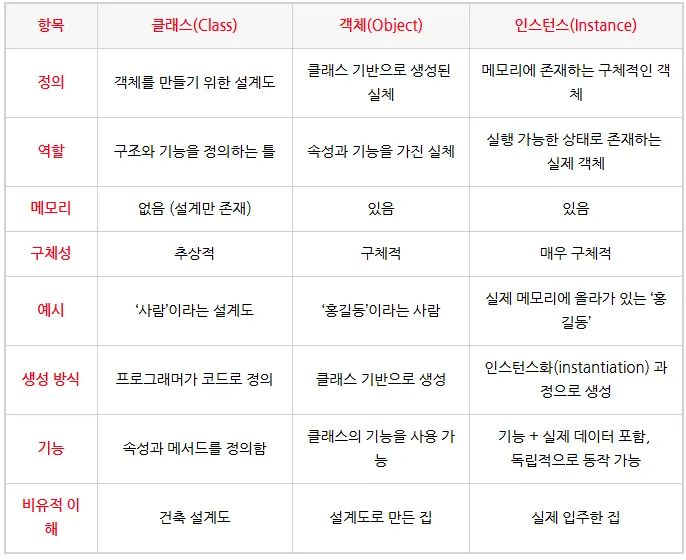
[Java] Object & Class

객체(Object)와 클래스(Class)
클래스(Class)
객체를 만들기 위한 설계도
- 필드(상태, 속성) + 메서드(행동) 정의
- JVM 관점에서 클래스 정보는 Method Area(=Metaspace) 쪽에 로드됨(구현체마다 용어 차이 있음)
객체(Object, instance)
클래스로부터 만들어진 실체
new로 생성되며 일반적으로 Heap에 생김- 변수는 객체 자체가 아니라 객체를 가리키는 참조(reference) 를 들고 있음
Panda p = new Panda();p: 스택에 있는 참조값new Panda(): 힙에 있는 객체
주의
- ❌
p가 객체다 - ⭕
p는 객체를 가리키는 리모컨(참조) 이다
값(Value)과 참조(Reference)
Primitive(기본 타입)
int, long, double, boolean ...- 변수에 값 자체가 들어감
- 대입/파라미터 전달 시 값 복사
int a = 10;
int b = a;// b는 10 (완전 독립)
b = 20;a는 여전히 10
Reference(참조 타입)
String, 배열, 모든 클래스 인스턴스 등- 변수에 주소(참조값) 가 들어감
- 대입/파라미터 전달 시 참조값 복사 (같은 객체를 가리키게 됨)
Panda p1 = new Panda();
Panda p2 = p1;// 참조값 복사p1과 p2는 두 객체가 아니라 한 객체를 같이 참조.
복사(Copy)의 본질
- Primitive: 값 복사 = 안전하고 독립
- Reference: 참조 복사 = 공유(별칭, aliasing) 발생 → 변경 영향 전파
→ 얕은/깊은 복사로 이어짐
Call By Value vs Call By Reference (Java)
Java는 무조건 Call By Value
왜 사람들이 참조 전달이라고 착각하나?
- 참조 타입을 넘길 때도 값을 넘기는데,
- 그 값이 객체 주소(참조값)라서 바깥 객체가 바뀌는 것처럼 보임.
필드 변경은 반영됨 (참조값이 같으니까)
void rename(Panda p) {
p.name = "철수";
}
Panda panda = new Panda("영희");
rename(panda);
System.out.println(panda.name);// 철수p는panda와 같은 객체를 가리키는 참조값을 복사받았음- 객체 내부 상태 변경 → 바깥에서도 보임
참조를 새 객체로 바꿔도 바깥은 안 바뀜
void change(Panda p) {
p = new Panda("새 판다");// p가 가리키는 대상을 바꿈
}
Panda panda = new Panda("영희");
change(panda);
System.out.println(panda.name);// 영희 (그대로)핵심
- 참조 자체(주소값)를 복사해서 넘겼기 때문에
- 함수 내부에서
p가 다른 객체를 가리켜도 - 바깥 변수
panda의 참조값은 변하지 않음
Java는 참조 타입도 주소값을 복사하는 Call By Value라서, 내부에서 재할당은 외부에 영향이 없다.
