들어가는 글🙋♀️
많은 데이터를 다루는 서비스 개발을 한다면, 현대적으로는 페이지네이션이란 기능을 자연스럽게 개발해볼 수 밖에 없다. 기본적인 페이지네이션부터 응용을 해볼만한 페이지네이션 관련 기능을 해결한 사례를 들어보고자 한다.
Pagination이란?📃
정의
일반적으로 Pagination(페이지네이션)이라 함은, 수많은 데이터를 일정 기준으로 정렬한 후 특정 개수만큼 나눠 보여주는 것이다. 이 때 특정 개수만큼 나뉜 하나의 덩어리들을 '페이지'라고 칭하기 때문에 페이지네이션이라고 부른다. 페이지네이션이 적용된 사례는 일반적으론 게시판 형태의 레이아웃이나 자동 스크롤 기능 등이 있다.
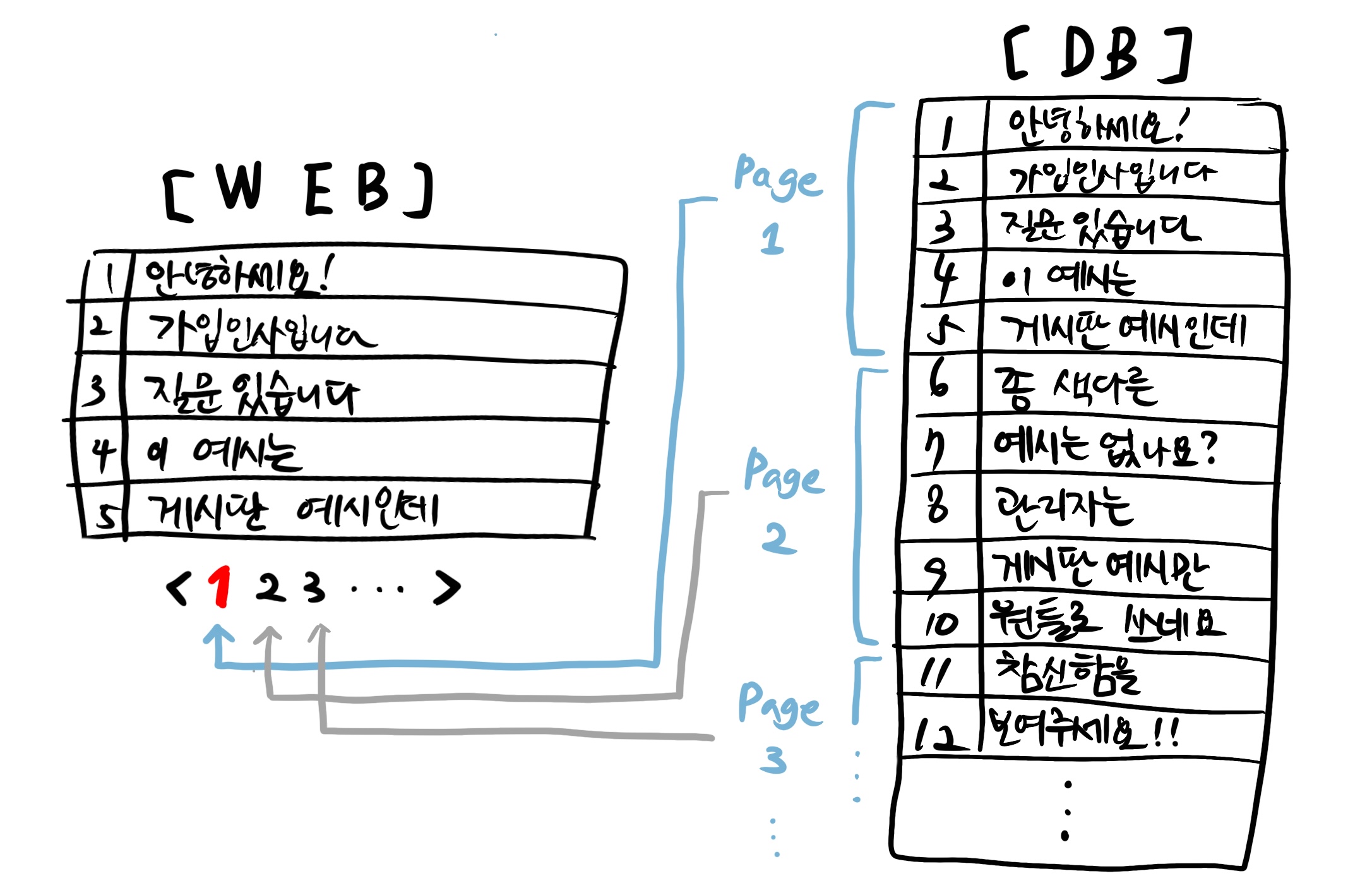
백엔드 엔지니어에게 '페이지네이션이 가능한 게시글 리스트를 불러오는 API를 만들어주세요'라는 요청을 하는 경우가 매우 흔하다. 그리고 이를 해결하기 위해서는 orm을 통한 쿼리를 쓰는 것이 일반적이다.
