section 1 : 데이터 전처리
세 개의 라이브러리를 통해서 데이터 세트를 가져온 다.
데이터에는 누락된 값이 있고 실수형이 아닌 문자열 값을 인코딩해준다.
그리고 머신러닝의 기본인 데이터 세트를 훈련 세트와 테스트 세트로 분할한다.
1. 라이브러리
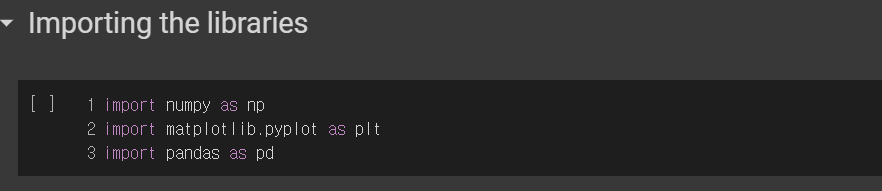
- numpy는 배열을 가지고 작업할 수 있게 해준다.
- matplotlib는 차트와 그래프를 사용할 수 있게 해준다.
- pandas는 데이터 세트를 불러오고 특징 행렬과 종속 변수 벡터를 생성한다.
as를 통해 간단하게 축소된 말로 사용할 수 있다.
matplotlib를 불러오고, pyplot도 불러온다
pyplot라는 모듈은 차트를 만들어준다.
2. 데이터 세트 가져오기
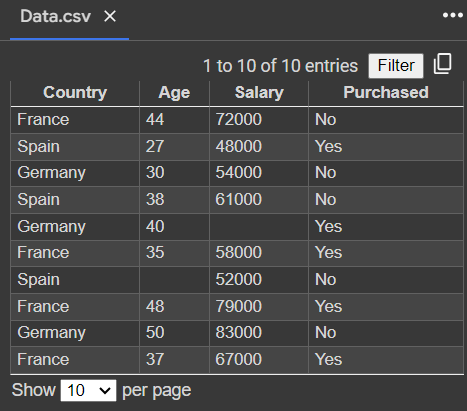
이 데이터를 가져올 것인데, 문자열이 있고 누락된 데이터가 있다.
일단 2번에서는 가져오는 것을 배워본다.
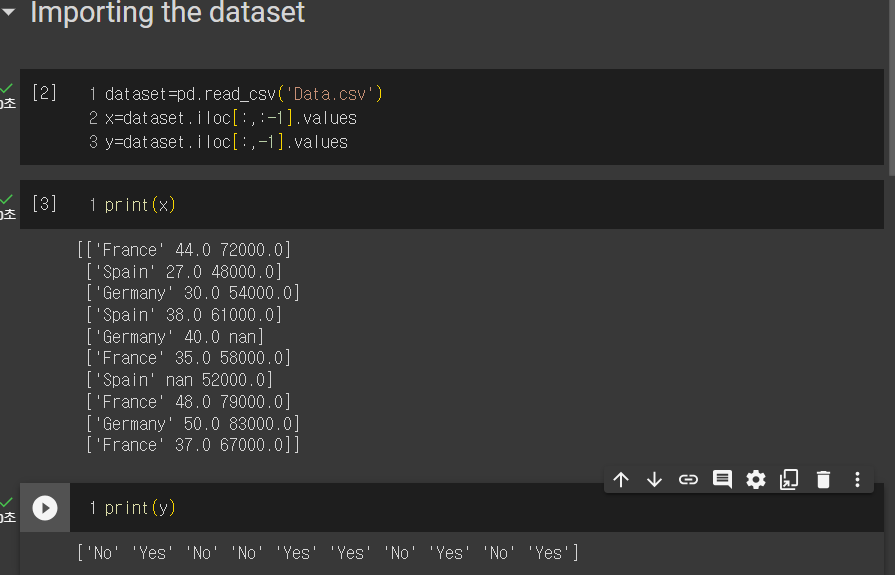
- dataset이라는 변수에 데이터 프레임을 생성해주는 라이브러리인 pandas를 사용한다.
그리고 read_csv라는 함수를 통해 기존의 데이터 값인 Data.csv를 넣어준다.
x=특징 행렬이고 y는 종속 변수 벡터이다.
