을 기준으로 훈련/테스트로 나눌지 정해야한다.
holdout_days = 90
calibration_end_date = current_date - timedelta(days = holdout_days)
metrics_cal_df = calibration_and_holdout_data(df
,customer_id_col = 'Customer ID'
,datetime_col = 'InvoiceDate'
,calibration_period_end=calibration_end_date # train end
,observation_period_end=current_date # test end
,monetary_value_col='TotalPrice')
metrics_cal_df.head()L2 penalty
모형을 적합하기전에 L2 penalty 를 적용해야합니다.
일반적으로 선형 회귀 모델에 과적합 방지를 위해 적용하는것으로 알고 있는데 비슷한 이유인것 같습니다. lifetime공식페이지에서도 "샘플사이즈가 작다면 매개변수가 믿을 수 없을 정도로 커질 수 있으므로 l2 페널티를 추가하여 이러한 매개변수의 크기를 제어한다"고 되어있었습니다!

L2 penalty를 적용하기 위해 훈련/테스트로 분리된 데이터에서 frequency가 0 이상인 데이터에 적용해야합니다. 그 이유는 들어가기전 설명했던 BG/NBD 모형의 가정에 어긋나기 때문인데요!
✔️ frequency가 0 인경우 , (총 구매일수-1) 값이 0 이다!
👉 전체 기간 동안 구매 일수가 1일인 고객, 첫 구매만 한고객이다.
👉 반복적인 구매를 한 고객들이 아니다.
👉 BG/NBD 모형의 가정에 어긋난다.
frequency가 0 인경우를 제외하여 L2 penalty 적용을 위한 데이터를 따로 만들어 줍니다.
# L2 penalty 적용을 위한 데이터
whole_filtered_df = metrics_df[metrics_df.frequency > 0] # 훈련/테스트로 분리가 안된 데이터
filtered_df = metrics_cal_df[metrics_cal_df.frequency_cal > 0] # L2 페널티를 최적하기 위해 분리된 데이터L2 penalty를 최적화 하기 위한 지표는 아래와 같습니다.
# (MSE, RMSE ,MAE) 실제값과 예측값의 차이를 계산하는 함수
def score_model(actuals, predicted, metric='mse'):
# make sure metric name is lower case
metric = metric.lower()
# Mean Squared Error and Root Mean Squared Error
if metric=='mse' or metric=='rmse':
val = np.sum(np.square(actuals-predicted))/actuals.shape[0]
if metric=='rmse':
val = np.sqrt(val)
# Mean Absolute Error
elif metric=='mae':
np.sum(np.abs(actuals-predicted))/actuals.shape[0]
else:
val = None
return val
# BG/NBD 모형 평가, (frequency, Recency, T)
def evaluate_bgnbd_model(param):
data = inputs
l2_reg = param
# 모형 적합
model = BetaGeoFitter(penalizer_coef=l2_reg)
model.fit(data['frequency_cal'], data['recency_cal'], data['T_cal'])
# 모형 평가
frequency_actual = data['frequency_holdout']
frequency_predicted = model.predict(data['duration_holdout']
, data['frequency_cal']
, data['recency_cal']
, data['T_cal']
)
mse = score_model(frequency_actual, frequency_predicted, 'mse')
return {'loss': mse, 'status': STATUS_OK}
# Gamma/Gamma 모델 평가 , (Monetary value)
def evaluate_gg_model(param):
data = inputs
l2_reg = param
# GammaGamma 모형 적합
model = GammaGammaFitter(penalizer_coef=l2_reg)
model.fit(data['frequency_cal'], data['monetary_value_cal'])
# 모형 평가
monetary_actual = data['monetary_value_holdout']
monetary_predicted = model.conditional_expected_average_profit(data['frequency_holdout'], data['monetary_value_holdout'])
mse = score_model(monetary_actual, monetary_predicted, 'mse')
# return score and status
return {'loss': mse, 'status': STATUS_OK}
이제 Hyperopt 라이브러리를 사용하여 BG/NBD모델과 Gamma Gamma 각각의 L2 페널티 하이퍼파라미터를 최적화 하는 코드를 적용시켜 봅시다.