페이지네이션 기능에 대한 쿼리
필자는 지금까지는 페이지네이션을 해결하기 위해 다음의 쿼리를 이용했다.
select * from boards
limit 5 -- page의 사이즈
offset 10 -- (page 번호 - 1) * page 사이즈limit 과 offset을 이용하면 전통적으로는 페이지네이션을 할 수 있다. 이를 Flask와 SQLAlchemy 스펙의 API로 쓴다면 다음과 같은 페이지네이션 기능을 품은 API를 작성할 수 있다.
@app.route("/api/boards")
def get_boards(page, page_size):
offset_num = (page - 1) * page_size
boards = (
Board.query
.limit(page_size)
.offset(offset_num)
.all()
)
return [
board._asdict()
for board in boards
]이번 블로그 글을 쓰면서 자료 조사 하는 과정에서, offset을 사용하지 말자! 라는 의견이 있는데 이는 꽤 합리적인 내용이라 생각했다. 다만 해당 글의 주제와는 조금 멀어서 추후에 좀 더 공부해보고 다시 정리하고자 한다. 참고할 블로그 👉 https://binux.tistory.com/148
위의 예제에, 정렬 기능이나 검색 기능까지 들어간다고 하면 데이터의 리스트를 가져오는 일반적인 API를 구현할 수 있다.
자동 페이징 기능?🤔
기능적 정의
그러다가 필자는 어느날 이런 요청을 기획자로부터 요청 받았다.
어떤 게시글이 속해있는 '페이지 번호'를 자동으로 찾아주는 기능을 추가해주세요!
이 얘기를 개발자의 시점으로 고치자면 다음과 같았다.
게시글의 id 값으로 페이지 번호를 역으로 계산해서 주세요.
처음에 얘기를 들었을 땐, '음? 생소하고 어려운 기능인데? 가능은 한가..?' 생각하였다. 그렇지만 기능적으로 꼭! 필요하다고 하니 기술적으로 해결해볼 수 있는지 확인하였다.
쿼리를 먼저 작성해보자
Postgresql에서 먼저 쿼리를 작성했다. 이 때 각 id의 페이지를 찾을 수 있는 쿼리를 작성했다.
select
b.id,
(row_number() over() - 1) / 10 + 1 as "page_num" -- 여기서 나눈 10이 page_size
from
board b
order by
b.idpage_num을 구하는 로직은 다음의 생각 흐름으로 계산했다고 볼 수 있다.
ROW_NUMBER() OVER (): 현재 행의 순서를 부여하는 함수이다. 여기서는 모든 행에 대해 순서를 매기기 위해 사용한다.- 1: 첫 번째 행의 순서를 0으로 만들기 위해 1을 뺀다./ 10: 각 행의 순서를 page_size(여기서는 10)으로 나누어 몫을 구한다. 이렇게 하면 10개의 행마다 같은 값을 가지게 된다.