얕은 복사 vs 깊은 복사
얕은 복사(Shallow Copy)
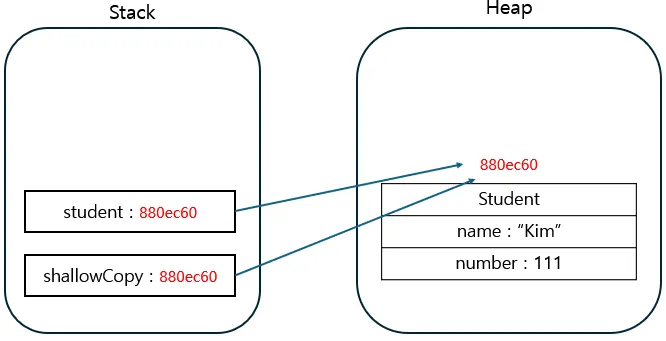
- 겉 껍데기만 복사
- 내부 필드가 참조 타입이면 같은 객체를 공유
Student student = new Student("Kim", 111);
Student shallowCopy = student; // 얕은 복사 (사실상 참조 복사)또는 객체를 새로 만들더라도 내부 참조를 그대로 복사하면 얕은 복사
Student student2 = new Student(student.name, student.number);// 내부 Student 공유위험
- 한쪽에서 내부 객체 수정하면 다른 쪽도 영향
깊은 복사(Deep Copy)
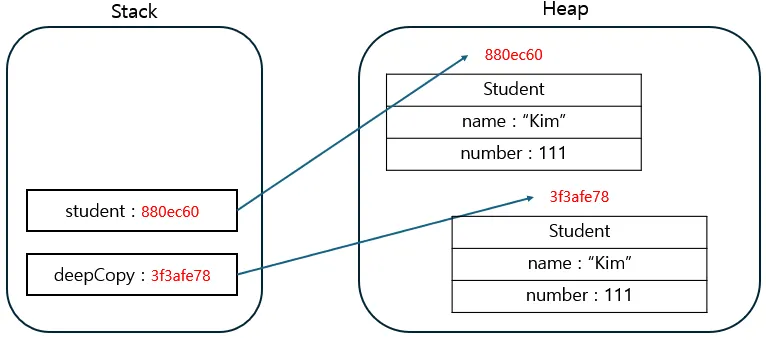
- 내부 객체까지 새로 생성
Cloneable 구현
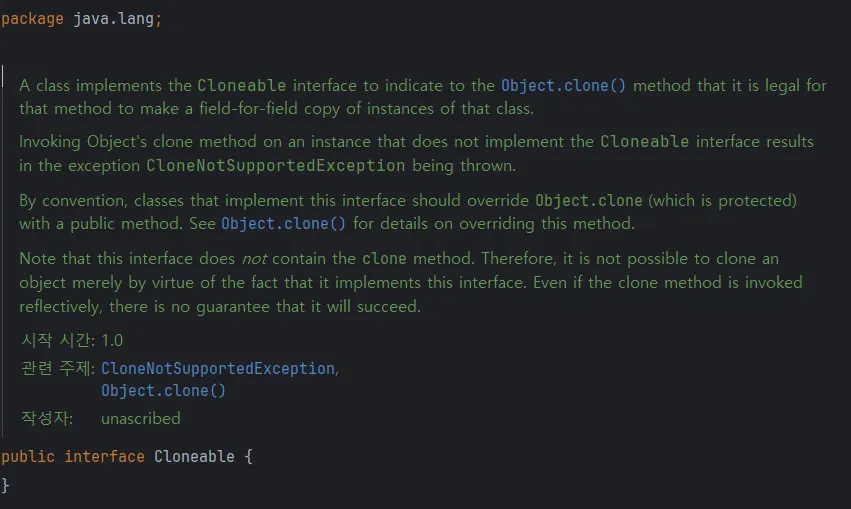
정의된 메서드는 없지만, Object.clone() 메서드를 반드시 구현하라고 설명되어 있음
public class Student implements Cloneable{
String name;
int number;
public Student(String name, int number) {
this.name = name;
this.number = number;
}
@Override
protected Student clone() throws CloneNotSupportedException {
return (Student)super.clone();
}
}복사 생성자 / 복사 팩토리 메서드
public class Student{
String name;
int number;
public Student(){}
//복사 생성자
public Student(Student original){
this.name = original.name;
this.number = original.number;
}
//복사 팩터리 메서드
public static Student copy(Student original){
Student student = new Student();
student.name = original.name;
student.number = original.number;
return student;
}
}불변 객체(Immutable Object)와 final을 사용해야 하는 이유
불변 객체(Immutable Object)
객체 생성 이후 내부 상태가 절대 변하지 않는 객체
특징
- 상태 변경 메서드(setter) 없음
- 내부 상태를 외부로 노출하지 않음
- 참조를 반환해야 할 경우 방어적 복사(defensive copy) 사용
사용 이유
