저번 넥슨 인텔리전스랩스 Uplift Modeling 포스팅에 이어서 간단한 데이터로 실습을 해보려고 합니다!!
DATA
Kaggle 의 Marketing Promotion Campaign Uplift Modelling 데이터를 이용했습니다!
🤤story
" 저희는 이제부터 고객들을 구매시키기 위한 광고/마케팅을 진행해야합니다! "
고객들의 구매를 위해서 제안하려고하는 이벤트는가 총 두개 있는데요! 바로 "BOGO(원플러스원)" 과 "Discount(할인)" 쿠폰을 제안해드리려고 합니다!! (넥슨에서는 A아이템 지급 )
이제부터 위 캠페인을 진행할건데, 어떻게해야 광고비를 절약하면서 고객들의 구매효율을 뽑을 수 있을지 uplift model 흐름을 따라서 진행해봅시다!!
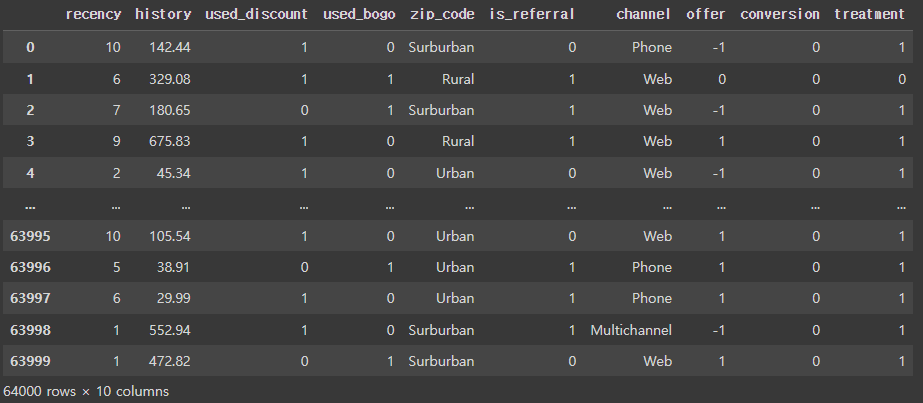
data info
데이터 변수를 잠깐 설명하자면
- recency : 마지막 구매 후 몇개월이 지났는지
- history: 과거 구매후 몇일이 지났는지
- used_discount: 과거에 할인 사용 여부
- used_bogo: 과거에 원플원 사용 했는지 여부
- zip_code: Suburban/Urban/Rural과 같은 우편번호 클래스
- is_referral: 추천 채널에서 고객을 획득했는지 여부
- channel: 고객이 사용하는 채널(Phone/Web/Multichannel)
- offer : 고객에게 전송된 제안(마케팅/광고), Discount/Buy One Get One(원플러스원)/No Offer
- conversation(전환) : 고객이 전환 했는지 여부를 나타냅니다. (구매)
간단한 EDA
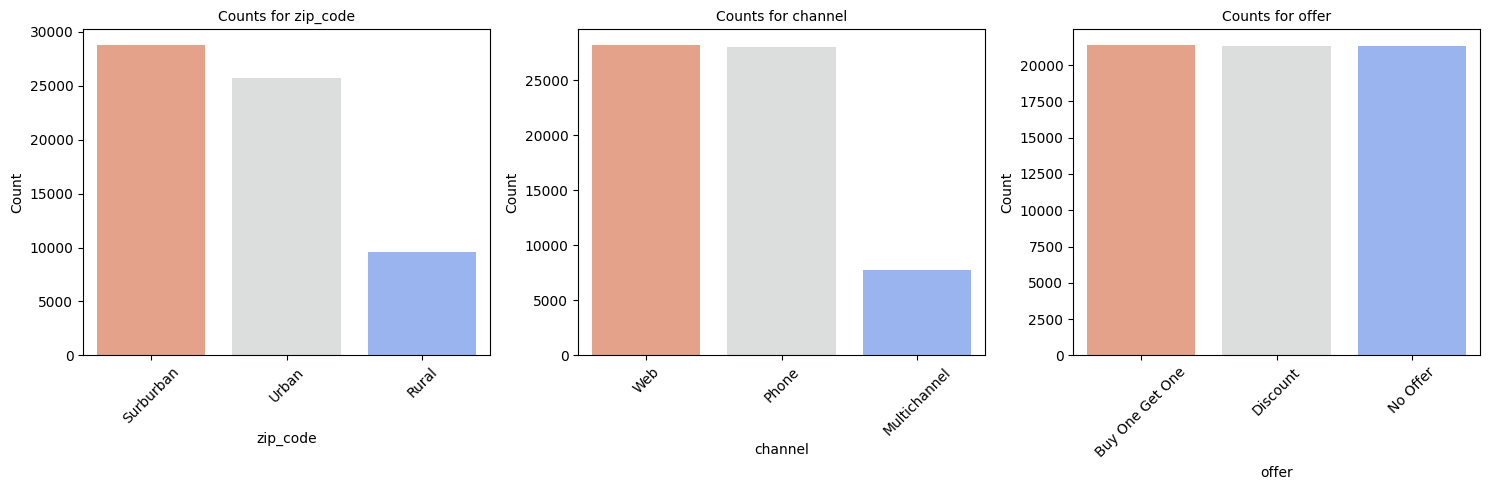
위 이커머스사를 통해 물건을 구입하고 있는 기본적인 고객들의 설명변수들입니다. 간단하게 확인해보겠습니다.
