[Operating System] Scheduling & Virtual Memory

CPU Scheduling
CPU 스케줄링이 필요한 이유
- CPU는 한 번에 1개의 프로세스만 실행할 수 있다
- 프로세스는 CPU 작업(CPU Burst) 과 입출력 대기(I/O Burst) 를 반복한다
- 모든 프로세스가 동시에 나도 실행하고 싶다라고 하기 때문에 OS는 공정하고 효율적인 방식으로 CPU를 분배해야 한다.
프로세스 우선순위(Priority)
OS는 다음을 고려해 우선순위를 정한다.
CPU 활용률(CPU Utilization)을 높이고 싶다
CPU가 놀지 않도록 해야 하므로,
입출력 집중 프로세스(I/O-bound) 에 우선순위를 줘서 빨리 I/O를 발생시키게 하면
CPU는 그동안 다른 작업을 수행할 수 있다.
- I/O-bound 프로세스 → 우선순위 높음
- CPU-bound 프로세스 → 우선순위 낮음
스케줄링 큐(Scheduling Queue)
OS는 프로세스들을 다양한 큐에 넣어 관리한다.
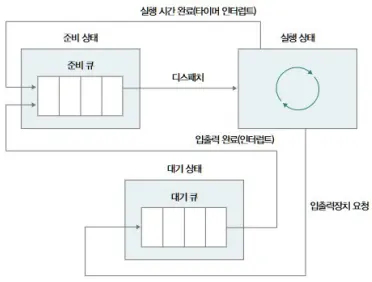
준비 큐(Ready Queue)
- CPU 사용하고 싶습니다!
- CPU가 비면 여기서 하나를 꺼내 실행
대기 큐(Waiting Queue)
- I/O 작업 때문에 기다리는 상태
- 작업이 완료되면 Interrupt를 받고 다시 Ready Queue로 복귀
선점형 vs 비선점형 스케줄링
선점형 스케줄링 (Preemptive)
운영체제가 CPU를 강제로 빼앗아서 다른 프로세스에게 줄 수 있는 방식
예)
- 타이머 인터럽트
- 우선순위가 높은 프로세스 등장
장점
- 공평, 빠른 응답
단점
- 문맥 교환(Context Switch) 오버헤드 증가
비선점형 스케줄링 (Non-preemptive)
프로세스가 스스로 CPU를 포기할 때까지 기다림
- 종료되거나
- I/O 대기 상태로 스스로 가야 CPU가 회수됨
장점
- 오버헤드 낮음
단점
- 독점 위험
전통적 CPU 스케줄링 알고리즘 7가지
FCFS (First Come First Served)
가장 먼저 온 프로세스부터 실행하는 단순한 방식
문제: 호위 효과(Convoy Effect)
긴 작업 하나 때문에 뒤에 온 짧은 작업들이 모두 기다려야 하는 비효율 발생
SJF (Shortest Job First)
실행 시간이 가장 짧은 프로세스를 먼저 실행 (비선점형)
장점
- 평균 대기시간이 최소가 되는 최적 알고리즘
단점
- 다음 CPU Burst 길이를 정확히 예측할 수 없음
Round Robin (RR)
정해진 시간(Time Slice) 만큼만 CPU 사용
시간이 지나면 강제로 다음 프로세스로 교체 (선점형)
장점
- 공평한 CPU 시간 분배
- 응답성이 좋음
단점
- 타임슬라이스가 너무 크면 FCFS처럼 됨
- 너무 작으면 문맥 교환 오버헤드 증가
SRT (Shortest Remaining Time)
SJF의 선점형 버전
현재 실행 중이더라도, 더 짧은 Remaining time을 가진 프로세스가 오면 CPU를 뺏김
우선순위 스케줄링 (Priority Scheduling)
우선순위가 높은 순으로 실행
(선점형/비선점형 모두 가능)
문제: 아사(Starvation)
우선순위가 낮은 프로세스는 영원히 실행 못 할 수도 있음
해결법: 에이징(Aging)
오래 기다리면 자동으로 우선순위를 점점 올려줌
다단계 큐 스케줄링 (Multilevel Queue)
프로세스를 우선순위별 여러 큐에 분류
예)
| 큐 | 우선순위 |
|---|---|
| 시스템 프로세스 | 가장 높음 |
| 대화형 프로세스 | 중간 |
| 배치 작업 | 낮음 |
큐 간 이동 불가 → 아사 위험
다단계 피드백 큐 (MLFQ)
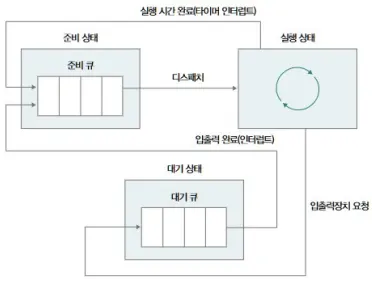
큐간 이동이 가능
OS가 얘는 CPU를 오래 쓰네? 하면 자동으로 아래 큐로 내려버림
- 짧은 작업(I/O-bound)은 높은 큐에서 빨리 처리
- 긴 작업(CPU-bound)은 자연스럽게 낮은 우선순위 큐로 이동
- 에이징도 쉽게 적용 가능
MLFQ는 현대 OS에서 가장 현실적인 방식
리눅스의 실제 CPU 스케줄링 — CFS
리눅스는 전통적 알고리즘 그대로 사용하지 않는다.