Thread-Safe (동기화 불필요)
멀티스레드 문제의 본질은 공유 자원에 대한 쓰기(write)
- 가변 객체 → 동기화 필요
- 불변 객체 → 읽기만 가능
실패 원자성(Failure Atomicity)
가변 객체의 문제
- 처리 중 예외 발생
- 객체가 중간 상태(inconsistent state)로 남음
- 이후 로직에서 2차 오류 발생
불변 객체의 장점
- 상태 변경 자체가 없음
- 예외 발생 전/후 상태 동일
→ 실패해도 객체는 항상 안전
Cache / Map / Set에 최적
Hash 기반 컬렉션의 핵심 조건
→ equals가 true면 hashCode는 반드시 같아야 한다.
가변 객체를 키로 쓰면
- 내부 상태 변경
- hashCode 변경
- 조회 불가 (논리적 오류)
불변 객체는
- 상태 변경 x
- hashCode 고정
- 캐시 / Map 키로 안전
→ String이 Map 키로 자주 쓰이는 이유
부수 효과(Side Effect) 제거
메서드 호출이 객체 상태를 몰래 변경하는 것
가변 객체 + setter
- 객체 상태 추적 어려움
- 어디서 값이 바뀌었는지 전부 확인 필요
불변 객체
- 상태 변경 불가
- 메서드들은 자연스럽게 순수 함수
- 코드 예측 가능
→ 유지보수성 향상
협업 시 안전성
불변 객체
- 이 객체는 절대 안 바뀐다는 계약 성립
- 다른 사람이 작성한 코드도 의심 없이 사용 가능
가변 객체
- setter 존재 여부 확인
- 호출 체인 전체 추적 필요
→ 불변성은 팀 생산성에 직접적인 영향
GC 성능 향상
GC 설계 가정 중 하나 → 대부분의 객체는 금방 죽는다
value 객체 생성 (불변)
↓
ImmutableHolder 생성
↓
Holder → value 참조Holder가 살아 있으면 value는 처음 상태 그대로 유지
public class MutableHolder {
private Object value;
public Object getValue() { return value; }
public void setValue(Object o) { value = o; }
}
public class ImmutableHolder {
private final Object value;
public ImmutableHolder(Object o) { value = o; }
public Object getValue() { return value; }
}
public void createHolder() {
// 1. Object 타입의 value 객체 생성
final String value = "MangKyu";
// 2. Immutable 생성 및 값 참조
final ImmutableHolder holder = new ImmutableHolder(value);