from hyperopt import hp, fmin, tpe, rand, SparkTrials, STATUS_OK, space_eval, Trials
search_space = hp.uniform('l2', 0.0, 1.0) # L2 페널티 하이퍼파라미터의 탐색 범위를 정의 ('l2', 0~1 까지의 균등분포)
algo = tpe.suggest
trials = Trials()
inputs = filtered_df
# fmin 함수, l2 페널티 최적화
argmin = fmin(
fn = evaluate_bgnbd_model, # 목적함수 : (evaluate_bgnbd_model) 성능 평가
space = search_space, # 파라미터 공간
algo = algo, # 최적화 알고리즘: Tree of Parzen Estimators (TPE)
max_evals=100, # 반복수
trials=trials
)
l2_bgnbd = space_eval(search_space,argmin)
print(l2_bgnbd)
> 0.9996752974147498
trials = Trials()
# GammaGamma
argmin = fmin(
fn = evaluate_gg_model,
space = search_space,
algo = algo,
max_evals=100,
trials=trials
)
l2_gg = space_eval(search_space,argmin)
print(l2_gg)
> 0.008352758314038453
BG/NBD 의 최적의 L2페널티 값은 0.996752974147498 , Gamma Gamma 의 경우 0.008352758314038453 입니다.
이제 이 해당 값들을 BetaGeoFitter() 과 GammaGammaFitter() 에 넣어주고 피팅하면 됩니다.
BG/NBD, BetaGeoFitter
BetaGeoFitter에 방금 구한l2_bgnbdpenalizer_coef 를 넣어줍니다.
lifetimes_model = BetaGeoFitter(penalizer_coef=l2_bgnbd) #l2_bgnbd = hyperopt로 나온 결과
# calibration 데이터의 R,F,T로 모형 적합
# train = _cal
lifetimes_model.fit(filtered_df['frequency_cal'], filtered_df['recency_cal'], filtered_df['T_cal'])
# holdout 데이터로 모델 평가: F의 실제값과 예측값의 MSE
# test = _holdout
frequency_actual = filtered_df['frequency_holdout']
frequency_predicted = lifetimes_model.predict(filtered_df['duration_holdout']
,filtered_df['frequency_cal']
, filtered_df['recency_cal']
, filtered_df['T_cal'])
mse = score_model(frequency_actual, frequency_predicted, 'mse')
print('MSE: {0}'.format(mse))
> MSE: 3.279920196500393 # 구매일수에 대한 평균제곱오차 +- 3.2 일
+빈도/최근성 매트릭스 시각화
plot_frequency_recency_matrix를 이용하면 구매 빈도와 구매 간격의 조합을 볼 수 있습니다. (BG/NBD) 피팅된 lifetimes_model을 시각화 시켜보면!
# 색상과 밀집도: 그래프의 각 셀은 특정 구매 빈도와 구매 간격의 조합을 나타냅니다.
# 셀의 색상이 진하면서 밀집된 경우, 해당 빈도와 간격의 조합이 많은 고객이 있다는 것을 나타냅니다
from lifetimes.plotting import plot_frequency_recency_matrix
plot_frequency_recency_matrix(lifetimes_model)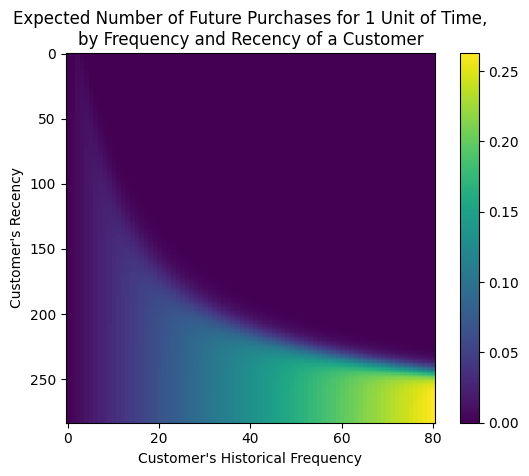
노란영역(bottom-right)의 경우, 최근성도 높고 구매한 횟수도 높은 고객들의 영역입니다. 약 (65,240)정도인 고객들이겠네요. 해당 고객들은 다음에도 구매할 가능성이 높다고 볼 수 있습니다.
또한, 해당 매트릭스에서 왼쪽 상단으로 이어지는 '긴 꼬리' 가 시작되는 부분을 볼 수 있는데요.
매트릭스 결과 기준으로 대략 (20,170) 정도에 해당하는 것 같습니다. 이 고객들은 자주 구매하지 않았지만 비교적 최근에 구매한 고객들입니다.
해당 고객들은 잠재적으로 다시 구매할 수 있지만, 그들이 활발한 고객인지 아니면 구매 간격이 길어져서 그렇게 나타나는 것인지 확실하지 않은 경우라고 해석하는군요.🤔

Gamma Gamma
Gamma Gamma 모델을 적용하기전에 Monetary 와 frequency 가 상관관계를 갖는지 확인해야합니다! 상관계수 0.3 으로 낮은 상관관계를 갖고 있었습니다!