가장 대표적인 일반 프로세스 스케줄러는 CFS(Completely Fair Scheduler).
CFS의 핵심 개념: vruntime (가상 실행시간)
리눅스의 철학
프로세스들이 CPU 시간을 최대한 공평하게 가져가도록 하자
그래서 단순한 실행 시간(runtime)이 아니라,
우선순위(가중치, weight) 를 반영한 가상 실행시간(vruntime) 을 사용한다.
vruntime 증가 공식
vruntime 증가량 = 실제 실행시간 × (평균 가중치 / 프로세스 가중치)- 가중치가 큰(우선순위 높은) 프로세스는 vruntime이 천천히 증가
- vruntime이 가장 작은 프로세스를 먼저 실행
CFS 자료구조: RB Tree(레드-블랙 트리)
CFS는 모든 프로세스를 정렬된 트리(RB Tree) 에 넣고
vruntime이 가장 작은 프로세스를 상단에서 즉시 찾아 실행한다.
타임슬라이스도 가중치 기반
프로세스의 가중치가 높을수록 더 긴 타임슬라이스를 얻는다.
실제 확인 명령어
cat /proc/<PID>/sched출력 예:
se.vruntime: 4599515.302565
se.load.weight: 1048576
policy: SCHED_NORMAL
prio: 120Virtual Memory
물리 주소 vs 논리 주소, 그리고 MMU
물리 주소 (Physical Address)
- 실제 RAM 하드웨어 상의 주소
- 메모리 칩에서 몇 번지에 해당하는 진짜 주소
논리 주소 (Logical Address)
- 각 프로세스 입장에서 보는 주소
- 프로세스마다 0번지부터 시작하는 자기만의 주소 공간을 가짐
- 프로세스 A: 0 ~ …
- 프로세스 B: 0 ~ …
- 그래서 논리 주소는 서로 다른 프로세스끼리 겹쳐도 상관없음
MMU (Memory Management Unit)
- CPU ↔ 메모리 사이에 있는 주소 변환 하드웨어
- 하는 일:
- CPU가 내는 논리 주소 → 물리 주소로 변환
- 그림 느낌:
- CPU → (논리 주소) → MMU → (물리 주소) → 메모리
스와핑(Swapping)과 연속 메모리 할당
스와핑(Swapping)
- 실행 중이 아닌, 오래 쓰이지 않는 프로세스를 메모리 → 디스크의 스왑 영역으로 내보내는 것
- 메모리에서 내보내기: 스왑 아웃(Swap-out)
- 디스크에서 다시 불러오기: 스왑 인(Swap-in)
- 이렇게 해서 빈 공간을 만들고, 다른 프로세스를 올림
스왑 인될 때는 예전과 다른 물리 주소로 올라올 수 있음
→ 그래서 꼭 논리 주소 + MMU 구조가 필요
연속 메모리 할당 & 외부 단편화
연속 메모리 할당 (Contiguous Allocation)
- 프로세스를 연속된 물리 메모리에 통째로 할당
- 예: 프로세스 A(200MB) → 0~199MB 프로세스 B(300MB) → 200~499MB …
- 예: 프로세스 A(200MB) → 0~199MB 프로세스 B(300MB) → 200~499MB …
외부 단편화(External Fragmentation)
- 프로세스가 할당/해제 반복되면 중간중간 애매한 크기의 빈 공간이 생김
- 예:
- 빈 공간 총합 = 50MB
- 하지만 30MB + 20MB로 쪼개져 있으면 “50MB 프로세스”를 넣을 수 없음 → 낭비
연속 할당의 가장 큰 문제 = 외부 단편화 + 메모리보다 큰 프로세스 실행 불가
가상 메모리(Virtual Memory)의 목적
왜 가상 메모리?