}GC 입장에서
- 참조 관계 안정적
- Old → Young 참조 감소
- 스캔 비용 감소
MutableHolder의 문제
- 값 변경 가능
- Old → Young 참조 증가
- 카드 테이블 업데이트 증가
→ GC 비용 상승
String / String Pool
String은 불변 객체(Immutable)
String s = "a";
s = s + "b";여기서 "ab"가 만들어질 때:
- 기존
"a"객체가 바뀌는 게 아니라 - 새 String 객체가 생성됨
장점
- thread-safe
- 캐싱/공유 안전
- HashMap key로 안전 (hashCode 캐시 가능)
단점
- 반복 수정 시 객체 폭발 → 성능/GC 부담
String Pool
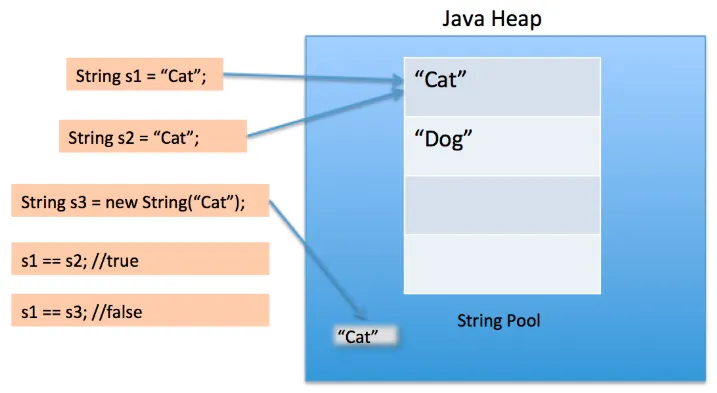
String a = "hi";
String b = "hi";
System.out.println(a == b);// 대부분 true리터럴 "hi"는 String Pool에 들어가고 재사용됨
반면
String c = new String("hi");
System.out.println(a == c);// false
System.out.println(a.equals(c));// true==: 참조 비교equals: 값 비교
intern()
String x = new String("hi").intern();- Pool에 있는 동일 문자열 참조를 반환
StringBuilder vs StringBuffer
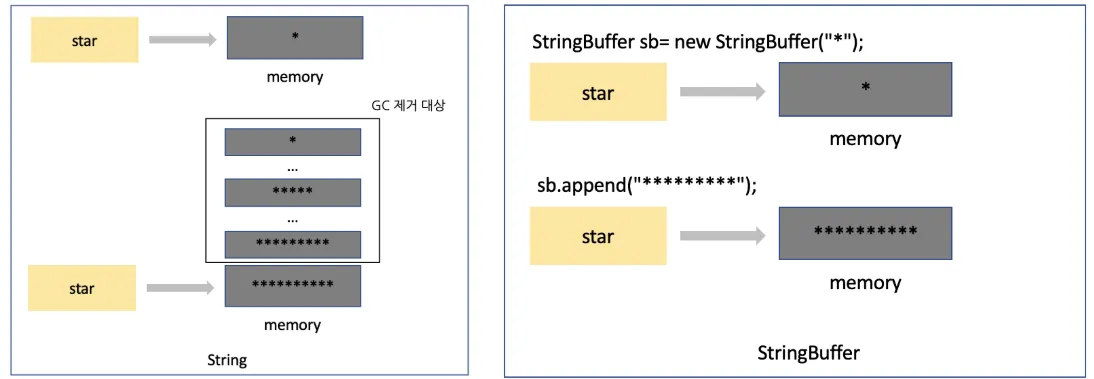
StringBuilder
- 가변(mutable)
- 동기화 없음 → 단일 스레드에서 가장 빠름
StringBuffer
- 메서드에 synchronized 적용 → 멀티스레드에서 안전
- 대신 느림
주의
- 일반적으로
StringBuilder쓰면 됨 - 진짜로 여러 스레드가 같은 버퍼에 append 하는 케이스만
StringBuffer
리플렉션(Reflection) / 어노테이션(Annotation)
리플렉션이란?
- 런타임에 클래스 구조를 들여다보고 조작하는 기능
- 클래스 이름 문자열로 로딩 가능
Class<?> clazz = Class.forName("com.example.Panda");
Object obj = clazz.getDeclaredConstructor().newInstance();어디서 쓰이나?
- Spring DI (컴포넌트 스캔, 빈 생성)
- JPA (엔티티 프록시)
- 테스트 프레임워크
- 직렬화/역직렬화 (Jackson)
단점
- 느릴 수 있음 (일반 호출보다 비용 큼)
- 캡슐화 깨기 쉬움 (private 접근)
- 잘못 쓰면 유지보수 지옥
어노테이션이란?