함수
GammaGammaFitter,conditional_expected_average_profit
spend_model = GammaGammaFitter(penalizer_coef=l2_gg) # l2_gg = hyperopt로 나온 결과
spend_model.fit(filtered_df['frequency_cal'], filtered_df['monetary_value_cal'])
# conditional_expected_average_profit: 고객별 평균 구매 금액 예측
monetary_actual = filtered_df['monetary_value_holdout']
monetary_predicted = spend_model.conditional_expected_average_profit(filtered_df['frequency_holdout']
,filtered_df['monetary_value_holdout'])
mse = score_model(monetary_actual, monetary_predicted, 'mse')
print('MSE: {0}'.format(mse))
> MSE: 1256.6393691754843 # +- 1256 예측 금액 차이
만약 l2 penalty를 적용시키지 않았을 경우 예측차이
bins = 100
plt.figure(figsize=(15, 5))
plt.hist(monetary_actual, bins, label='actual', histtype='bar', color='STEELBLUE', rwidth=0.99)
plt.hist(monetary_predicted, bins, label='predict', histtype='step', color='ORANGE', rwidth=0.99)
plt.legend(loc='upper right')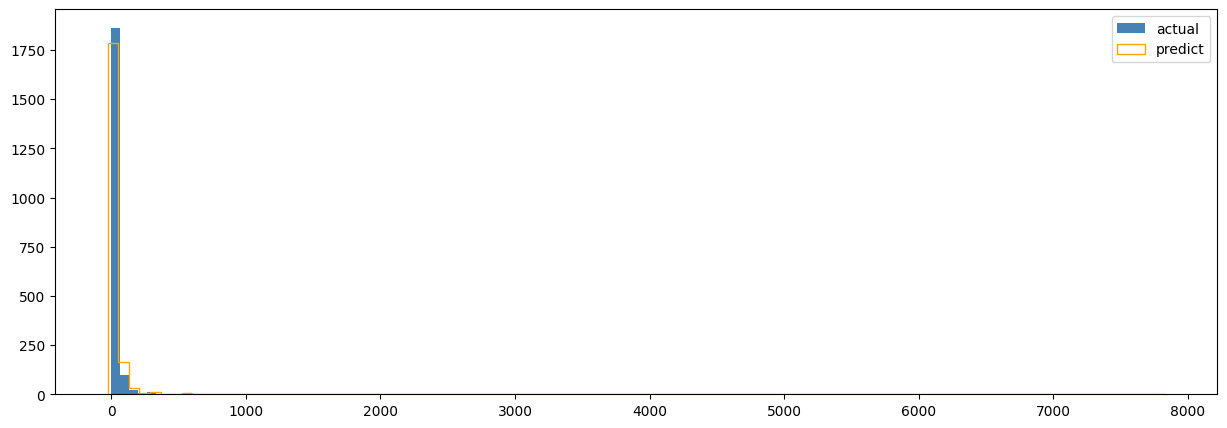
# penalizer_coef 없이 했을 때의 결과
spend_model = GammaGammaFitter(penalizer_coef=0)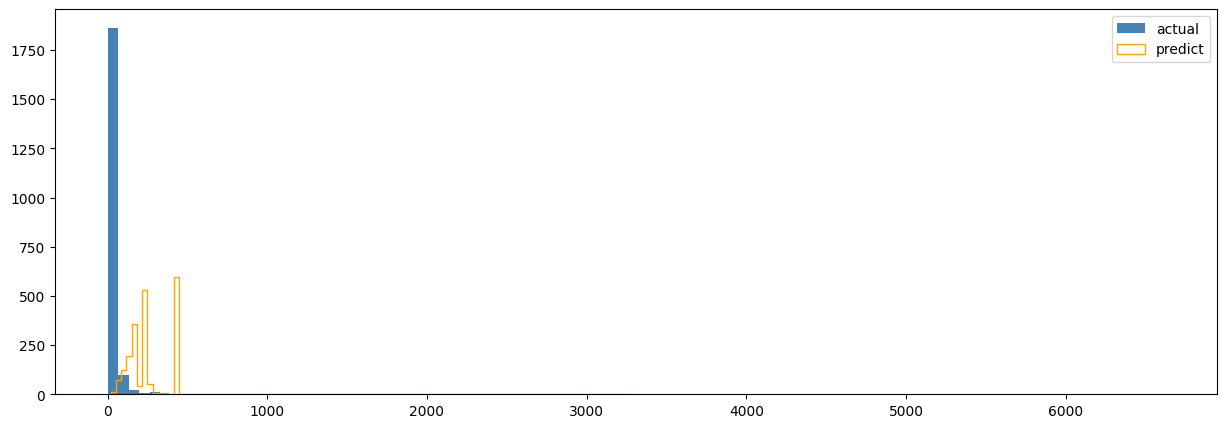
완전 엉뚱하게 예측하는 것을 볼 수 있다..!
