다중선형회귀모델을 만드는 방법은
1. All in
2. Backward 제거
3. Forward 제거
4. 왕복 소거법
5. 점수 비교
여기서는 2번의 방식을 사용하고, 각 이론을 꼼꼼히 공부해야 할 것이다.
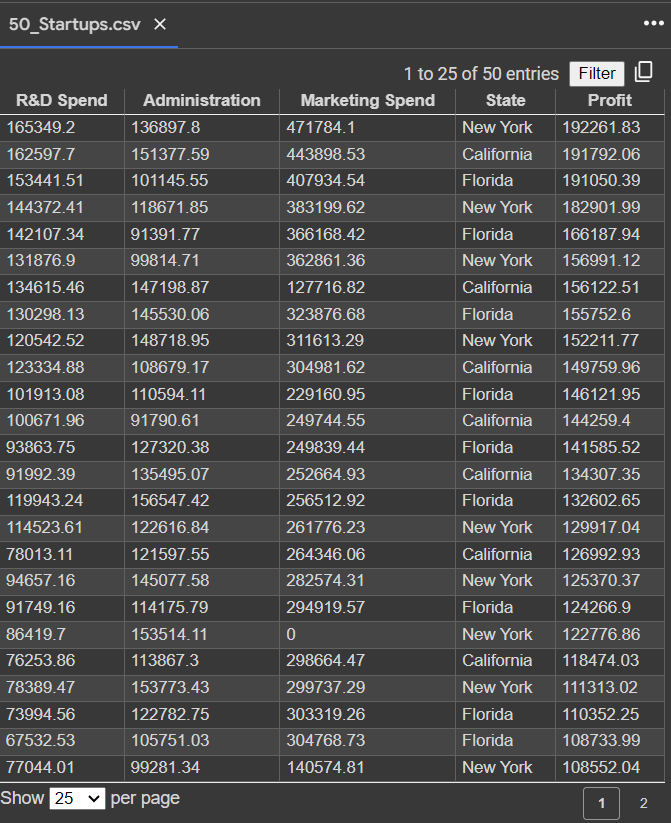
데이터들은 이런 모습을 가지고 State는 이진으로 표현해야한다.
1. 라이브러리 가져오기
2. 데이터 셋 가져오기
3. 문자열 Encoding
4. Train, Test set 분리
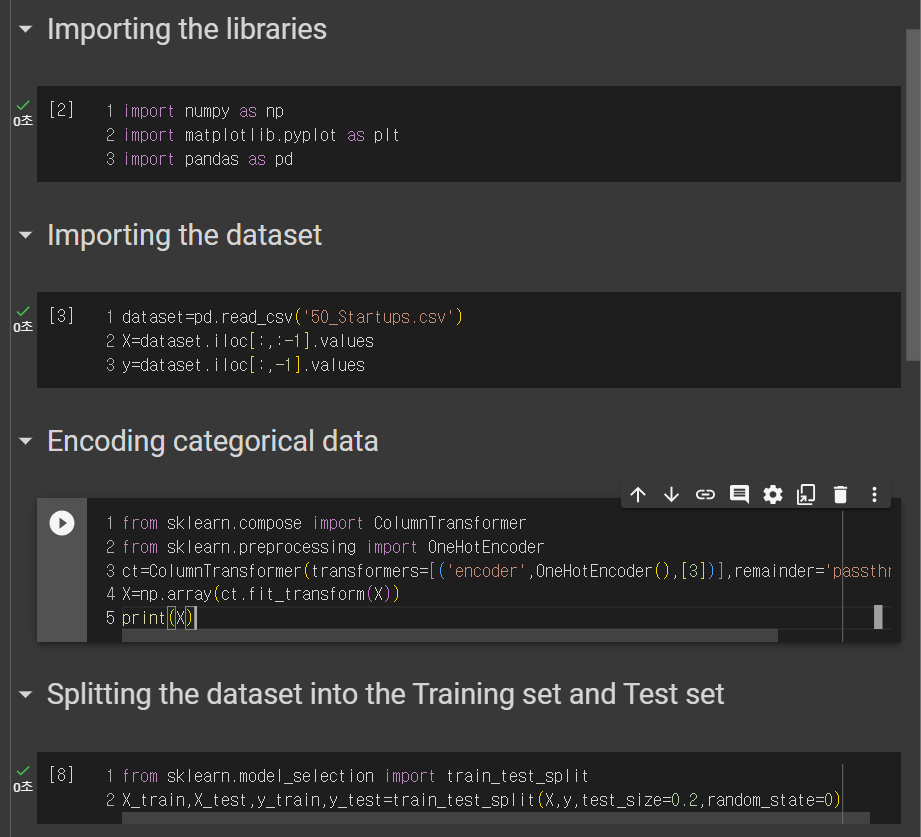
앞의 과정과 모두 동일하다.