간단한 예제를 이용해서 다음의 결과를 확인해보자.
boards라는 테이블 안에 약 100개의 데이터가 존재한다. id 순으로 정렬하였을 때, pagination 기능에 한해 각 행이 속할 page 번호를 반환하는 쿼리를 만들어보자.
select
b.id,
b.name,
row_number() over() as "row_number_over",
(row_number() over() - 1) / 10 as "minus_1_and_devide_10",
(row_number() over() - 1) / 10 + 1 as "page"
from
board b
order by
b.id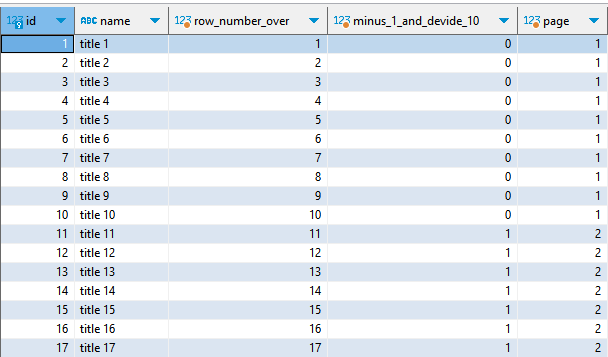
위의 테이블에서 name에 '1'이 속하지 않은 경우는 어떻게 해야 하나?
select
b.id,
b.name,
row_number() over() as "row_number_over",
(row_number() over() - 1) / 10 as "minus_1_and_devide_10",
(row_number() over() - 1) / 10 + 1 as "page"
from
board b
where
b.name not like '%1%'
order by
b.id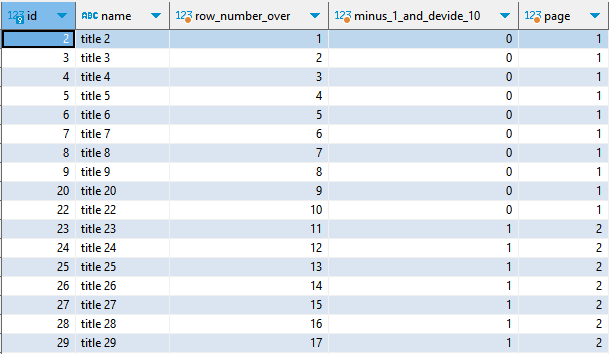
- 제목에 1이 들어간 경우는 제외하고도, 페이지네이션을 하면서 각 콘텐츠가 속할 페이지의 번호까지 찾을 수 있다.
이제 여기에서 해당 콘텐츠 id를 받아 where을 걸어주면, 해당 콘텐츠의 page 번호를 얻을 수 있다.
💡 주의할 점
이 때, 위의 쿼리를 subquery로 하여 where id = {id}를 걸어줘야 한다. 만약 위 예제의 where에 포함하게 되면, page 계산에 사용되기 때문에 원하는 page 번호가 나오지 않는다.
select
*
from
(
select
b.id,
b.name,
(row_number() over() - 1) / 10 + 1 as "page"
from
board b
order by
b.id
) A -- subquery를 이용해야 한다
where
A.id = 22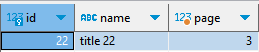
속도 이슈는 없을까?
이 기능 개발할 때 가장 크게 걱정 했던 것은 속도였다. 그 이유는 "row_number() over() 구문에 의해 데이터 개수가 늘어나면 당연히 계산 속도가 느려지지 않을까" 싶었기 때문이다. 100만 개 데이터가 있을 땐, 각 데이터의 row의 행 순서를 계산하기 시간이 최소한으로 생각해도 O(n)으로 늘어날 것이라 생각했기 때문이다. 그래서 데이터를 넣어가며 확인하였다.
속도 측정해보자!
EXPLATIN ANALYZE 구문을 이용하면 쿼리의 실행 계획과 각 구간 별로 얼마나 시간이 걸리는지 확인할 수 있다.
위에서 썼던 쿼리를 다시 가져왔다. 단 EXPLATIN ANALYZE 구문도 포함하였다.
EXPLAIN ANALYZE
select
*
from
(
select
B.id,
B.name,
(row_number() over() - 1) / 10 + 1 as "page"
from
board B
order by
B.id
) A
where
A.id = 100그리고 100개의 데이터만 있는 경우와 100만개의 데이터가 있는 경우의 쿼리 실행 계획 및 execution time은 다음과 같다.