총 640000 개 데이터, 결측값은 없었습니다.
- 명목형 변수들의 value
def plot_object_columns(df):
object_columns = df.select_dtypes(include=['object']).columns # select_dtypes 로 원하는 타입을 갖는 컬럼을 가져올 수 있다.
for col in object_columns:
plt.figure(figsize=(5, 5))
ax = sns.countplot(x=col, data=df, palette="coolwarm_r", order=df[col].value_counts().index)
plt.title(f'Counts for {col}', fontsize=10)
plt.show()
print(df[col].value_counts() / len(df) * 100)
- 도시, 근교 지역의 고객들이 85%
- 웹, 핸드폰으로 이용하는 고객들이 87%
- offer 제안의 경우 원플러스원, 할인, No Offer 각각 1:1:1 비율로 진행 되었습니다.
일부 전처리
✔️ 데이터설명에는 찾지 못했지만 offer 을 받은 경우 treatment , 받지 않은경우 Control 집단으로 이해했습니다. 보기좋게 treatment 컬럼을 따로 만들어 줍시다.
df['treatment'] = 0
df.loc[df['offer'].isin(['Buy One Get One', 'Discount']), 'treatment'] = 1
df.offer = df.offer.map({'No Offer': 0, 'Buy One Get One': -1, 'Discount': 1}) # 0 인경우 control, -1,1 인경우 Treatment
테스트 캠페인 진행 !
업리프팅 모델을 진행하기전, 해당 캠페인이 전환율(구매)에 효과가있는지 확인해봐야합니다. 광고 집행 상황을 아래와 같이 가정해보겠습니다!
- 광고 대상 : 서비스 이탈 유저
- 광고 목적 : 서비스 이용(구매)
- 광고 유형 : BOGO, DISCOUNT
- 오디언스 규모 : BOGO(42693), DISCOUNT(42613)
- 1인당 광고비 : 100원
- 1인당 복귀 기대 수익 = 2500원
df_bogo = df.copy().loc[df.offer <=0].reset_index(drop=True)
df_discount = df.copy().loc[df.offer >= 0 ].reset_index(drop=True)
df_treat_bogo = df_bogo.groupby(['treatment']).agg({'conversion':['mean','sum','count']})
df_treat_discount = df_discount.groupby(['treatment']).agg({'conversion':['mean','sum','count']})
# BOGO #DISCOUNT
conversion conversion
mean sum count mean sum count
treatment treatment
0 0.106167 2262 21306 0 0.106167 2262 21306
1 0.151400 3238 21387 1 0.182757 3894 21307
캠페인을 진행한 결과 전환율 변화
- BOGO의 경우 진행하지 않은 오디언스보다 약 5% 증가
- DISCOUNT의 경우 진행하지 않은 오디언스보다 약 8% 증가
어느정도 해당 캠페인이 효과가 있는것 같습니다!
(proportions_ztest 로 통계적으로 검정결과는 유의미하지는 않았지만🥹 유의미하다고 가정하고 진행해 보겠습니다!)
모델링
캠페인으로 인한 유의미한 구매차이가 확인 되었으니 모델링을 진행할텐데요!
현재 구매를 위한 제안(offer)으로는 BOGO와 DISCOUNT 두개가 있습니다. 일단, DISCOUNT 캠페인을 이용한 데이터만 갖고 진행해보려고합니다.
할인 캠페인 데이터
✔️ 할인 캠페인을 진행한 데이터의 경우 (df_discount) 총 오디언스가 42613 명입니다. (실험군 대조군 5:5 비율입니다.)