- 외부 단편화 문제 해결
- 물리 메모리보다 큰 프로그램도 실행하고 싶다
가상 메모리 정의
- 프로세스 전체를 한 번에 올리지 않고, 일부만 메모리에 올려서 실행할 수 있게 하는 메모리 관리 기법
- 보조기억장치(디스크)의 일부를 메모리처럼 쓰는 개념
CPU 입장에서는 메모리가 훨씬 큰 것처럼 보임 → 가상 주소 공간
페이징(Paging) – 가상 메모리의 핵심
기본 개념
- 논리 주소 공간 → 일정 크기 블록으로 나눔: 페이지(Page)
- 물리 메모리 → 같은 크기 블록으로 나눔: 프레임(Frame)
- 페이지들을 프레임에 쪼개어 불연속적으로 배치
장점
- 프로세스를 조각 내서 아무 프레임에나 꽂을 수 있음
- 연속 할당이 아니기 때문에 외부 단편화 없음
- 필요한 페이지만 올려서 물리 메모리보다 큰 프로세스도 실행 가능
페이지 테이블(Page Table) & PTE
페이지가 여기저기 흩어져 있으니,
페이지 n번이 어느 프레임에 있는지를 기억할 구조가 필요함 → 페이지 테이블
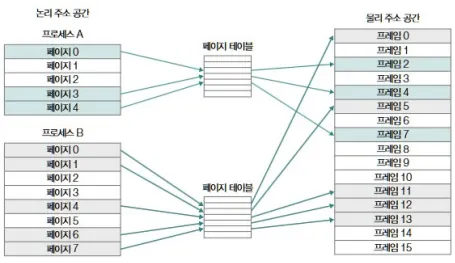
페이지 테이블
- 각 페이지 번호 → 프레임 번호 매핑 정보
- 프로세스마다 자기 페이지 테이블을 가짐
페이지 테이블 엔트리(PTE, Page Table Entry)에 들어가는 것들
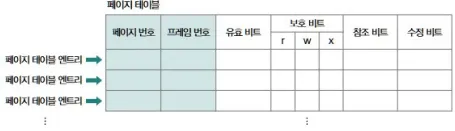
- 페이지 번호 / 프레임 번호
- 유효 비트(Valid Bit)
- 1: 해당 페이지가 메모리에 존재
- 0: 메모리에 없음(디스크에 있음) → 접근 시 페이지 폴트
- 보호 비트(Protection Bit)
- r / w / x 권한
- 예:
100→ 읽기만 가능111→ 읽기/쓰기/실행 모두 가능
- 참조 비트(Reference Bit)
- 최근에 참조(읽기/쓰기)된 적이 있는지
- 페이지 교체 알고리즘에서 사용됨
- 수정 비트(Modified Bit, Dirty Bit)
- 1: 이 페이지에 쓰기 발생함(내용 바뀜)
- 버려지기 전에 디스크에 쓰기 반영 필요
- 0: 읽기만 했거나 사용 안 함 → 디스크에 다시 쓸 필요 없음
- 1: 이 페이지에 쓰기 발생함(내용 바뀜)
페이지 폴트(Page Fault)와 처리 과정
페이지 폴트란?