단, OneHotEncoding하는 방법은 낯설어서 기억이 나지 않았다.
다시 반복해야겠다.
5. 선형 모델 Train하기
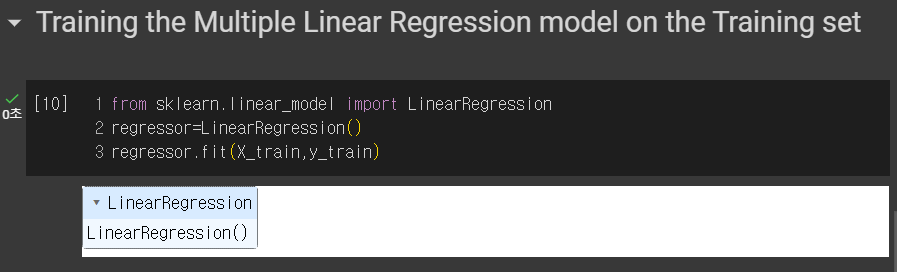
from sklearn.linear_model import LinearRegression
다중 선형 회귀 모델도 선형이므로 바로 전과 동일하게 LinearRegression 라이브러리를 가져온다.
regressor=LinearRegression()
인자 만들어주기!
regressor.fit(X_train,y_train)
모델을 주어진 데이터로 훈련시키는 과정!
6. Test 셋 예측, 출력
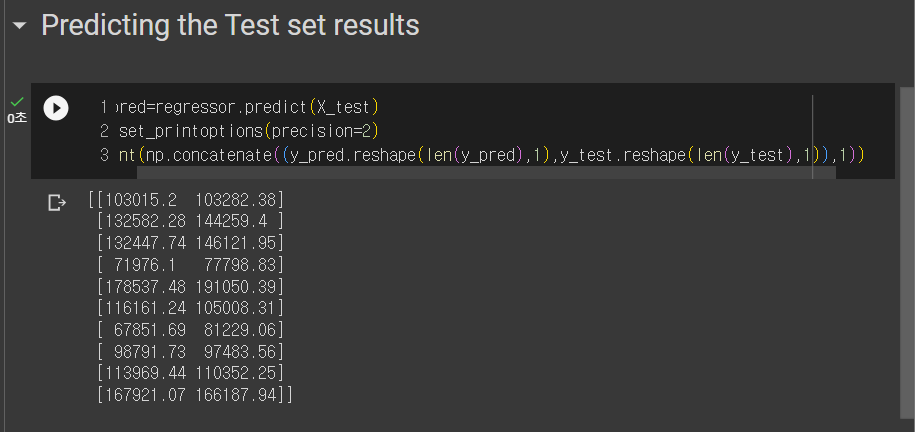
y_pred=regressor.predict(X_test)
바로 앞에서 X_train 데이터를 가지고 훈련한 이 모델이 X_test라는 데이터를 가지고 예측한 결과를 Y_pred로 만들었다.
즉, Y_pred는 이익,수익이다.
np.set_printoptions(precision=2)
이것은 소수점 2자리까지 나타내는 함수인다. 전역함수느낌??
한 번 처리하면 계속 영향을 끼치는 것 같다.
print(np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1))
두 가지 배열이 있고, 두 가지는 가로로 되어있고 따로 되어있다.
이것은 세로로 바꾸고, 합쳐보자
일단은, X_test의 예측 결과를 세로로 바꾼다.
세로나 가로로 바꾸기 위해 reshape함수를 사용하고, 길이는 원래의 길이를 사용하기때문에 len을 사용하면 된다. 그리고 뒤에 1은 그냥 붙여주자.
X_test로 예측한 결과와 실제 결과를 비교하기 위해선 y_test도 세로로 바꿔줘야 한다.
그래서 두 번째에는 y_test를 가지고 똑같이 진행했다.
그리고 합쳐주기 위해선 numpy(배열관련 라이브러리)의 concatenate 메소드를 사용하고 뒤에 1을 붙여준다.
