서포트 벡터 머신이란, 전과 다르게 폭이 있다고 생각하자.
한 선에서 양옆으로 폭이 있는데 그 사이에 있는 점들은 에러여도 신경쓰지 말자이다.
그러면 폭 외부에 있는 점들은 어떨까?
외부의 점과 폭의 거리들의 합이 최소가 되기를 원하게끔 만들어주자.
즉, 튜브 밖의 모든 오류들에 신경을 써야한다.
1. 라이브러리 가져오기
2. 데이터 전처리
모두 동일하다.
3. 피처 스케일링
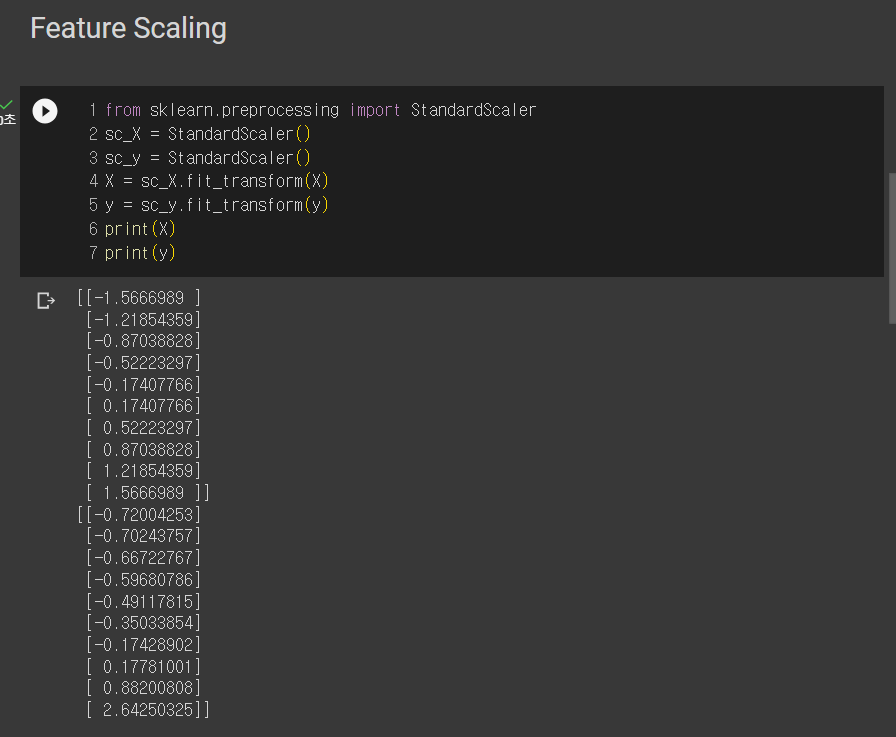
데이터 중 값이 너무 큰 값이 있으므로 피처 스케일링을 통해 해당 값 사이에 값들이 있게처리한다.
그리고 이값들은 나중에 다시 출력하거나 반환할때 inverse_transform을 거쳐야 한다.
from sklearn.preprocessing import StandardScaler
피처 스케일링을 위한 라이브러리.. 이것은 그냥 외우자
sc_X=StandardScaler()
sc_y=StandardScaler()
X,y는 각각 따로따로 만들어줘야한다.
X=sc_X.fit_transform(X)
y=sc_y.fit_transform(y)
또 따로 각각 기존의 데이터를 변환시켜주자.
4. SVR 모델 생성 및 훈련
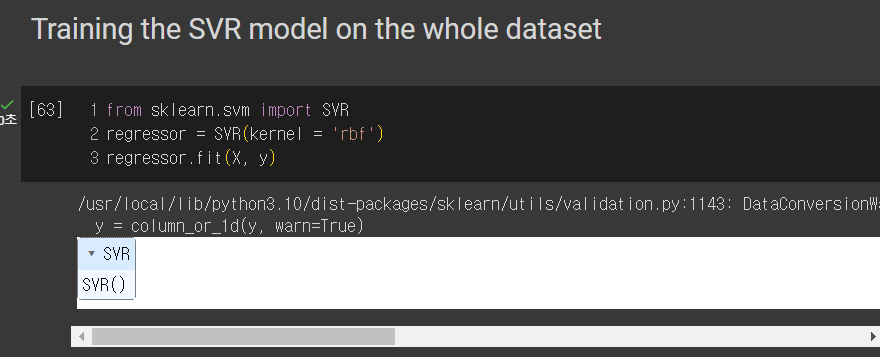
from sklearn.svm import SVR
SVR 라이브러리를 가져오기!
regressor=SVR(kernel='rbf')
regressor.fit(X,y)
regressor은 SVR 모델이다. SVR 모델 중 rbf를 사용하기 때문에 저런식으로 나타내자
그리고 피처 스케일링을 거친 데이터인 X,y로 훈련시키자
5. 결과 예측

6. 시각화

plt.scatter(sc_X.inverse_transform(X),sc_y.inverse_transform(y),color='red')
빨간 점을 칠해야 한다.
X는 기존의 피쳐 스케일링되었다.
다시 원래대로 하기 위해선 inverse를 사용해야하고, y값도 마찬가지이다.
plt.plot(sc_X.inverse_transform(X),sc_y.inverse_transform(regressor.predict(X).reshape(-1,1)),color='blue')
추세선을 그릴 때, X는 동일!
하지만 y가 달라진다.
X에 대한 예측 값이 데이터로 들어오게끔하자