머신러닝 모델을 훈련시킬 어떤 데이터 세트든지 같은 요소를 가지고 있는데, 특징과 종속 변수 벡터이다.
특징은 종속 변수를 예측할 때 사용될 열들이고, 종속 변수는 마지막에 있는 열이다.
주로 데이터 셋의 첫 번쨰 열에 특징이 분리되어 있고, 종속 변수는 데이터 세트의 마지막열에 있다.
특징 행렬은 첫 열에서 3번째 열은 x로, 종속 변수 벡터인 마지막 4열은 y로 표현한다.
x=dataset.iloc[:,:-1].values
- dataset으로 가져오고, pandas 함수 중 하나인 {iloc}를 사용한다.
- iloc는 locate index를 의하는데, 추출할 열들의 인덱스를 가져온다.
- []안에 : 을 볼 수 있는데, 이것은 모든 행을 가져온다.
- []안의 두 번째 :는 열을 의미하는데, -1은 마지막 열을 의미하므로 처음부터 마지막 열 직전까지 가지고 온다.
- 마지막으로 values를 붙여주는데, 이는 모든 행의 모든 값을 가져오겠다는 의미이다.
y=dataset.iloc[:,-1].values
y도 x처럼 다 동일하지만 마지막 열만 가지고 와야한다.
그래서 두 번째 :에서는 마지막 열인 -1만 가지고 온다.
3. 누락된 데이터 처리하기
데이터 세트 중 누락된 부분이 있다.
누락된 데이터를 처리하는 방법 중에는 그 행을 지우고 무시하거나, 평균값으로 그 값을 채워주는 것이다.
여기서는 후자의 방식을 사용한다.
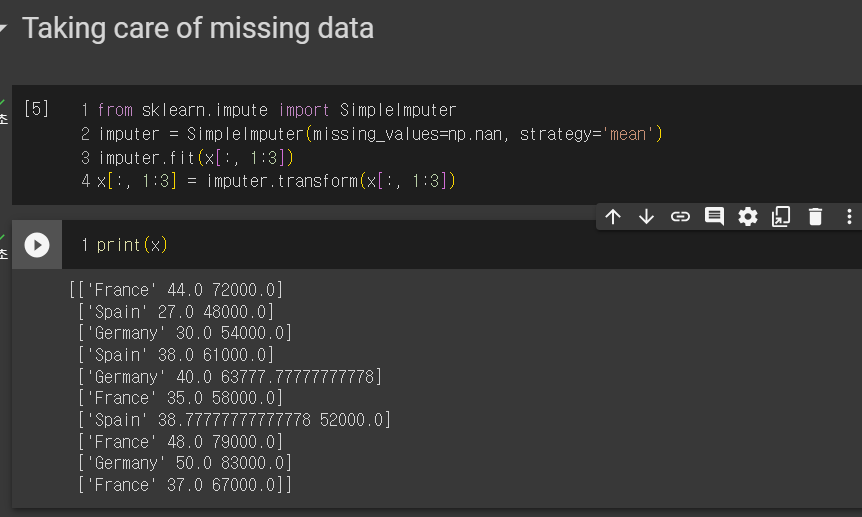
여기서는 sklearn이라는 데이터 과학 라이브러리를 사용한다.
sklearn에서 simpleimputer이라는 클래스를 불러오고, 이는 특징 행렬에만 적용되는 특징을 가진다.
from sklearn.impute import SimpleImputer
sklearn을 불러주고 simpleimputer을 사용하려면 impute라는 모델도 가져오게 해준다.
imputer=SimpleImputer(missing_values=np.nan,strategy='mean')
빈 값인 missing_values에 평균값인 mean을 넣는다.
특징 행렬 내 모든 결측치를 특징 자체의 평균값으로 대체된다.
imputer.fit(x[:,1:3])
문자열은 제외되고 숫자열만 포함된다. 모든 행에서 1~2열만 그 열에 평균값이 누락된 곳에 들어간다.