# object encoding
df_model = pd.get_dummies(df)
# 원플원 제안과 할인제안을 나누자
df_bogo = df_model.copy().loc[df_model.offer <=0].reset_index(drop=True) # 원플원 광고를 받은 실험군과 대조군 DATA
df_discount = df_model.copy().loc[df_model.offer >=0].reset_index(drop=True) # 할인 광고를 받은 실험군과 대조군 DATA
# 할인율 광고 기준 DATA
train, test = train_test_split(df_discount, test_size=0.2, random_state=42, stratify = df_discount['treatment'])
# 주어진 피처 리스트
features = ['recency','history','used_discount','used_bogo','is_referral','zip_code_Rural','zip_code_Surburban','zip_code_Urban','channel_Multichannel','channel_Phone' ,'channel_Web']
# 피처 및 타겟을 설정하고 데이터를 분할
X = train[features] # train 데이터프레임을 사용하여 피처 추출
y = train['conversion'] # 전환여부 = target
treatment = train['treatment'] # 실험군과 대조군 구분
# 데이터 분할
X_train, X_val, y_train, y_val, treat_train, treat_val = train_test_split(
X, y, treatment, test_size=0.2, random_state=42
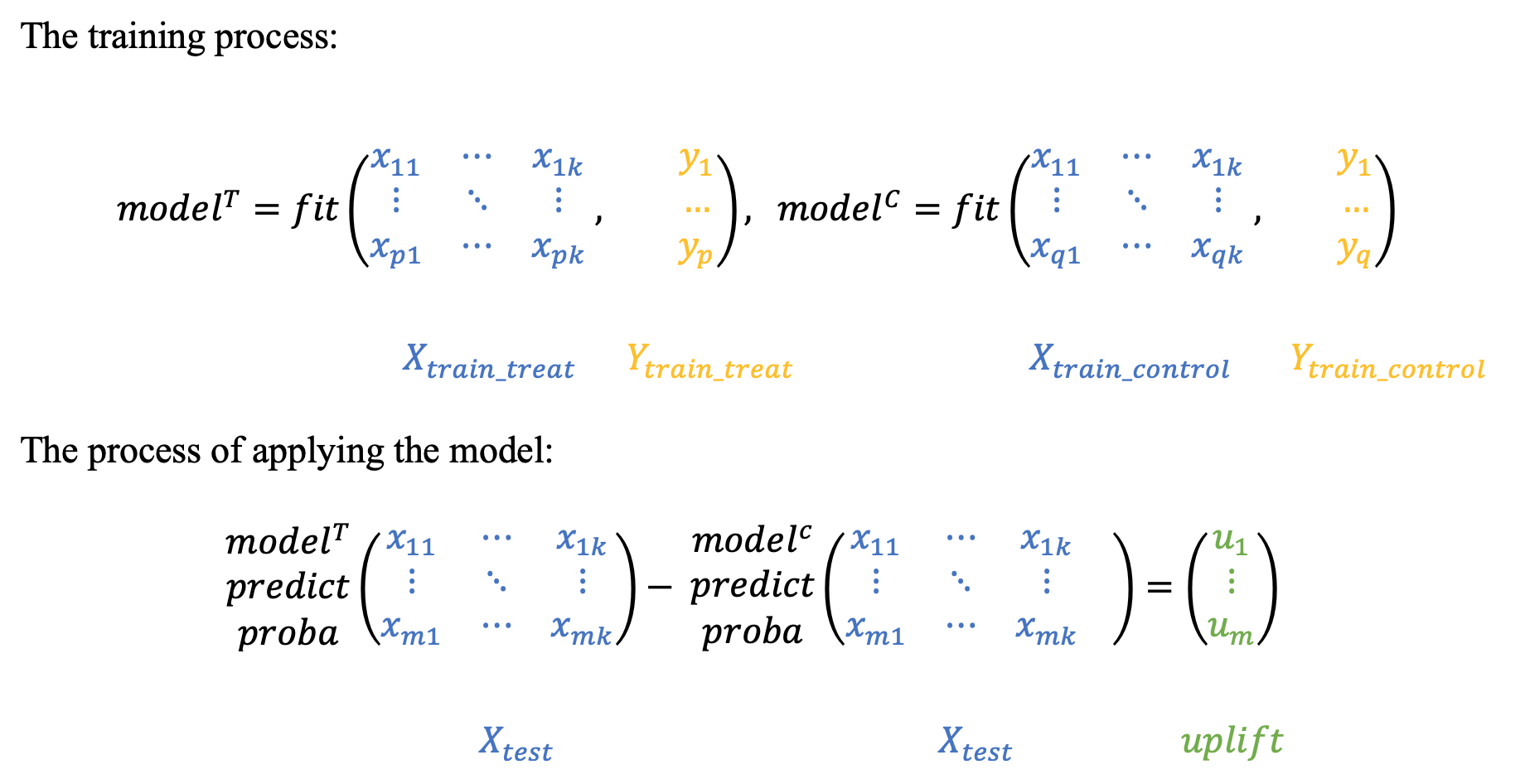
)Two independent models
전 포스팅에서 소개한 Approaches with two models를 이용해보려고합니다. 자세한 설명은 첫 포스팅에 있으므로 생략하겠습니다!