- CPU가 접근한 페이지의 유효 비트가 0일 때 발생하는 예외
- CPU가 쓰려고 한 페이지가 메모리에 없음
처리 절차 (핵심만)
- 현재 작업 상태 백업
- 페이지 폴트 핸들러(예외 처리 루틴) 실행
- 디스크에서 해당 페이지를 메모리로 가져옴 (페이지 인)
- 페이지 테이블에서 유효 비트 1로 변경, 프레임 번호 기록
- 다시 해당 명령 재실행
메이저 / 마이너 페이지 폴트
- 메이저 페이지 폴트 (Major)
- 디스크 I/O를 실제로 해야 하는 경우
- 메모리에 페이지 없음 → 디스크에서 올려야 함 → 느림
- 마이너 페이지 폴트 (Minor)
- 물리 메모리에는 이미 있지만, 페이지 테이블 등에 아직 반영 안 된 경우
- 디스크 I/O 없이 처리 가능 → 상대적으로 덜 느림
TLB(Translation Lookaside Buffer)
문제점
- 페이지 테이블이 메모리에 있으면,
- 페이지 테이블 읽기 1번 + 실제 데이터 접근 1번 = 메모리 2번 접근
해결 TLB (페이지 테이블의 캐시)
- TLB 히트:
- TLB에 페이지 번호 → 프레임 번호 매핑이 있음
- 바로 프레임으로 가서 → 메모리 1번만 접근
- TLB 미스:
- TLB에 정보 없음
- 메모리에 있는 페이지 테이블 접근 → 프레임 번호 찾기 → 다시 메모리 접근 → 결국 2번 접근
TLB는 페이지 테이블 일부를 캐시해서 성능을 올리는 장치
PTBR & 계층적 페이징
PTBR (Page Table Base Register)
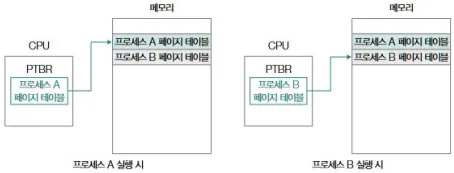
- 현재 실행 중인 프로세스의 페이지 테이블 시작 주소를 저장하는 레지스터
- 프로세스 전환 시(콘텍스트 스위치) PCB에 있던 PTBR 값이 교체됨
- CPU가 논리 주소를 물리 주소로 바꿀 때,
- PTBR + 페이지 번호로 해당 PTE 위치를 찾음
계층적 페이징 (다단계 페이지 테이블)
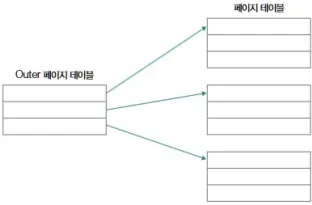
문제
- 페이지 테이블 크기가 너무 커서 그 자체가 메모리를 과도하게 먹는 상황 발생
해결
- 페이지 테이블을 다시 여러 페이지로 분할
- 그 페이지들을 가리키는 아우터 페이지 테이블(outer page table) 을 둔다
- CPU는:
- 1단계: outer 페이지 테이블에서 어느 페이지 테이블 페이지를 볼지 결정
- 2단계: 그 페이지 테이블의 PTE를 보고 프레임 번호 획득
이렇게 하면 전체 페이지 테이블 중 일부만 메모리에 두고, 나머지는 디스크에 둘 수 있음
페이징 주소 체계: ⟨페이지 번호, 변위⟩
논리 주소 = ⟨페이지 번호, 변위(offset)⟩
- 페이지 번호: 몇 번째 페이지인지
- 변위: 그 페이지 안에서 얼마나 떨어져 있는지
MMU 변환
논리 ⟨페이지 번호, 변위⟩
→ 페이지 테이블 조회 → ⟨프레임 번호, 변위⟩
→ 물리 주소 = (프레임 시작 번지 + 변위)
예시
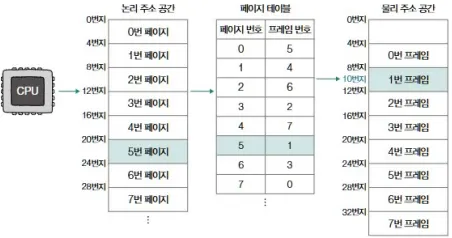
- 페이지 크기 = 4개의 주소
- 5번 페이지가 1번 프레임에 있음
- 논리 주소 = ⟨5, 2⟩
- 1번 프레임이 물리 주소 8번지부터 시작이라면 → 실제 물리 주소 = 8 + 2 = 10번지
- 1번 프레임이 물리 주소 8번지부터 시작이라면 → 실제 물리 주소 = 8 + 2 = 10번지
요구 페이징(Demand Paging)
요구 페이징(Demand Paging)