4. 범주형 데이터 인코딩
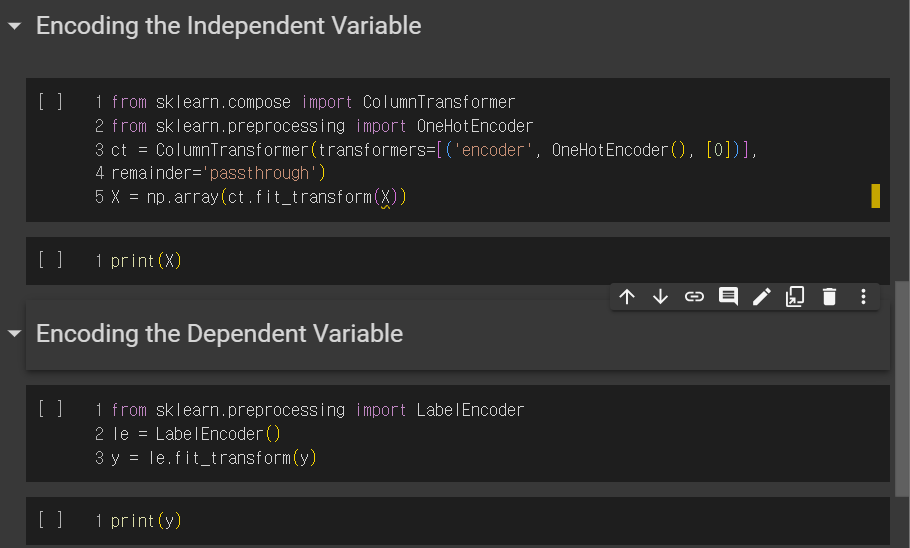
contry에는 세 개의 나라가 있는데, 이는 문자열로 되어있다. 문자열로 되어있으면, 까다로운 경우가 많아서 실수로 바꿔줘야한다.
0,1,2 이렇게 바꾸면, 우선순위가 생기는 것 같으므로 0 0 0, 0 1 0 이렇게 이진으로 나타내자
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
onehot 인코딩하기 위해 2개의 라이브러리를 import해야한다.
ct=ColumnTransformer(transformer=, remainder=)
transformer에서는 무엇을 바꿀 것인가
remainder은 유지되길 원하는 열을 지정
ct=ColumnTransformer(transformer=[('encoder',OneHotEncoder(),[0])], remainder=)
transformer에는 세 가지 인자가 들어간다.
첫 번째, 어떤 변환을 적용할 것인가 > 인코딩
두 번째, 어떤 종류의 인코딩을 적용할 것인가 > One Hot 인코딩
세 번째, 어떤 열의 인덱스를 인코딩하고 싶은가 > country열
ct=ColumnTransformer(transformer=[('encoder',OneHotEncoder(),[0])], remainder='passthrough'
remainder에서는 바뀌지말고 유지되길 원함
x=np.array(ct.fit_transform(x))
x를 업데이트 해준다.
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
y=le.fit_transform(y)
y를 인코딩할 때, 종속변수이므로 LabelEncoder 라이브러리를 사용한다.
그외엔 위와 동일하다.