- board 테이블에 100개의 데이터가 있는 경우

- board 테이블에 100만개의 데이터가 있는 경우

데이터가 10000배 늘었을 때 실행 시간이 약 5560배가 늘어난 것을 확인할 수 있었다. 실제로 100만개의 row의 경우에는 쿼리 시간만 0.5초 걸려 약간의 delay가 발생함을 느낄 수 있었다. 서버 API 핸들러 단에서 그 외의 로직이 추가된 경우라면 API 호출 자체가 꽤 느려질 수 있음을 확인했다.
어떻게 해결해야 할까?
1안) subquery에 limit절을 추가한다.
위의 경우는 subquery에서 페이지를 계산하기 전에 행 순서를 계산하는 시간을 줄이기 위해 limit절을 사용한다는 것이다.
EXPLAIN ANALYZE
select
*
from
(
select
B.id,
B.name,
(row_number() over() - 1) / 10 + 1 as "page"
from
board B
order by
B.id
limit :target_id -- 이곳이 추가가 된다. 여기서 target_id는 변수로 사용
) A
where
A.id = :target_id -- target_id를 변수로이렇게 하면 100번 데이터의 페이지를 가져오는 것은 약 0.002초 대로 다시 줄어든다. 그러나 근본적인 해결책이 못된다. 100만번 데이터의 페이지를 가져오는 것은 여전히 약 0.4초 대로 늘어난다.
2안) 전체 데이터를 모두 가져온 후 binary search로 데이터를 찾는다.
이 생각을 한 이유는, 전체 데이터를 가져오는 것이 row_number() over()보다 빠를 것이고, 이에 binary search를 이용하면 시간 복잡도도 O(log n)으로 줄일 수 있을 것이라 예상했다.
EXPLAIN ANALYZE
select * from board 
- 위 쿼리는 100만행 데이터의 테이블 전체를 가져온다.
row_number() over()를 사용하는 것보다 훨씬 빠르다.
def binary_search_row_number(target_id, boards):
# 해당 id가 전체 데이터에서 몇 번째에 있는지 계산하기 위해 binary search로 찾는다.
board_idx_dict = {
board.id: row_number
for row_number, board in enumerate(boards)
}
low = 0
high = TOTAL_NUMBER
target_index = high // 2
while low < high:
target_index = board_idx_dict.get(target_id)
if target_index is None:
break
if target_index > now_index:
low = now_index
elif target_index < now_index:
high = now_index
else: # target_index == now_index
break
now_index = (high + low) // 2
return target_index
@app.route("/api/boards")
def get_boards(page, page_size, target_id=None):
# 자동으로 페이지를 계산하기 위해 여기를 추가 ===========
if target_id is not None:
# 예제는 전체 데이터를 가져왔지만, 정렬 / 필터 등이 들어가면 id가 곧 행 순서 번호가 되지 않을 수 있다.
total_boards = Board.query.all()
auto_page = (binary_search_row_number(target_id) - 1) / page_size + 1
if auto_page:
page = auto_page
# ================================================
offset_num = (page - 1) * page_size
boards = (
Board.query
.limit(page_size)
.offset(offset_num)
.all()
)
return [
board._asdict()
for board in boards
]- binary search 수행 시간은 확연히 줄어들기 때문에 더 빨라질 수 있다.
- 이 때는 데이터의 크기에 따라 메모리가 더 많이 들 수 있다.(전체 데이터를 불러오는 곳에 의해) 메모리가 작은 서버의 경우에는 좀 더 고려해봐야 한다.
마치며🤗
실무를 하다 보면 기본적인 기능에 추가 응용할 경우가 생긴다. 이럴 때는 쿼리로 해결하는 방법을 취할 수도 있지만 적절한 수준에서 쿼리와 BE 코드 단에서 해결이 가능한지도 파악해본다. 물론 절대적으로 옳은 방법은 없지만 better things는 분명 있을 것이다.
이번 글은 아직 해결하지 못한 부분이었는데(데이터가 아직은 적은 상태라 큰 문제는 없다), 보다 고민해보고 개선점을 찾는 데에 스스로도 고민해보고 공부하는 계기가 되어 더 좋았던 것 같다. 추후에 제대로 적용해보도록 해야겠다.