- 프로세스 전체 페이지를 처음부터 다 올리는 게 아니라, 필요해질 때(접근될 때)마다 올리는 방식
- 순수 요구 페이징(pure demand paging):
- 시작할 때는 아무 페이지도 안 올림
- 첫 명령부터 계속 페이지 폴트 → 필요한 것들만 차곡차곡 적재
- 어느 정도 적재되고 나면 폴트 빈도 감소
페이지 교체 알고리즘(Page Replacement)
메모리가 꽉 찬 상태에서 새로운 페이지를 올려야 할 때
- 어떤 페이지를 내보낼지 결정하는 알고리즘
성능 기준
- 페이지 폴트 발생 횟수가 적을수록 좋은 알고리즘
FIFO (First-In First-Out)
- 가장 먼저 메모리에 들어온 페이지부터 내보냄
장점
- 아이디어/구현 단순
단점
- 자주 쓰이는 늙은 페이지를 내쫓을 위험 큼
OPT (Optimal)
- 앞으로 가장 오랫동안 사용되지 않을 페이지를 내보내는 알고리즘
장점
- 이론적으로 최소 페이지 폴트 보장
단점
- 미래를 알아야 해서 현실에서는 구현 불가능 → 비교용 기준
LRU (Least Recently Used)
- 최근에 가장 오랫동안 쓰이지 않은 페이지를 교체
- 미래 사용을 알 수 없으니
- 과거 사용 패턴(최근 참조 여부)을 근거로 추정하는 방식
- 실제 OS에서 매우 많이 쓰이는 기본 아이디어 (LRU를 근사하는 여러 변형 알고리즘 존재)
Thrashing (스래싱)
- 페이지 교체가 너무 자주 일어나서 실행보다 페이징에 시간을 더 많이 쓰는 상태
- 증상
- CPU 사용률은 낮고,
- 디스크 I/O만 미친 듯이 발생
File System
파일(File)과 메타데이터(Metadata)
파일은 이름 + 내용 + 속성(메타데이터)으로 구성된다.
파일 속성 예:
- 파일 이름
- 크기
- 파일 타입(예: .txt, .jpg)
- 접근 권한 (rwx)
- 생성 시간, 수정 시간, 접근 시간
- 소유자 UID/GID
- 디스크 상의 위치 정보
운영체제는 파일을 직접 다루지 않고 시스템 콜을 통해서만 접근하도록 강제한다.
예: open(), read(), write(), close()
파일 디스크립터 (File Descriptor)
프로세스는 파일을 열면 정수 번호(fd) 를 하나 받는다.
예:
- 0 = 표준 입력(STDIN)
- 1 = 표준 출력(STDOUT)
- 2 = 표준 에러(STDERR)
- 3 이상 = 프로세스가 연 파일
즉, 파일 디스크립터는 프로세스가 현재 열어둔 파일 목록의 인덱스 역할을 한다.
int fd = open("test.txt", O_WRONLY);
write(fd, "Hello", 5);
close(fd);파일 뿐 아니라 소켓, 파이프도 파일 디스크립터로 식별된다.
→ 리눅스에서는 모든 것은 파일이다 모델.
디렉터리(Directory) = 파일 목록 테이블
운영체제에서 디렉터리는 사실상 특별한 파일이다.
내부에는 다음 정보가 들어간다
- 파일/디렉터리 이름
- 해당 파일의 위치 정보(아이노드 번호 등)
즉, 디렉터리는 일종의 파일 목록 테이블이며,
각 행(row)을 디렉터리 엔트리(Directory Entry) 라고 부른다.
예:
home/
├── minchul/
│ ├── a.sh
│ ├── b.c
│ └── c.tar
└── guest/루트 디렉터리 /, 하위 폴더로 이어지는 구조는 트리 자료구조 그 자체이다.
파일 저장 단위: 블록(Block)
운영체제는 파일을 디스크에 저장할 때 바이트 단위로 저장하지 않고,
블록(보통 4KB) 단위로 관리한다.