- 코드에 붙이는 메타데이터
- 컴파일러/런타임 프레임워크가 읽어서 동작
Retention
- SOURCE: 컴파일 후 사라짐
- CLASS: 바이트코드에는 남지만 런타임 접근 불가
- RUNTIME: 런타임 리플렉션으로 접근 가능 (Spring/JPA 대부분)
Target
- METHOD, FIELD, TYPE 등 어디에 붙을지 제한
제네릭(Generic) / 타입 소거(Type Erasure)
제네릭(Generic)

클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법
제네릭 타입 전파

부분에서 실행부에서 타입을 받아와 내부에서 T타입으로 지정한 멤버들에게 전파하여 타입이 구체적으로 설정됨.
→ 구체화(Specialization)
타입 파라미터 기호 네이밍
암묵적 convention
장점
- 컴파일 타임에 타입 검사를 통해 예외 방지
- 불필요한 캐스팅을 없애 성능 향상
주의
- 제네릭 타입의 객체 생성 불가
- static 멤버에 제네릭 타입이 올 수 없음
타입 소거
컴파일러는 제네릭 타입을 이용해서 소스 파일을 체크하고
개발자가 지정한 코드에 따라 필요한 곳에 형변환을 넣어주고
→ 최종적으로 컴파일 코드에 Type Erasure로 제네릭 타입을 제거
왜 이렇게 설계?
- 옛날(제네릭 없던) 바이트코드와 호환을 위해
equals / hashCode
equals
equals()는 두 객체가 논리적으로 같은 값인가를 비교하기 위한 메서드
String a = new String("hi");
String b = new String("hi");
a == b// false (참조 비교)
a.equals(b)// true (값 비교)왜 == 말고 equals를 써야 하나?
==: 주소(참조) 비교equals: 객체의 의미(값) 비교
hashCode란?
hashCode()는 객체를 정수 값으로 요약한 값
주 목적은 Hash 기반 컬렉션의 성능 최적화
예
HashMapHashSet
equals / hashCode 계약
핵심 계약
equals가 true인 두 객체는
반드시 같은 hashCode를 가져야 한다
반대는 아님
(hashCode가 같아도 equals는 false일 수 있음)
HashMap 내부 동작과 연결
map.put(key, value);내부 흐름
key.hashCode()호출 → 버킷 선택- 같은 버킷에 여러 키가 있으면
equals()로 실제 키 비교
만약
- equals만 재정의하고
- hashCode를 재정의 안 하면
→ 같은 키인데 다른 버킷에 들어가서 조회 실패
왜 불변 객체가 HashMap 키로 좋은가?
불변 객체의 특징
- 생성 후 상태 변경 ❌
- hashCode 값이 절대 변하지 않음
가변 객체를 키로 쓰면?
key를 put 한 뒤
→ 내부 필드 변경
→ hashCode 변경
→ map에서 못 찾음HashMap/HashSet 키는 불변 객체가 최선
Wrapper / Auto Boxing
Wrapper 클래스
Primitive 타입을 객체로 감싼 클래스
| primitive | wrapper |
|---|---|
| int | Integer |
| long | Long |
| boolean | Boolean |
Auto Boxing / Unboxing
Integer a = 10;// auto boxing
int b = a;// auto unboxing컴파일러가 자동 변환 코드를 넣어준다.
Integer 캐시 (-128 ~ 127)
Integer a = 100;
Integer b = 100;
a == b// true
Integer c = 1000;
Integer d = 1000;
c == d// false이유
- 자주 쓰는 작은 값은 미리 캐시
- 객체 재사용 → 메모리/성능 최적화
→ 캐시 범위는 JVM 옵션으로 변경 가능
성능 이슈
for (int i = 0; i < 1_000_000; i++) {
Integer x = i;// boxing
}- boxing/unboxing 반복
- 객체 생성 + GC 부담
→ 핫 루프에서는 primitive 사용 권장