LTV 산출하기
final_df = whole_filtered_df.copy() # 전체 데이터 대상
final_df['ltv'] = spend_model.customer_lifetime_value(lifetimes_model,
final_df['frequency'],
final_df['recency'],
final_df['T'],
final_df['monetary_value'],
time=12,
discount_rate=0.01 # monthly discount rate ~12.7% 연간
)NBD 모델 - 예상 구매 횟수
lifetimes_model학습한 NBD 모델conditional_expected_number_of_purchases_up_to_timet 시점까지의 예상 구매 일수 계산- t 기간은 정할 수 있습니다. ( 1년 동안의 예상 구매 횟수를 구해보겠습니다.)
t = 365 # 기간은 정할 수 있다
final_df['predicted_purchases'] = lifetimes_model.conditional_expected_number_of_purchases_up_to_time(t
, final_df['frequency']
, final_df['recency']
, final_df['T'])
gamma gamma 모델 - 예상 평균 구매 금액
spend_model학습된 gamma 모델conditional_expected_average_profit예상 평균 구매 금액 계산
final_df['predicted_monetary_value'] = spend_model.conditional_expected_average_profit(final_df['frequency']
,final_df['monetary_value'])
결과
LTV 값이 높은 상위 5명의 고객만 가져와봤습니다.
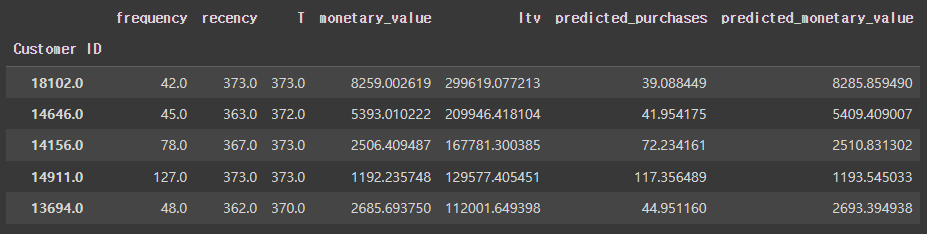
- Customer Id 가18102 인 고객의 경우 299619(파운드) 로 가장 높은 LTV 값을 갖는데요! 한국돈으로 5억원 에 해당합니다.
- 해당 고객의 평균 구매 금액은 8259파운드 (= 약13,700,000원)으로 다른 고객들 보다 매우 높습니다.
- 또한 recency 와 T 가 같다는건 집계되는 날짜에도 물건을 구입한 고객입니다. 가장 최근에 구입하셨네요.
만약 모델을 이용하지 않고 단순히 frequency 와 해당 고객의 Monetary_value를 곱해서 내년동안 사용할 금액을 예측한다면 8259(파운드) * 42 = 5억7천만원 이라 할 수 있지만! 해당 모델을 이용하므로써 해당 고객의 LTV 값을 좀 더 보수적으로 볼 수 있는것 같습니다!
느낀점👀
이렇게 산출된 LTV 값으로 해당 비즈니스에서 고객 기반이 탄탄하게 유지되고 있는지 확인할 수 있는 좋은 지표라고 느꼈습니다. 아주 극단적인 예시로 서비스를 운영하는데 마케팅, 광고비등 고객들을 유지하는 비용이 1,000,000원이고 이에 비해 고객들의 평균 LTV가 2,000,000원 이상으로 예측 된다면 아주 잘하고 있다는 것이겠죠!
데이터가 더 있다면 해당 비즈니스에서 애착을 갖고 있는 고객들의 특징도 찾을 수 있으며
LTV 값을 기준으로 해당 고객들을 세그먼트를 나눠서 새로운 마케팅을 시행할때 참고 해도 좋을 것 같은 생각이 들었습니다.
또 중간에 매트릭스에서 tail 부분에 있는 고객들을 특징을 찾아 확실하게 잡으려면 어떻게 해야할지 생각도 들었구요!
LTV가 높은 고객들과 낮은 고객들에게 다른 마케팅 예산으로 다르게 접근해서 가치가 높은 고객들에게 더 많은 마케팅 예산을 사용하여 이탈율을 줄이는 방법 등등..! 산출된 LTV로 활용할 수 있는 점이 굉장히 많을거 같습니다🤔
비록 잘 정리된 글을 따라 실습해봤지만 lifestyle 이라는 패키지도 알게 되었고, 실제로 회사에서 어떻게 활용하고 있는지 직접 따라해볼 수 있어서 너무 좋았습니다..헤헤