파일이 여러 블록에 흩어져 있어도
운영체제가 관리하도록 추상화되어 있다.
파일 할당 방식 (Allocation Method)
디스크에 파일을 저장하는 방식은 파일 시스템 종류에 따라 다르지만,
대표 방식은 아래 세 가지다.
연속 할당 (Contiguous Allocation)
- 파일을 연속된 블록에 저장
- 장점: 빠른 접근(Seek 최소)
- 단점: 외부 단편화, 파일 크기 증가 시 어려움
연결 할당 (Linked Allocation)
- 각 블록에 다음 블록 번호를 저장 → 리스트 형태로 저장
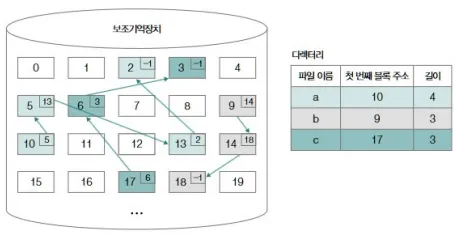
- 장점: 외부 단편화 해결
- 단점: 임의 접근(Random Access)이 느림(앞에서부터 타고 가야 함)
색인 할당 (Indexed Allocation)
특별한 블록(= 색인 블록, Inode) 하나에
모든 블록 주소를 저장하는 방식.
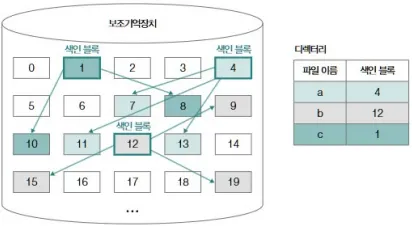
- 장점: 빠른 랜덤 접근
- 단점: 큰 파일의 경우 색인 블록만으로 부족할 수 있음 → 다중 색인 구조 필요(EXT 파일 시스템 등)
파일 시스템 종류 예시
운영체제마다 다른 파일 시스템을 사용한다.
Windows
- NTFS
- ReFS
Linux
- EXT2/EXT3/EXT4
- XFS
- ZFS 등
macOS
- APFS
파일 시스템은 파일 크기 한계, 성능, 안정성 등이 모두 다르다.
파티션(Partition)
하나의 디스크를 여러 구역으로 나누어
각 구역마다 다른 파일 시스템을 적용할 수 있다.
디스크 파티션 예:
- C: → NTFS
- D: → EXT4
- E: → XFS
이 과정이 바로 파티셔닝(partitioning).
아이노드(Inode) 기반 파일 시스템 (EXT 계열)
아이노드(Inode) = 파일의 핵심 메타데이터
아이노드가 저장하는 정보
- 파일 타입
- 소유자
- 권한
- 크기
- 생성/수정 시간
- 데이터 블록 주소 목록
- 링크 수(link count)
단, 파일 이름은 아이노드에 없음
→ 파일 이름은 디렉터리 엔트리에 저장됨
→ 디렉터리 엔트리가 이름 → 아이노드 번호를 매핑해줌
EXT4 구조:
- 슈퍼블록
- 블록 그룹
- 블록 비트맵
- 아이노드 비트맵
- 아이노드 테이블
- 데이터 블록
중요 포인트
- 아이노드가 다 차면 데이터 블록이 남아 있어도 파일을 더 만들 수 없다.
하드 링크 vs 심볼릭 링크
하드 링크
- 같은 아이노드를 공유하는 또 다른 이름
- 원본을 삭제해도 데이터는 살아 있음 (링크 카운트가 0이 되는 순간 삭제)
심볼릭 링크(바로가기)
- 원본 파일의 경로만 저장하는 파일
- 원본이 삭제되면 링크는 깨짐
마운트(Mount)
다른 저장장치의 파일 시스템을
내 컴퓨터의 디렉터리 트리에 편입시키는 작업
예
# mount -t ext4 -o ro /dev/sda /mnt/test→ /dev/sda에 있는 EXT4 파일 시스템을
→ /mnt/test 경로에 연결
이제 /mnt/test 로 진입하면
USB/외장하드 안의 파일을 내 로컬처럼 사용할 수 있음.