필요 패키지
!pip install scikit-uplift
lightgbm 파라미터들을 따로 건들이지 않고 , 기본적인 baseline 코드로 two models를 이용해보았습니다. 대조군과 실험군 각각에 모델을 적용시켜서 구한 두 score의 차이가 uplifting score가 됩니다. plot_uplift_preds()를 이용하여 score 분포가 어떤지 시각화가 가능합니다.
import lightgbm as lgb
from sklift.models import TwoModels
from sklift.viz import plot_uplift_preds
lgb_params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'metric': 'binary_logloss'
}
# TwoModels 모델 설정
tm = TwoModels(
estimator_trmnt=lgb.LGBMClassifier(**lgb_params),
estimator_ctrl=lgb.LGBMClassifier(**lgb_params),
method='vanilla'
)
# 3. 모델 학습
tm = tm.fit(
X_train, y_train, treat_train
)
# 4. 업리프팅 예측
uplift_tm = tm.predict(X_val)
# 5. 업리프팅 시각화
plot_uplift_preds(trmnt_preds=tm.trmnt_preds_, ctrl_preds=tm.ctrl_preds_);
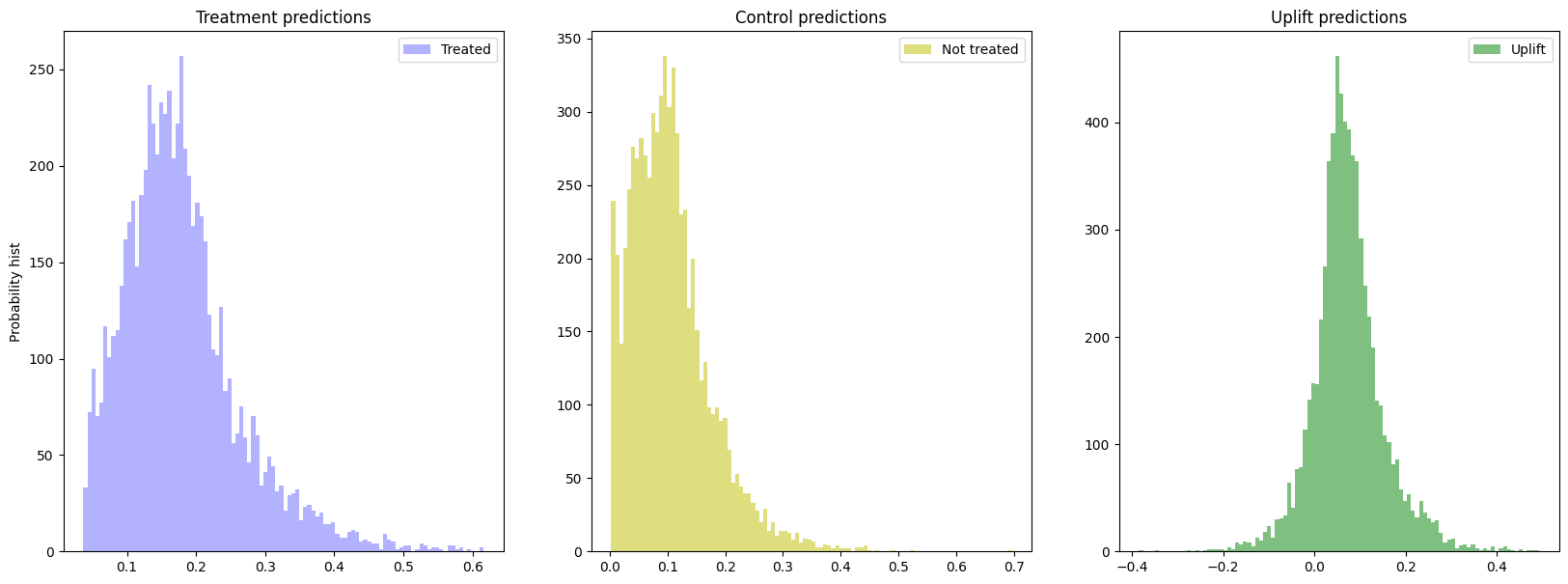
test score 결과
plot_uplift_preds 의 결과를 보면 왼쪽의 treatment(실험군)의 score , 가운데 Control(대조군)의 score, 그리고 그 차이를 구한 uplift score 의 결과를 보실 수 있습니다!