5. 훈련 세트와 테스트 세트로 분할하기
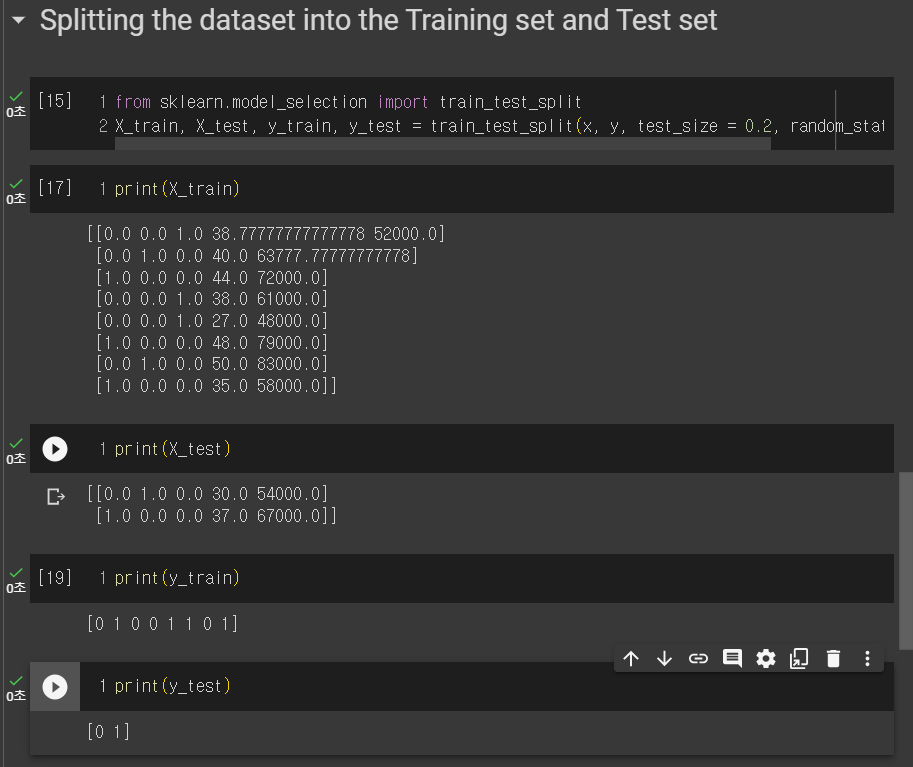
from sklearn.model_selection import train_test_split
4개로 나눠서 쓰기위해 라이브러리를 사용한다.
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=1)
훈련과 시험은 8:2로 나누기 위해 test_size에 0.2의 값을 넣었고, 무작위성을 위해 random_state=1을 넣었다.
6. 기능 확장
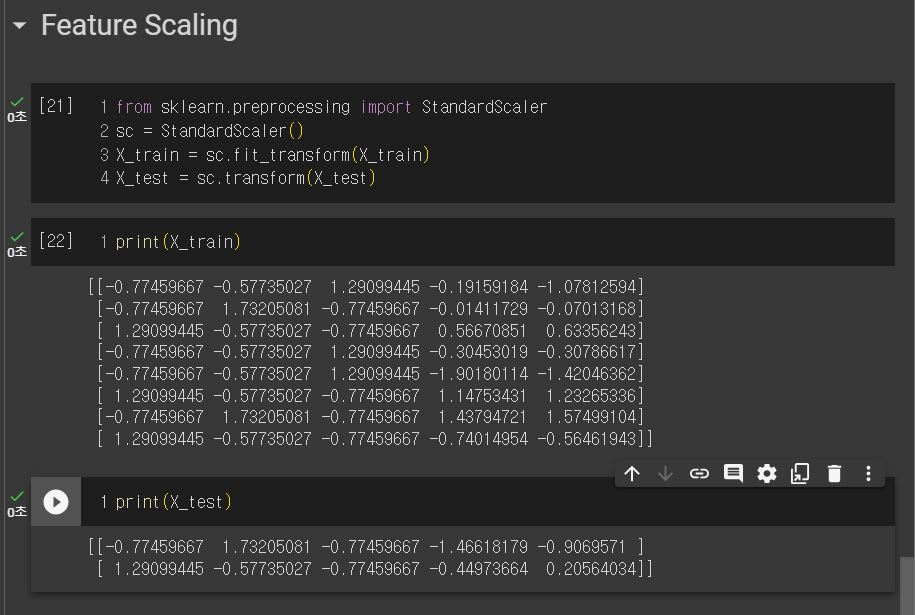
피처 스케일링은 모든 변수나 특징을 스케일링하는 도구인데, 모든 값이 같은 단위가 되게끔하고 특징은 다른 하나를 지배해서 머신러닝 모델에 의해 무시되는 일을 막기 위한 것이다. ..?
특성들 중 표준화, 정규화가 있는데, 표준화는 언제나 작동하는 기법이고, 정규화는 대부분의 특성이 정규 분포를 따르는 특정 상황에 권장되는 기법이다.
모든 특성 값을 같은 범위에 놓기 위함이다.
모든 변수가 같은 크기가 되게끔..
from sklearn.preprocessing import StandardScaler
X_train[:,3:]=sc.fit_transform(X_train[:,3:])
X_test[:,3:]=sc.fit_transform(X_test[:,3:])

좋은 글이네요. 공유해주셔서 감사합니다.