Uplift score 의경우 1로 가까울수록 해당광고에 반응할 고객, 즉 Pesuadables 고객이라고 볼 수 있습니다! 반면에 -1에 가까울 수록 해당 광고를 피해야 할 고객이죠.
완전히 오른쪽으로 치우쳐진 그래프는 아니었지만 87%가 0.0 이상의 값을 갖고 있습니다!
Uplift score
해당 모델을 전체 df_discount 에 적용시켜보면 다음과 같습니다
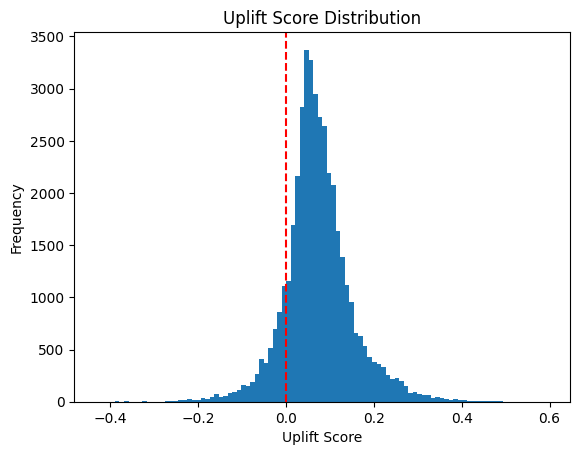
그런데 score를 어떤 기준으로 세그먼트를 어떻게 나눠야하지?
✔️ skewness 는 높지 않지만 약 87% 유저의 score가 0.0 이상을 기록했습니다.
업리프팅 사분면에 따라 고객을 나눠야하는데, 어떤 기준으로 나눠야할까..?
score 가 높을 수록 Persuadables 고객으로 봐야하는데 그 높다는 기준을 어디로 잡아야 하는지 어려웠습니다.😅 (하지만 확실한건 해당 광고시 부정적인 영향을 끼칠 세그먼트는 확실히 나눌 수 있다는것이죠.)
그래도 일단 아래의 기준으로 나눠보도록 했습니다!
def segment_customers(score):
if score >= 0 and score < 0.1:
return "Sure Things"
elif score >= 0.1:
return "Persuadables"
elif score >= -0.1 and score < 0:
return "Lost Causes"
else:
return "Sleeping dogs"uplift score를 기준으로 42613명의 오디언스를 아래와 같이 네 개의 세그먼트로 구분한 결과 입니다.
| 오디언스규모 | |
|---|---|
| Sure Things | 24450 |
| Persuadables | 12787 |
| Lost Causes | 4614 |
| Sleeping dogs | 762 |
앞 포스팅에서 설명한 분류 이론에 따르면, 앞서 진행한 할인 캠페인 오디언스 중 광고 증대효과가 큰 고객들은 Persuadables 고객들 인데요!
- 만약 전체 고객들을 타겟해서 광고를 했을 시
100 * 42613 = 4,261,300 원 Persuadables고객들만 타겟해서 광고를 했을 시
100 * 12787 = 1,278,700 원
결과
- 모든 고객들에게 광고비를 쓰지 않고, 광고 증대효과가 클거라고 예측된 고객들에게만 사용시, 약 70%, 2,982,600원 절감할 수 있습니다.
- 해당 캠페인을 특히 피해서 진행해야하는 고객들의 경우 5,376 명입니다! 위 고객들만 제외해서 캠페인을 진행 시켜도 537,600원 절감할 수 있습니다.
전환성과를 제대로 집계할 수 없어서 실제 광고 효율은 측정하지 못했지만 Uplift model 흐름을 직접 타보면서 실제로 고객들의 세그먼트를 나눠보는 것에 의미가 있었던 것 같습니다ㅎㅎ😌
참고자료
